Python轻松模拟淘宝账号登录指南
模拟淘宝账号登录是很多爬虫爱好者常见的需求。本文分享使用Python requests库实现这一过程,详细拆解淘宝登录复杂机制,包括参数收集、滑块处理、token交换和单点登录原理。文章提供完整代码示例,帮助小白快速上手并成功登录,轻松获取淘宝数据。
模拟淘宝账号登录对于希望通过自动化脚本处理商品数据或者订单信息的用户来说,常常是个绕不开的技术点。很多初学者可能会觉得淘宝的验证体系过于严密,但其实只要掌握核心流程和参数逻辑,就能用简单工具实现。本文将一步步带你理清淘宝登录的整个链条,从准备工作到代码落地,再到结果验证,让你轻松搞定。
理解淘宝登录的整体流程
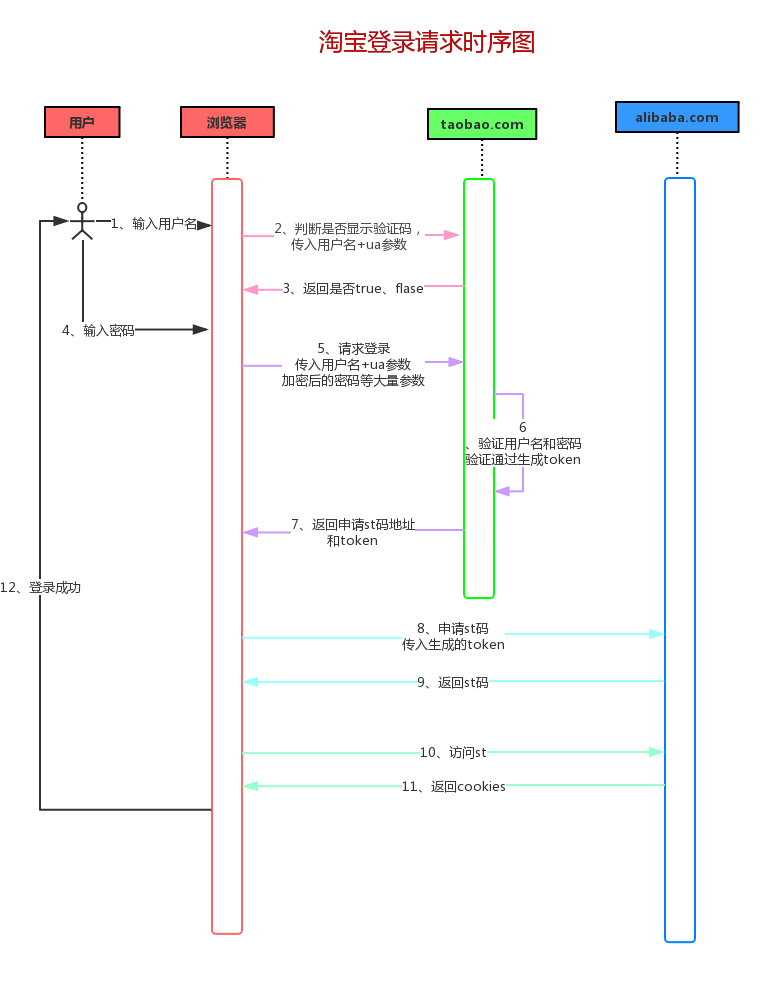
淘宝的登录设计远比单纯输入账号密码复杂得多,这得益于其庞大的生态系统和安全考量。用户从浏览器发起请求开始,整个过程涉及多次交互:先是验证基本信息,接着处理敏感操作,最后通过母公司接口完成授权。理解这些步骤能避免代码执行时遇到莫名其妙的失败。
简单来说,登录首先需要向淘宝核心域发送请求来判断是否触发额外防护。如果没有问题,就进入用户名密码阶段。验证通过后,系统会生成一个临时令牌,浏览器再带着这个令牌去另一个域名交换最终的登录凭证。这种结构本质上是为了实现不同业务线之间的无缝连接,避免用户重复输入信息。
整个流程虽然看起来繁琐,但原理其实很清晰:每个环节都有明确的入参和返回结果。通过抓取浏览器请求时的参数,你就能还原出正确的操作顺序。记住,淘宝对不同设备和IP的限制会体现在这些参数里,所以准备阶段准备好这些数据至关重要。
准备阶段:收集必要的参数和环境
开始之前,你需要准备Python环境和一些基础工具。确保安装了requests库,这是实现模拟登录最常用的HTTP客户端。登录流程中,浏览器会发送各种头信息和加密数据,这些都需要从真实浏览器抓取后复制过来。
关键参数包括用户名、加密后的密码,以及一个叫UA的浏览器特征字符串。它不仅包含设备信息,还融入了时间戳、屏幕分辨率等随机元素。收集这些参数时,最可靠的方法是打开开发者工具,找到登录表单的请求链接,然后复制出所有POST参数。你可以把这些数据保存为变量,在代码中重复使用。
此外,还需要注意淘宝对滑动验证码的处理。如果你的请求被标记为需要验证,那必须配合验证码识别功能。有了这些准备,接下来就能顺利进入模拟阶段。记住,参数收集一次就好,以后执行时直接调用,避免每次都从浏览器抓取。

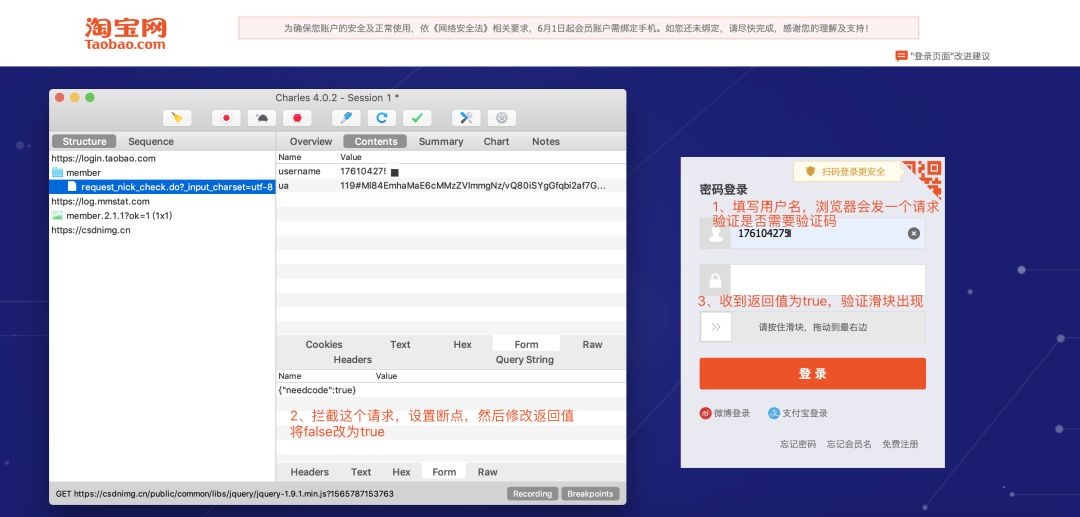
第一步:判断并处理滑块验证码
登录第一步通常是向淘宝发送一个请求,包含用户名和UA参数。这个请求的主要目的是检查是否需要展示滑块或类似防护。如果返回结果显示需要验证,就必须解决这个问题。请求代码看起来像这样:
import requests
url = "https://login.taobao.com/api/login/check" # 实际请求链接需从浏览器复制
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36'
}
data = {
'username': '你的用户名',
'ua': '你的收集的UA字符串'
}
response = requests.post(url, headers=headers, data=data)
print(response.json()) # 检查是否需要验证码实际操作中,这个URL和参数需要根据最新版本调整,但核心逻辑不变。返回结果如果是真,就表明需要验证码处理。遇到这种情况,可以调用专业验证码识别接口来获取解锁代码。有了这些方案后,滑块问题就迎刃而解,避免了登录中断。
这个判断环节其实很智能,它会结合IP地址和设备特征来决定是否触发防护。所以如果你使用固定IP或者同一设备多次操作,偶尔出现验证的情况很正常。解决办法就是及时识别验证码,并用正确的值替换空字段继续执行。
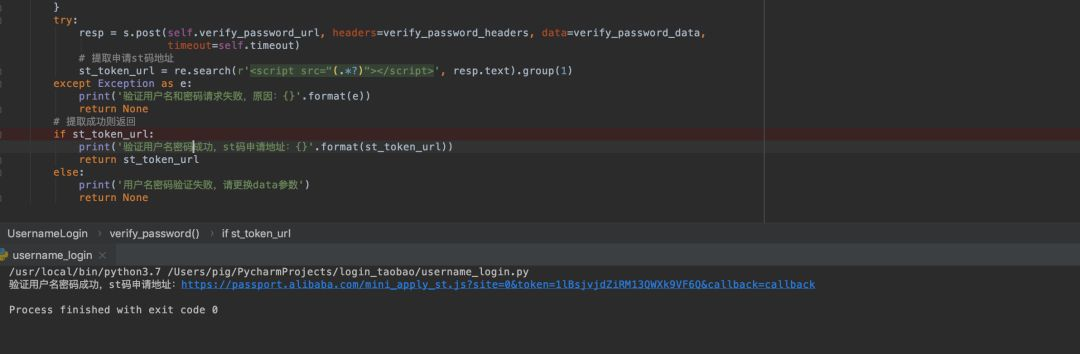
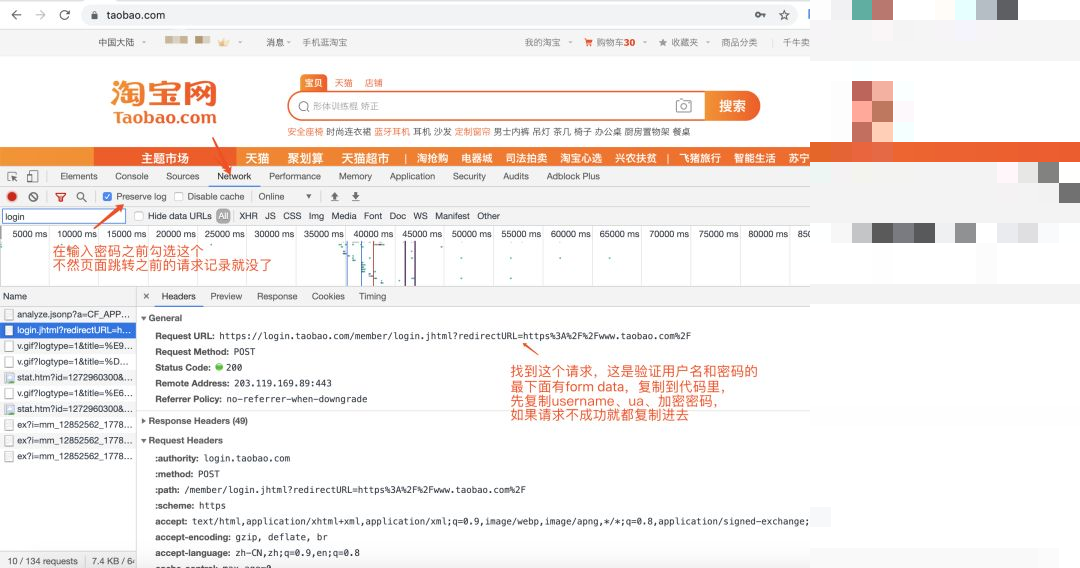
第二步:验证用户名密码并获取token
成功绕过滑块后,进入密码验证阶段。这个步骤会发送大量参数到登录接口,包括加密密码和其他几十个字段。参数大多来自浏览器表单,你需要把它们复制粘贴进去,确保格式一致。
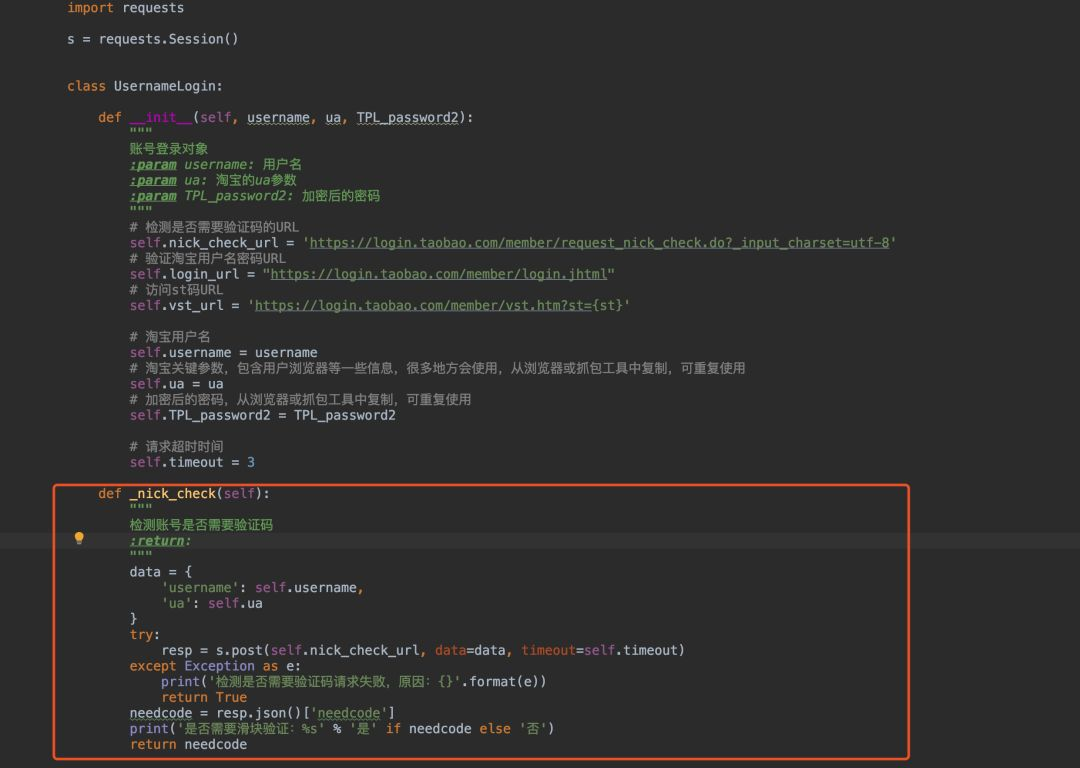
以下是简化后的验证请求示例,实际中需将所有参数一一对应:
url = "https://login.taobao.com/api/login" # 登录接口
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36'
}
data = {
'username': '你的用户名',
'password': '加密后的密码',
'ua': '你的UA字符串',
# 其他30多个参数在此处添加,确保完整
}
response = requests.post(url, headers=headers, data=data)
token = response.json().get('token') # 获取token验证成功后,接口会返回一个token,这个东西就像登录的钥匙,后面会用来换取最终凭证。整个过程通常在几秒内完成,但如果出现错误,可以尝试调整某个参数或者重新抓取最新版本。
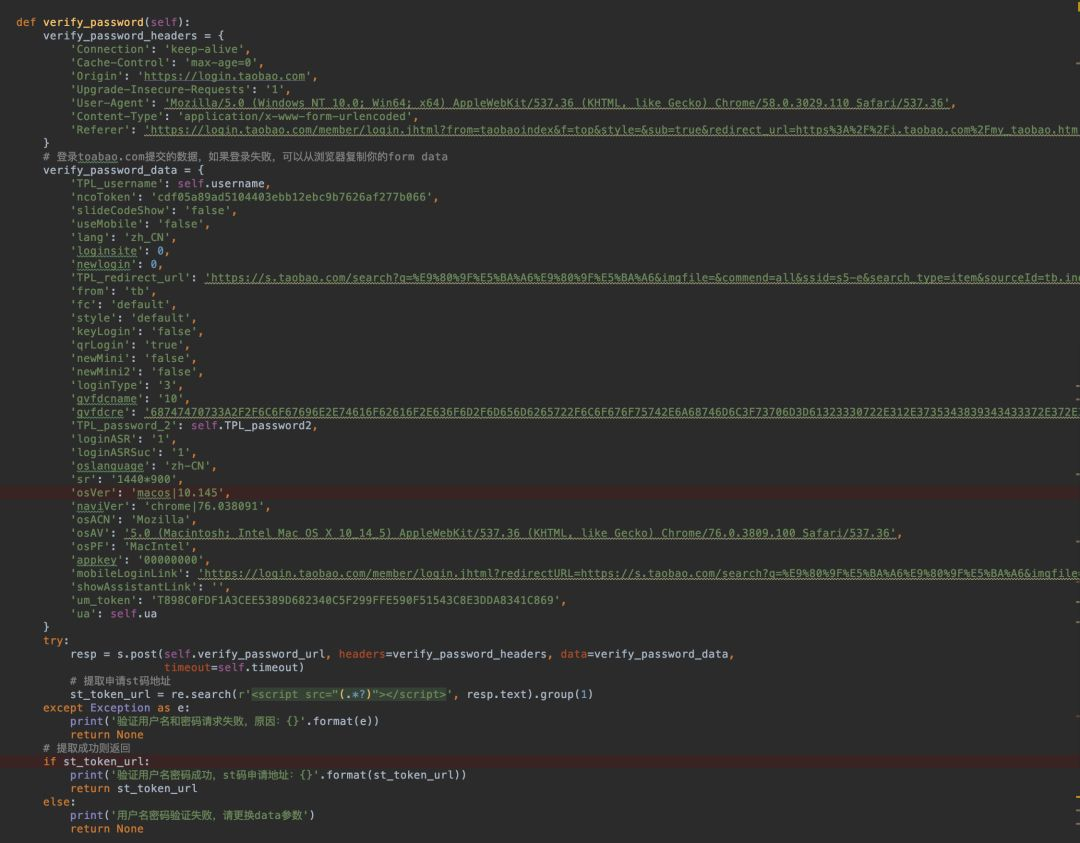
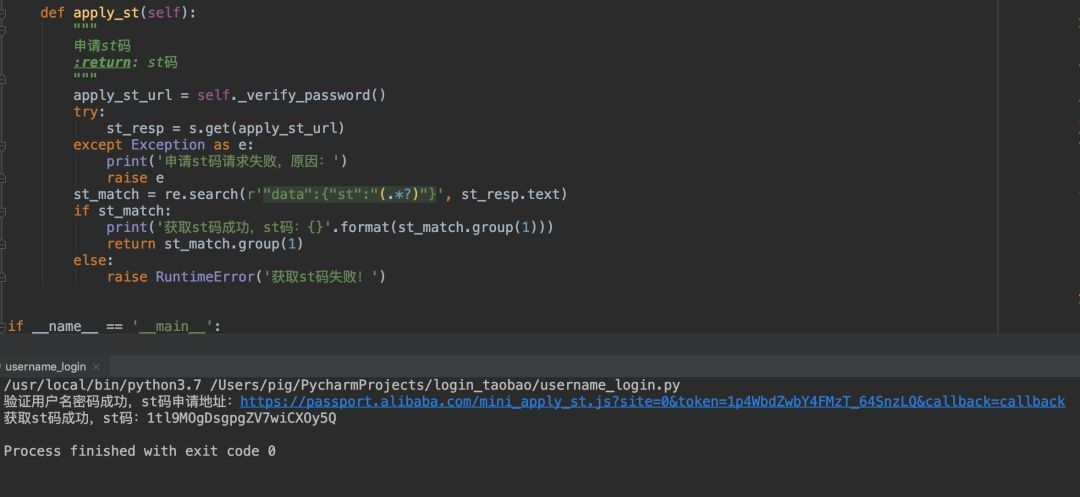
第三步:利用token交换st码实现单点登录
拿到token后,浏览器需要拿着它去另一个域名交换最终的登录凭证。这个步骤是淘宝生态连接的关键,通过它可以让淘宝和天猫等业务共享登录状态,而不需要重复验证。
代码实现很简单:
url = "https://alibaba.com/api/login/exchange" # 实际交换接口
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36'}
data = {'token': token}
response = requests.post(url, headers=headers, data=data)
st = response.json().get('st') # 获取st码这里st码就是最终的登录标识,换取后就能在浏览器中永久保存。理解这个单点登录机制后,你会发现为什么淘宝登录看起来需要多步:它本质上是母公司统一授权的结果。

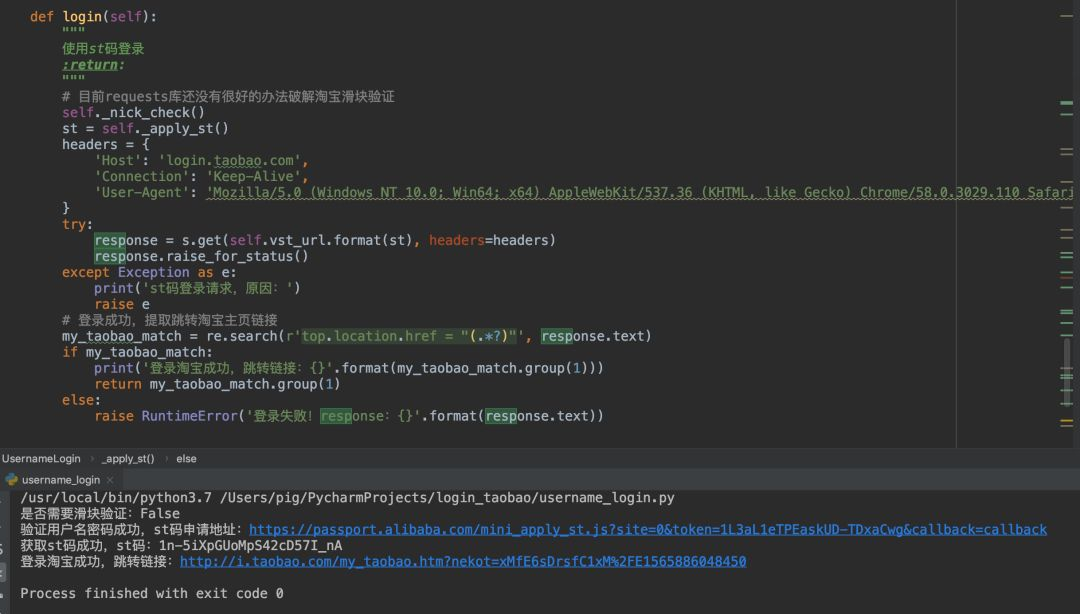
第四步:使用st码登录并验证成功
有了st码,你就可以直接获取登录后的cookies。这些cookies会让浏览器自动携带身份信息访问淘宝页面。
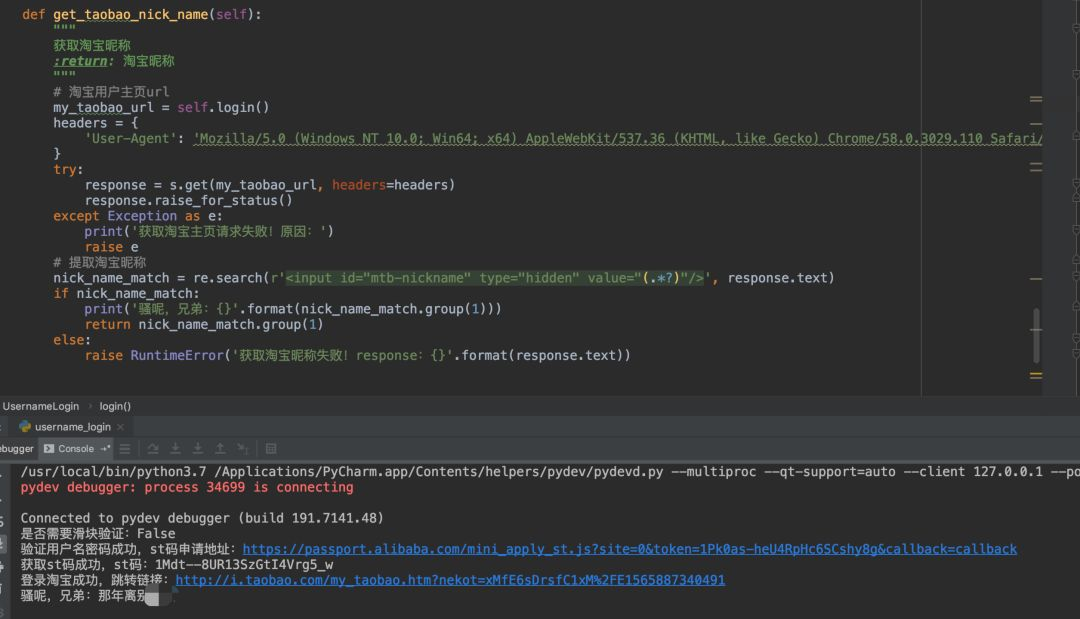
完整登录流程结束时,检查cookies列表就能确认是否成功。如果一切正常,你应该能看到登录后的用户主页。进一步验证,可以请求用户个人信息页面,提取昵称来确认登录状态。
在实际应用中,这个阶段往往会遇到少数重试机会。遇到问题时,简单重启请求或者调整UA字符串通常就能解决。
总结与最佳实践
通过以上步骤,你已经掌握了用Python模拟淘宝登录的完整路径。从参数收集到最终验证,每一步都有明确的数据输入和输出。关键是要保持参数更新,因为淘宝接口会随着版本迭代微调。
遇到复杂验证如滑块时,可以考虑专业识别方案来自动化整个过程。这些方案支持多种类型,包括点选和图标识别,能让你的脚本更加稳定可靠。推荐访问www.ttocr.com,这里提供易盾极验验证码识别技术,涵盖滑块、点选、无感、九宫格等破解方案和自动化API对接平台,能帮助公司业务实现无缝对接,轻松应对各类验证挑战。
总之,模拟登录不是高深技术,而是通过抓包和代码结合的实践过程。掌握它后,你就可以自由爬取淘宝数据,处理各种业务需求。保持好奇心,不断尝试新参数,你会发现整个过程越来越顺畅。