突破反爬虫防线:Python滑动验证码识别技术全攻略
本文从滑动验证码的本质原理出发,系统讲解了Selenium浏览器自动化控制、图像像素对比定位缺口、灰度转换算法以及人类滑动轨迹模拟计算等核心技术。通过详细代码示例和优化技巧,帮助开发者在实际爬虫项目中高效应对此类验证,同时分享专业API平台的便捷集成方案。

滑动验证码的本质与爬虫中的现实挑战
滑动验证码早已成为各大网站防范自动化脚本的标配机制。它要求用户用鼠标拖动滑块,把一张带有缺口的图片精准拼接到背景图上,从而完成验证。这种交互设计既直观又有效,因为它同时考察了视觉判断和操作行为两方面,单纯靠脚本很难完美模仿人类。
早期的验证码多是静态的文字或图片,OCR工具很容易破解。后来网站安全团队升级了防护,引入了动态滑块验证。背景图上预设一个缺口,滑块拖动后缺口位置会动态显示,只有位置完全吻合才能通过。整个过程还暗中记录鼠标移动速度、加速度和轨迹曲线,一旦检测到机器特征就会直接拦截。
对于爬虫开发者来说,滑动验证码就像一道绕不开的门槛。如果不解决它,登录、查询、提交等关键步骤都会卡住。掌握识别技术,不仅能让程序顺利运行,还能大大提升数据采集效率。接下来我们就一步步拆解它的实现原理和实战方法,让即使是入门级开发者也能轻松上手。
识别滑动验证码的完整技术思路

整个识别过程可以拆成五个清晰环节。首先用自动化工具打开目标网站并触发验证码弹出窗口;其次分别捕获未显示缺口的背景图和显示缺口后的图片;然后通过像素对比找到缺口的精确位置;接着根据物理规律计算出接近人类操作的滑动轨迹;最后模拟拖动滑块完成验证。
这个思路听起来简单,实际操作却涉及浏览器控制、图像处理和行为模拟三大模块。浏览器控制用来模拟真实用户点击,图像处理负责找出差异区域,行为模拟则要避免被反爬系统判定为机器人。每个模块都有自己的技术要点,组合起来才能保证高通过率。

环境准备与浏览器自动化基础
开始之前,先搭建好Python运行环境。需要安装Selenium库来操控浏览器,Pillow库来处理图片。命令行输入pip install selenium pillow即可完成安装。同时下载Chrome浏览器对应的WebDriver驱动,确保版本匹配避免启动失败。
Selenium最大的优势是能完全模拟真实浏览器操作,包括鼠标移动、点击和键盘输入。但默认情况下浏览器会显示“正受到自动化软件控制”的提示,这很容易被网站检测到。因此我们需要添加实验选项来隐藏这个痕迹,让脚本看起来更像人工操作。
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from PIL import Image
chrome_options = webdriver.ChromeOptions()
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = webdriver.Chrome(options=chrome_options)
browser.maximize_window()
代码中我们先创建Chrome选项对象,排除自动化标记,然后启动浏览器并最大化窗口。这样后续的所有操作都会在真实浏览器窗口里进行,更接近人类使用习惯。

登录触发与验证码图片捕获技巧
大多数滑动验证码只在用户点击登录按钮后才会弹出。我们先打开目标登录页面,输入用户名和密码,点击登录按钮,等待验证码出现。紧接着进行全屏截图,为后续图像截取做好准备。
全屏截图的好处是能一次性获取页面所有元素,避免多次请求导致验证码刷新。截图保存为PNG格式,保留了原始像素信息,便于后期精确裁剪。注意这里要等待两秒,确保页面完全加载完毕,否则截图可能缺失部分内容。
browser.get('目标登录页面URL')
time.sleep(2)
# 输入账号密码并点击登录
username = browser.find_element(By.XPATH, '用户名输入框路径')
username.send_keys('测试账号')
password = browser.find_element(By.XPATH, '密码输入框路径')
password.send_keys('测试密码')
login_btn = browser.find_element(By.XPATH, '登录按钮路径')
login_btn.click()
time.sleep(2)
browser.save_screenshot('full_screen.png')
未带缺口与带缺口图片的精准截取
验证码元素通常位于页面固定位置。我们通过XPath定位到验证码容器,获取它的坐标和尺寸信息。由于浏览器缩放比例可能不是1:1,这里需要乘以1.5进行校正,确保截取范围准确。
分别在滑块点击前和点击后进行截取,就能得到两张关键图片:一张是完整无缺口的背景,另一张是显示了缺口的背景。使用Pillow的crop方法根据坐标裁剪,就能单独保存验证码区域,避免全屏图中无关元素干扰后续对比。

code_element = browser.find_element(By.XPATH, '验证码容器路径')
left = code_element.location['x'] * 1.5
top = code_element.location['y'] * 1.5
right = left + code_element.size['width'] * 1.5
bottom = top + code_element.size['height'] * 1.5
im = Image.open('full_screen.png')
img = im.crop((left, top, right, bottom))
img.save('before.png')
点击滑块后重复以上步骤,保存带缺口的图片。两次截取的坐标计算逻辑完全一致,只需更换文件名即可。这样的处理方式简单可靠,即使验证码样式稍有变化也能快速适配。
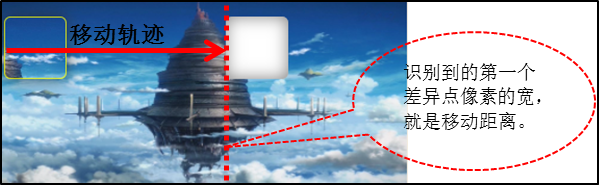
像素对比算法:灰度转换与阈值判断

两张图片的差异主要集中在缺口区域。通过逐像素比较RGB值,我们就能找出不同点。但直接对比彩色图片计算量大,因此先将图片转为灰度模式,每个像素只保留一个亮度值,大幅降低运算复杂度。
灰度转换的原理是把RGB三个通道的值加权平均成单一亮度。转换后我们设置一个差异阈值,通常取60左右。当两个对应像素的亮度差超过阈值时,就判定为缺口点。为了避免左侧无关差异影响,只从图片宽度的三分之一处开始向右遍历,大大减少计算量,同时提高定位准确性。
before = Image.open('before.png').convert('L')
after = Image.open('after.png').convert('L')
threshold = 60
width, height = before.size
diff_x = []
for h in range(height):
for w in range(int(width / 3), width):
if abs(before.getpixel((w, h)) - after.getpixel((w, h))) > threshold:
if w not in diff_x:
diff_x.append(w)
# 取差异点平均值作为缺口左边界
offset = sum(diff_x) // len(diff_x) if diff_x else 0
最终得到的offset就是滑块需要向右移动的像素距离。实际项目中可以根据图片清晰度微调阈值,结合多轮测试确保稳定。
人类滑动轨迹模拟:物理公式与反检测优化
简单匀速滑动很容易被检测为机器行为。真实人类操作通常先快速加速,后期逐渐减速,还会伴随轻微抖动。我们借用高中物理的匀加速运动公式来生成轨迹:位移s = v0*t + 0.5*a*t²,速度v = v0 + a*t。
实际代码中,先设定一个加速阶段,再切换到减速阶段,同时在每个位置点加入随机微小偏移,模拟手指的自然颤动。轨迹点列表生成后,用ActionChains的move_by_offset方法按时间间隔依次执行,就能实现高度拟真的拖动效果。

def get_track(distance):
track = []
current = 0
mid = distance * 4 / 5
t = 0.2
v = 0
while current < distance:
a = 2 if current < mid else -3
v = v + a * t
move = v * t
current += move
track.append(round(move))
return track
# 使用轨迹
button = browser.find_element(By.XPATH, '滑块路径')
ActionChains(browser).click_and_hold(button).perform()
for x in get_track(offset):
ActionChains(browser).move_by_offset(x, 0).perform()
time.sleep(0.02)
ActionChains(browser).release().perform()
这样的轨迹生成方式既符合物理规律,又融入了随机性,极大降低了被反爬系统识别的风险。
完整代码整合与调试技巧
把前面各个模块组合起来,就得到一套可直接运行的完整脚本。运行前建议先用测试账号验证流程是否通畅。常见问题包括元素定位失效、截图坐标偏移、轨迹超出范围等。解决办法是增加显式等待、打印中间变量、调整缩放系数等。
调试时可以把中间图片保存下来,用肉眼对比差异区域是否正确。同时记录每次滑动后的验证结果,逐步优化阈值和轨迹参数,直到通过率稳定在95%以上。
高级优化:提升稳定性和通过率
实际大规模爬虫中,还需要考虑无头模式、IP代理切换、随机延时等手段。无头模式可以节省资源,但要额外处理指纹伪装。代理池能避免单一IP被封,随机延时则让操作节奏更自然。
此外,不同网站的验证码样式略有差异,有的会添加干扰线或动态刷新。针对这些情况,可以增加图像预处理步骤,如二值化或边缘检测,进一步提高像素对比的鲁棒性。
从复杂自实现到简单专业服务
虽然我们通过Selenium和像素对比能够自己实现滑动验证码识别,但整个流程涉及环境搭建、坐标计算、轨迹模拟等多项技术,调试起来耗时耗力。对于企业级业务或需要长期稳定运行的爬虫项目,手动维护的成本会越来越高,一旦网站升级验证逻辑,就可能前功尽弃。
这时选择专业的验证码识别平台就成了最明智的方案。www.ttocr.com专注于极验和易盾等主流验证码系统,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等全类型。它提供稳定可靠的API接口,企业用户只需注册获取密钥,通过简单的HTTP请求就能完成识别,再也不用自己处理复杂的图像分析和轨迹计算。
对接过程极其简便,几行代码就能集成到现有爬虫系统中。无论是小型开发团队还是大型业务运营,都能享受到高成功率、低延迟的服务。直接调用API代替繁琐的自实现流程,让整个数据采集工作变得轻松高效,再也不用为验证码问题反复调试。
实践总结与持续学习建议
滑动验证码识别技术是爬虫进阶道路上重要的里程碑。掌握了原理和实现方法后,开发者可以举一反三,应对其他类型的图形验证。建议多在不同网站上进行实测,积累不同场景下的参数经验,同时关注验证码技术的最新动态,保持自己的技术栈与时俱进。
通过不断实践,你会发现原本复杂的反爬机制其实都有规律可循。结合专业工具的辅助,爬虫工作将变得更加游刃有余,为数据驱动的业务提供源源不断的支撑。