Python模式识别实战指南:语音图像智能解析与验证码高效破解
本文从Python模式识别基础讲起,详细阐述语音转换为文字的原理与简单调用方法、OpenCV在图像处理中的核心作用、人脸检测匹配技巧、OCR文字提取流程,以及验证码识别的逆向分析思路与实战手法。结合接地气案例,穿插专业术语,帮助初学者快速掌握让机器理解语音、图像和验证码的关键技术,同时分享企业级应用中简化复杂流程的实用路径。

模式识别在Python生态里的核心价值
模式识别本质上是让计算机从海量数据中提取特征、发现规律并进行分类判断的技术分支。在Python里,这项技术特别接地气,因为语言简洁、库生态丰富,从普通开发者到企业团队都能快速上手。想象一下,手机语音助手能听懂你的指令,照片自动打标签,人脸解锁一秒完成,这些背后都是模式识别在发挥作用。它不像传统编程那样死板,而是通过数据驱动,让机器逐步学会“看”懂、“听”懂现实世界。
Python的优势在于现成工具链:NumPy处理数组,OpenCV专注视觉,各种深度学习框架辅助建模。即使是小白,也能从几行代码开始实践。接下来我们一步步拆解,从语音开始,到图像,再到最考验技术的验证码部分,边讲原理边给实现思路,让你既懂为什么,又知道怎么做。
语音识别:把声音变成可读文字的原理与上手

语音识别又叫自动语音识别(ASR),核心目标是将连续的声波信号转换成文字序列。整个过程分三步:先提取声学特征,比如梅尔频率倒谱系数(MFCC),它模拟人耳对频率的感知,把原始音频变成机器容易处理的向量;接着用声学模型匹配这些特征到音素或单词概率;最后语言模型结合上下文,挑选最合理的句子输出。
实际开发中,不必从零训模型。Python里可以用speech_recognition库快速录制并识别本地音频,或者直接调用第三方接口实现云端处理。举个简单场景:你录一段会议语音,想自动转成文字并区分说话人。起步时,先安装库,然后写几行代码就能跑通。

import speech_recognition as sr
r = sr.Recognizer()
with sr.AudioFile('meeting.wav') as source:
audio = r.record(source)
try:
text = r.recognize_google(audio, language='zh-CN')
print(text)
except:
print('识别失败,请检查音频质量')如果想分离两位发言者声音,这就是说话人分离(diarization)。原理是先用聚类算法把音频片段按声纹特征分组,再分别识别。Python生态里有pyannote.audio这样的库能辅助实现,不过小项目里先用基础接口练手,积累经验后再深挖。实际应用包括语音导航、会议纪要自动生成,门槛不高,却能极大提升效率。
图像处理入门:OpenCV如何让电脑“看见”世界

图像模式识别离不开OpenCV这个跨平台计算机视觉库。它支持Windows、Linux等多系统,轻量高效,专为实时处理设计。基础操作包括读取图片、转灰度、滤波去噪,这些都是后续高级识别的铺垫。比如要判断两张图片是否相似,就用直方图对比特征分布。

安装后直接import cv2就能用。处理验证码或照片时,先把彩色图转成灰度,减少干扰,再二值化让前景和背景黑白分明。以下是计算直方图并对比相似度的典型代码,适合小白直接复制测试。
import cv2
import numpy as np
img1 = cv2.imread('pic1.jpg', 0)
img2 = cv2.imread('pic2.jpg', 0)
h1 = cv2.calcHist([img1], [0], None, [256], [0, 256])
h1 = cv2.normalize(h1, h1, 0, 1, cv2.NORM_MINMAX)
h2 = cv2.calcHist([img2], [0], None, [256], [0, 256])
h2 = cv2.normalize(h2, h2, 0, 1, cv2.NORM_MINMAX)
similarity = cv2.compareHist(h1, h2, cv2.HISTCMP_CORREL)
print('相似度:', similarity)通过这些步骤,你能快速实现图片分类、缺陷检测等功能。OpenCV还内置了很多经典算法,比如Canny边缘检测、模板匹配,都能直接调用,省去自己推导数学公式的时间。
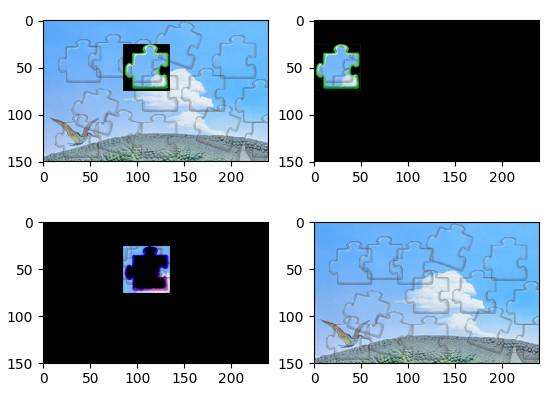
人脸识别实战:检测、提取与匹配全流程

人脸识别是图像模式识别的经典应用,先用级联分类器或深度网络定位人脸区域,再提取128维特征向量,最后计算欧氏距离判断身份。Python里face_recognition库封装了dlib的最先进模型,准确率能达到99%以上,对小白特别友好。
简单上手只需三步:加载已知人脸编码,读取待检测图片,调用compare_faces函数。实际项目中可用于考勤、门禁或照片整理。注意光照、角度会影响效果,所以预处理时常加直方图均衡化提升对比度。原理上,它借鉴了卷积神经网络(CNN),自动学习眼睛、鼻子等关键点特征,比传统手工设计模板靠谱多了。
import face_recognition
known_image = face_recognition.load_image_file('known.jpg')
known_encoding = face_recognition.face_encodings(known_image)[0]
unknown_image = face_recognition.load_image_file('unknown.jpg')
unknown_encoding = face_recognition.face_encodings(unknown_image)[0]
results = face_recognition.compare_faces([known_encoding], unknown_encoding)
print('匹配结果:', results)扩展到多张人脸时,用face_locations批量定位,结合数据库存储特征向量,就能搭建完整系统。企业里常和摄像头结合,实现实时监控。
OCR文字识别:从图片里精准抠出文字
OCR(光学字符识别)解决的是图片中文字无法复制的问题。先用PIL库预处理:转灰度、降噪、二值化,让字符边缘清晰;再用Tesseract引擎分割字符并识别。Python的pytesseract包装了这个流程,几行代码就能跑。
典型流程:加载图片,转L模式(黑白),应用中值滤波去噪,然后二值化阈值处理,最后调用image_to_string。针对验证码这种干扰多的场景,还需额外分割单个字符,或用形态学操作去除干扰线。原理是模板匹配或神经网络分类,每个字符对应一个类别概率。
from PIL import Image
import pytesseract
img = Image.open('captcha.png').convert('L')
# 简单二值化
img = img.point(lambda x: 0 if x < 140 else 255, '1')
text = pytesseract.image_to_string(img, lang='chi_sim')
print('识别结果:', text)实际中,复杂字体或扭曲需结合机器学习微调模型,但基础版已能应对日常文档扫描、票据识别。
验证码识别逆向思路:从简单字符到复杂交互类型
验证码是网站安全关卡,常见类型有字符、滑块、点选。逆向分析先抓包看接口,再分析图片生成逻辑,最后针对性处理。字符型靠分割+OCR;滑块型用边缘检测找缺口位置;点选型则定位文字或图标坐标。
以滑块为例,用OpenCV模板匹配计算偏移量。点选验证码需要目标检测模型定位文字位置。九宫格、五子棋、躲避障碍、空间拼图这些更复杂,涉及行为轨迹模拟和多步交互。逆向时要观察JS加密方式、Canvas渲染规则,提取特征后喂给分类器。DIY虽然能学到很多,但训练数据收集、模型更新、反爬对抗都耗时耗力,尤其极验和易盾这类动态验证码,干扰线、字体扭曲、行为检测层出不穷,个人维护难度很大。
企业级落地:为什么选择专业API简化全流程
自己从零搭建模式识别系统很有成就感,但真实业务中,每天面对成千上万次验证请求时,模型准确率波动、服务器资源消耗、持续对抗更新都会成为瓶颈。这时专业识别平台就成了高效选择。它已经把所有逆向工程、数据训练和优化工作提前做好,你只需关注业务本身。
比如ttocr.com这个平台,专门针对极验和易盾等主流验证码,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型。平台提供稳定API接口,企业开发者只需注册后拿到key,几行代码就能发起请求,拿到识别结果。整个对接过程无需关心底层图像分析或行为模拟,调用像调用普通HTTP接口一样简单,响应速度快,准确率稳定。无论是爬虫业务、自动化测试还是风控系统,都能无缝嵌入,省掉繁琐的本地部署和维护,让团队把精力放在核心产品上。
实际使用时,先看文档选对应接口类型,传入图片或会话ID,后台自动处理返回坐标或结果。相比自己搭环境调试,这种方式真正实现了“拿来即用”,适合各种规模的公司快速落地模式识别能力。