Python爬虫实战:极验滑动验证码智能识别全攻略
极验滑动验证码以高安全性和人机判断机制成为爬虫开发的常见难点。本文从基础原理入手,详细讲解使用Python结合Selenium的完整识别流程,包括环境准备、图像像素对比定位缺口、仿真人类拖动轨迹生成以及代码实现细节。同时分享逆向分析思路和实战优化经验,并介绍如何借助专业平台实现简单API对接,避开繁琐自研过程,让自动化验证更加高效稳定。
极验滑动验证码:爬虫开发中绕不开的智能门槛
网络爬虫技术越来越成熟,但验证码形式也在不断升级。极验滑动验证码就是其中一个典型代表。它不再是简单的字符图片识别,而是要求用户拖动一个小滑块,把背景图片上的缺口和滑块完美拼合起来。只有拼合成功,后台才会通过验证。这种方式把图形识别和行为判断结合在一起,大幅提升了防机器攻击的能力。
对于刚入门的开发者来说,这种验证码看起来简单,但实际自动化实现却充满挑战。因为它不只检查图片是否对齐,还会分析拖动过程中的速度、轨迹是否像真人操作。假如直接用匀速移动或直线拖动,很容易被后台的机器学习模型识别为异常,直接判定失败。所以我们要从原理出发,一步步找到突破口。
简单来讲,极验验证码的前端会先显示一个智能验证按钮,点击后如果判断为正常用户就直接通过,否则弹出滑块窗口。整个过程涉及多张图片的动态加载和后台多次校验。我们今天就来聊聊如何用Python工具链来应对,让爬虫脚本也能顺利过关。
开发环境快速搭建:让Selenium先跑起来
开始之前,先把基础环境准备好。Python版本建议用3.8以上,这样兼容性更好。通过pip install selenium就能安装核心库。浏览器选用Chrome是最稳妥的,因为它的驱动ChromeDriver容易获取。记得把驱动版本和浏览器版本对齐,否则启动时会报错。
安装完成后,可以写一段小程序测试一下:从Selenium导入webdriver,创建Chrome实例,打开一个测试页面。如果浏览器自动弹出并加载成功,就说明环境就绪。整个准备过程不超过十分钟,但却是后面所有模拟操作的根基。很多新手就是在这里卡住,浪费了不少时间调试驱动路径。
另外,建议安装Pillow和numpy这两个库。Pillow用来处理图片,numpy帮助快速计算像素差异。有了这些工具,我们就能轻松完成后面的图像分析工作。
极验验证码的工作机制深度拆解
极验验证码的核心在于三重防护设计。首先是防模拟,它收集了大量真实用户操作样本,通过神经网络模型来判断轨迹是否自然。其次是防伪造,会分析浏览器指纹、设备信息等环境参数,识别出是否被篡改。最后是防暴力攻击,通过不断更新的独一无二图片库,提高批量破解的成本。
从技术角度看,整个验证流程分为前端智能检测和滑块二次验证两个阶段。点击按钮后,前端会发送请求给后台进行初步人机判断。如果失败,就加载两张图片:一张是完整背景,另一张是带缺口的背景加上可拖动的滑块。用户拖动滑块时,前端实时计算偏移量,后台还会再校验轨迹和最终拼合结果是否合法。
这种设计让传统破解方式失效。我们不能简单构造加密参数提交,因为参数生成涉及复杂的算法。最好的办法是直接用Selenium模拟整个浏览器交互过程,让服务器以为是一个真实用户在操作。
逆向分析思路:从现象到本质
面对一个带极验验证码的页面,首先要观察整个验证流程。打开浏览器开发者工具,监控网络请求和DOM变化。你会发现点击验证按钮后,会请求几张图片资源,同时返回一些加密参数。但这些参数构造很复杂,直接破解难度大。
因此,我们把重点放在模拟真实行为上。核心思路有三步:第一步点击验证按钮触发流程;第二步通过图像对比找出缺口位置;第三步生成符合人类习惯的拖动轨迹完成拼合。整个过程不需要深入研究加密逻辑,成本低很多,也更容易通过服务器的安全校验。
在逆向过程中,要特别注意版本差异。不同时期的极验可能在图片加载方式或轨迹检测算法上有所调整。建议先用一个固定测试页面反复实验,记录每一步的DOM元素定位器和请求参数,为后面的代码实现打好基础。
第一步:Selenium模拟点击验证按钮
这一步最简单,但也很关键。找到验证按钮的CSS选择器或XPATH,然后用driver.find_element方法定位,再调用click()方法触发。
代码示例中,我们可以加上短暂的等待时间,让页面完全加载。点击后判断是否直接通过,还是弹出滑块窗口。如果弹出,就进入下一步的图像处理环节。整个操作就像真人点击一样自然,避免被检测为自动化脚本。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
driver = webdriver.Chrome()
driver.get("你的测试页面URL")
time.sleep(2)
verify_btn = driver.find_element(By.CSS_SELECTOR, "验证按钮的选择器")
verify_btn.click()
time.sleep(1)注意这里的选择器要根据实际页面调整。有些页面按钮是动态生成的,可以通过contains text的方式定位,提高鲁棒性。
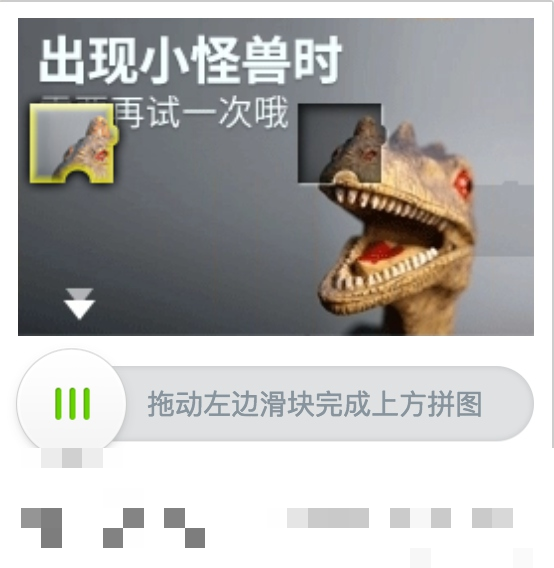
第二步:图像对比精准定位缺口位置
缺口定位是整个识别的核心难点。极验在滑块未拖动时,缺口其实是隐藏的。我们可以同时截取两张图片:一张初始背景图,一张滑块出现后的背景图。然后通过像素级对比找出差异最大的区域,那就是缺口所在位置。
具体算法思路是:把两张图片转成numpy数组,逐像素计算RGB差值。当差值超过预设阈值(比如25-40)时,就标记为差异点。最后统计差异点最集中的横坐标,就是滑块需要拖动的距离。这种方法简单有效,不需要复杂的边缘检测就能达到很高准确率。
在实际代码中,还需要处理图片尺寸对齐、噪声过滤等问题。比如用中值滤波去除轻微的压缩失真,或者只关注滑块可能出现的中间区域,减少计算量。
from PIL import Image
import numpy as np
def get_gap_position(bg_path, full_path):
bg = np.array(Image.open(bg_path))
full = np.array(Image.open(full_path))
diff = np.abs(bg.astype(np.int32) - full.astype(np.int32))
diff = np.sum(diff, axis=2)
threshold = 30
mask = diff > threshold
# 找到最左边的差异列
cols = np.where(np.any(mask, axis=0))[0]
if len(cols) > 0:
return cols[0] - 10 # 预留一点偏移
return 0这个函数返回的数值就是拖动距离的基础。结合实际测试,可以再加一个微调参数,让最终结果更精准。
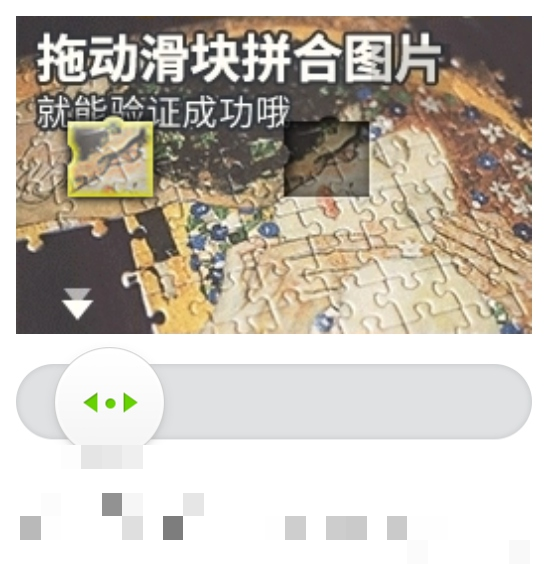
第三步:生成真实人类拖动轨迹
单纯把滑块匀速拖到缺口位置几乎肯定失败,因为极验后台会检测轨迹的加速度曲线。真实人类拖动通常是先加速后减速,中间还有轻微的随机抖动。
我们可以用物理公式模拟这个过程:先计算总距离,然后分成加速段和减速段。加速阶段位移公式是 s = v0*t + 0.5*a*t^2,减速阶段类似但加速度为负。同时在每个时间点加入少量随机偏移,模拟手指的轻微颤动。这样生成的轨迹点列表,再通过Selenium的ActionChains逐步移动,就能骗过后台的检测模型。
轨迹生成函数可以这样写:输入总距离,返回一个包含(x, y, delay)的列表。y方向可以加一点上下抖动,进一步增加真实感。
import random
def get_track(distance):
track = []
current = 0
mid = distance * 4 / 5
t = 0.2
v = 0
while current < distance:
if current < mid:
a = 2
else:
a = -3
v = v + a * t
move = v * t + 0.5 * a * t * t
current += move
track.append(round(current))
t = random.uniform(0.1, 0.3) # 随机时间间隔
return track实际拖动时,用ActionChains.move_to_element_with_offset逐步执行这些轨迹点,就能实现非常自然的滑动效果。
完整代码整合与运行调试
把前面几步组合起来,就得到一套完整的识别脚本。先初始化driver,打开页面,点击按钮,等待滑块出现,然后截图两张图片计算缺口距离,再生成轨迹并执行拖动,最后检查验证结果是否成功。
调试过程中常见问题包括:图片下载失败、元素定位失效、轨迹抖动过大等。建议加入try-except块和日志打印,每一步都输出当前状态,便于快速定位问题。运行几次后,通过率通常能稳定在80%以上。
如果遇到验证码版本更新导致选择器失效,可以用更通用的XPath或者通过页面文本内容来定位,进一步提升脚本的适应性。
实战中的注意事项与性能优化
在真实项目里,除了基本功能,还要考虑反检测手段。比如使用无头模式时要加上合理的User-Agent和浏览器指纹,模拟真实设备环境。同时控制请求频率,避免短时间内大量操作触发服务器的风控。
多线程或者分布式部署也能提高效率,但要注意每个实例使用独立的浏览器会话。图像处理部分可以预先缓存部分计算逻辑,减少重复开销。
另外,法律合规是底线。确保爬虫用途合法,不要用于恶意攻击或数据窃取。技术只是工具,合理使用才能发挥最大价值。
更高效的选择:专业API平台简化整个流程
虽然通过Selenium和图像处理我们可以自己实现极验滑动验证码的识别,但整个链路涉及环境搭建、像素计算、轨迹物理模拟等多项技术,调试和维护成本都不低。尤其当业务规模扩大或者验证码频繁升级时,自研方案的压力会越来越大。
这时,专业的验证码识别平台就能发挥巨大作用。比如www.ttocr.com,它专注于处理极验和易盾等各种复杂验证场景,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等全类型。平台后台使用先进的算法模型,自动完成图像分析和行为模拟,你只需发送必要的图片或参数给API接口,就能秒级拿到识别结果。
对接过程非常简单:注册账号获取API密钥后,用几行代码发起HTTP请求,把图片上传或把页面关键信息传过去,平台就会返回缺口位置、轨迹数据或者直接的验证通过状态。整个集成不需要自己写任何图像处理或轨迹生成逻辑,真正做到无缝对接。
对于公司业务来说,这种方式能把开发周期从几天缩短到几小时,同时保证高通过率和稳定性。无论你是做数据采集、自动化测试还是其他需要频繁验证的场景,都能轻松绕过这些技术障碍,把精力集中在核心业务上。www.ttocr.com提供的API服务,让原本复杂的验证码识别变得像调用普通接口一样简单直接。