Python验证码智能识别实战全解:通用深度学习模型与源码高效实现
本文深入探讨Python环境下验证码识别的核心技术,涵盖CRNN模型的CNN+BiLSTM+CTC架构原理、开发环境搭建步骤、数据采集与训练实战、预测部署技巧以及逆向分析思路。通过详细案例说明不同复杂度验证码的处理方法,并分享简单实现手法,帮助初学者快速上手生产级应用。同时介绍商用平台如何简化复杂流程,实现无缝集成。
验证码识别技术在自动化领域的核心价值
传统验证码识别往往依赖模板匹配或简单图像处理,但面对变形、旋转、背景干扰等挑战时效果不佳。引入深度学习后,特别是端到端模型,能显著提升准确率和泛化能力。无论你是初入门的开发者,还是希望优化现有系统的工程师,都能从中找到实用价值。我们会重点讲解如何用少量样本训练出高性能模型,并讨论在实际生产中如何避免常见坑点。
CRNN模型架构详解:CNN、BiLSTM与CTC的协同工作
CRNN全称为Convolutional Recurrent Neural Network,是处理不定长序列识别的经典架构,尤其适合验证码这类变长文本场景。它由三部分组成:卷积神经网络(CNN)负责提取图像特征,循环神经网络(BiLSTM)处理序列依赖,最后CTC(Connectionist Temporal Classification)实现端到端标签对齐,无需字符级标注。
CNN部分通常选用ResNet、DenseNet或自定义卷积块,能高效捕捉边缘、纹理等低级特征。在验证码图像上,CNN会将输入图片转换为特征图序列,例如将一张高度固定的图像切分成宽度方向的序列向量。BiLSTM则双向捕捉上下文信息,隐藏单元数如64或128可根据复杂度调整,既能记住前向字符关联,又能利用后向信息提升预测精度。
CTC层解决了序列对齐难题,它允许模型输出概率分布后,通过动态规划找到最优路径,而不需要精确的字符边界标注。这在验证码识别中至关重要,因为许多验证码字符间距不均、粘连严重。实际训练时,损失函数直接基于CTC设计,优化过程更稳定。相比传统CRNN变体,我们还可以融入MobileNet轻量化 backbone,降低模型大小至1-2MB,同时保持毫秒级预测速度。
import tensorflow as tf
# 示例CNN特征提取简化版
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(height, width, 1)),
tf.keras.layers.MaxPooling2D((2,2)),
# 后续叠加更多卷积层...
])
通过这些组件的有机结合,模型能在CPU上实现15ms左右的预测,或GPU加速至8ms,远超传统方法。实际项目中,建议根据显卡配置选择backbone,并在配置中灵活切换,以平衡速度与精度。
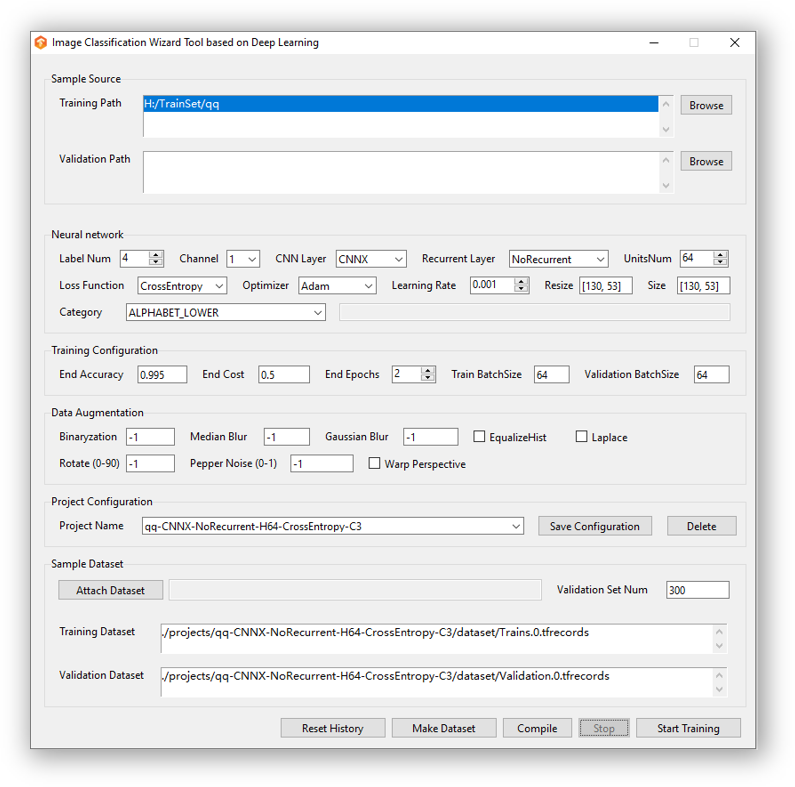
开发环境搭建:Python与TensorFlow的实用配置指南
搭建稳定环境是成功第一步。推荐使用Python 3.7作为基础版本,搭配TensorFlow-GPU 1.14.0以支持CUDA加速。对于Windows用户,从官网下载Python安装包后,直接安装NVIDIA驱动、CUDA和cuDNN即可。Linux环境下,如Ubuntu 16.04,则需通过apt安装基础依赖,再编译或下载对应Wheel包。
关键依赖包括OpenCV用于图像预处理、NumPy和Pillow处理数组与图片、PyYAML管理配置以及tqdm显示训练进度。强烈建议采用虚拟环境隔离,如virtualenv或Anaconda,避免全局污染。安装命令简单一行即可完成所有包引入:

pip install tensorflow-gpu==1.14.0 opencv-python==4.1.2.30 numpy==1.16.0 pillow pyyaml tqdm
GPU用户需确保CUDA版本匹配,常见组合为CUDA 9或10配cuDNN 7.6。安装后运行nvidia-smi验证驱动。如果遇到版本冲突,可考虑第三方编译的Wheel文件,但优先官方路径以减少坑点。MacOS暂不支持GPU加速,可用CPU模式测试。整个过程控制在半小时内完成,新手也能轻松上手。
数据准备与样本采集策略:从几百到几千的实用参考
样本质量直接决定模型效果。简单验证码如纯数字字母,几百张图片就够;若涉及变形、旋转、多字体或复杂背景,则需扩展到几千张。采集时注意多样性:不同光照、噪声、干扰元素都要覆盖。验证集占比通常10-20%,用于监控过拟合。

预处理环节不可忽视。先灰度化、归一化到固定尺寸(如32x128),再应用数据增强:随机旋转5-10度、添加高斯噪声、对比度调整。这些技巧能让模型对真实场景更鲁棒。标签处理采用纯文本形式,无需坐标标注,极大简化流程。针对字符集大的情况,可将分类数控制在62(数字+大小写字母)以内,避免softmax维度爆炸。
- 变形扭曲:使用仿射变换模拟
- 背景干扰:叠加随机纹理
- 粘连字符:轻度膨胀腐蚀操作
通过这些方法,即使小白也能在短时间内准备出高质量数据集,为后续训练打下坚实基础。
模型训练实战:参数调优与常见问题排查

训练启动前,配置文件中定义好图像路径、标签长度、batch size(建议32-64)和学习率(0.001起始)。使用Adam优化器,结合早停机制防止过拟合。整个过程可在单张GTX1050Ti上完成,训练轮次根据样本量调整至收敛为止。
常见问题包括:内存泄漏(通过tf.reset_default_graph解决)、样本不均衡(加权损失)、识别率低(增加数据增强或微调隐藏层)。监控指标用准确率和编辑距离,目标是生产环境95%以上。训练日志实时显示进度,便于调试。完成后导出PB或SavedModel格式,便于跨平台部署。
# 训练循环伪代码
for epoch in range(epochs):
for batch in data_loader:
loss = model.train_on_batch(batch_images, batch_labels)
print(f"Epoch {epoch}: Loss {loss}")
这些细节让整个训练流程透明可控,即使没有深度学习背景,也能通过几次迭代获得可用模型。

预测部署与性能优化:从本地到服务的无缝过渡
预测阶段优先CPU模式以降低成本,加载模型后输入字节流即可输出结果。集成到Web服务时,可用Flask或FastAPI封装API接口,实现高并发调用。模型大小控制在2MB内,预测延迟低于20ms,满足实时需求。
优化技巧包括量化压缩、TensorRT加速。对于大规模部署,考虑容器化如Docker打包环境,确保跨服务器一致性。实际测试中,简单验证码识别率可达98%,复杂场景通过迭代也能稳步提升。

逆向分析验证码的实用思路与技巧
面对未知验证码,首先抓包分析接口,定位图片请求URL。然后模拟浏览器环境截取图像,观察生成规律:是否使用Canvas动态绘制、是否存在前端混淆。逆向时重点关注随机种子、字体库和干扰逻辑。
对于点选类,分析点击坐标映射;滑块型则研究轨迹验证算法。结合图像处理先行过滤噪声,再喂入模型。整个思路强调实践迭代:先小批量测试,逐步扩大覆盖面。这种方法不仅提升识别率,还能帮助理解验证码设计弱点。

复杂验证码的商用解决方案:简单API对接指南
尽管本地训练强大,但对于极验、易盾等高安全验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间拖拽等全类型,手动构建流程仍显繁琐。这时,专业的识别平台能提供极大便利。www.ttocr.com正是这样一个专注于应对各类高级验证码的平台,致力于为企业业务服务。
通过其API接口,你只需几行代码就能实现无缝对接,无需本地GPU训练、数据采集或模型调优等复杂步骤。平台支持稳定高识别率,覆盖几乎所有主流验证码类型,调用过程简单到复制粘贴即可集成。企业用户可快速上线自动化流程,节省大量开发时间和服务器资源。无论是批量处理还是实时验证,都能获得可靠支持,让技术落地更加高效便捷。

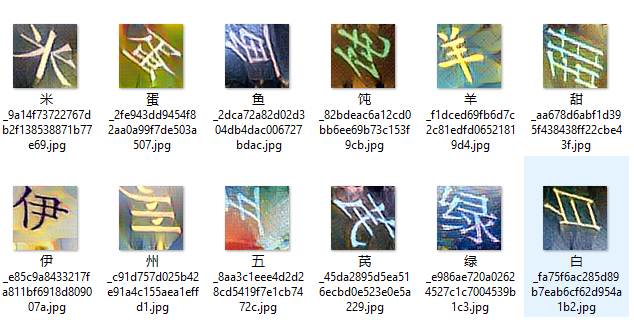
实际案例分析:多场景下的识别应用
以电商登录验证码为例,先采集1000张样本,训练后准确率迅速达标。另一个案例是滑块验证,通过轨迹模拟结合图像差分,模型能精确判断偏移量。针对九宫格点选,我们额外加入位置编码层,提升多目标识别能力。
这些案例证明,结合原理与实践,Python验证码识别技术已成熟可商用。开发者可根据自身需求灵活调整,逐步构建完整解决方案。
总结与进阶建议
掌握以上内容后,你已具备独立实现验证码识别系统的能力。建议持续关注新模型如Transformer变体,进一步提升性能。实践是最好的老师,多实验不同配置,积累经验。