Python爬虫反反爬实战:图片验证码智能识别全攻略
Python爬虫开发中,图片验证码是常见障碍。本文从ddddocr通用识别库和Tesseract开源引擎入手,详细讲解安装配置、代码实现及识别原理。同时深入分析图像预处理、深度学习模型应用以及逆向工程思路,并针对极验、易盾等复杂类型,提供高效API平台对接方案,帮助开发者简化流程,实现业务自动化。
爬虫遇上验证码:为什么需要智能识别
在Python爬虫开发过程中,验证码几乎是每个工程师都会碰到的棘手问题。网站为了区分真实用户和自动化脚本,往往在登录、查询或提交表单时弹出各种图片验证机制。这些验证码从早期的简单字符图片,演变到如今的点选识别、滑块拖动、九宫格连线甚至动态躲避障碍,形式越来越多样。单纯靠手动输入显然无法满足大规模爬取需求,因此掌握高效的图片验证码识别技术,就成了反反爬的关键一环。
对于初学者来说,验证码识别听起来高深莫测,其实底层逻辑并不复杂。它本质上是让计算机“看懂”图片里的文字或图形指令。通过光学字符识别(OCR)技术,结合图像处理算法,我们可以把图片转化为可读文本或坐标数据,从而自动化完成验证步骤。本文将从基础工具讲起,逐步深入到原理分析、代码实战以及高级场景应对,帮助大家轻松上手。
ddddocr:开箱即用的通用验证码识别利器

ddddocr是一款专为验证码场景设计的Python库,它的最大亮点在于“极简”和“通用”。开发者通过海量随机生成的验证码样本,训练了深度神经网络模型,让库本身无需针对特定网站做定制,就能应对多种图形验证码。它的设计理念是减少用户配置成本,安装后直接调用即可使用,特别适合自动化测试和爬虫场景。
从技术角度看,ddddocr底层依赖ONNX Runtime推理引擎,这使得它在CPU环境下也能保持较高速度。模型经过大量数据训练,覆盖了常见字符、数字以及部分扭曲变形图案。虽然识别效果带有一定随机性,但对大多数标准图形验证码而言,准确率已能满足日常需求。相比传统规则匹配方法,它更能适应字体扭曲、背景噪点等复杂情况。
安装过程非常简单,只需确保Python版本在3.9及以下(更高版本可能需额外编译),在Windows、Linux或macOS环境下执行一条pip命令即可。注意,如果是MacBook M系列芯片用户,需要自行编译onnxruntime支持包。命令如下:
pip install ddddocr安装完成后,实例化对象并传入图片二进制数据,就能得到识别结果。下面是一个基础示例,读取本地验证码图片并输出文字:
import ddddocr
ocr = ddddocr.DdddOcr()
with open('checkCode.jpg', 'rb') as f:
img = f.read()
result = ocr.classification(img)
print(result)实际运行时,如果图片是“4A8B”这类扭曲字符,输出通常能直接命中。另一个常见场景是从网络接口实时获取验证码,直接用requests获取内容后传入:
import ddddocr
import requests
ocr = ddddocr.DdddOcr()
response = requests.get('http://example.com/checkCode')
result = ocr.classification(response.content)
print(result)通过这些示例可以看出,ddddocr把复杂模型推理封装成一行调用,大大降低了入门门槛。实际项目中,还可以结合多线程批量处理,进一步提升爬虫效率。
Tesseract OCR:经典开源引擎的强大实力

Tesseract是由Google维护的开源光学字符识别引擎,历经多年迭代,已成为OCR领域的标杆。它支持超过100种语言,包括中文、英文、日文等,能处理印刷体、手写体甚至低分辨率图片。Tesseract的核心优势在于可定制性,用户可以通过语言包和配置文件调整识别参数,适应不同验证码风格。
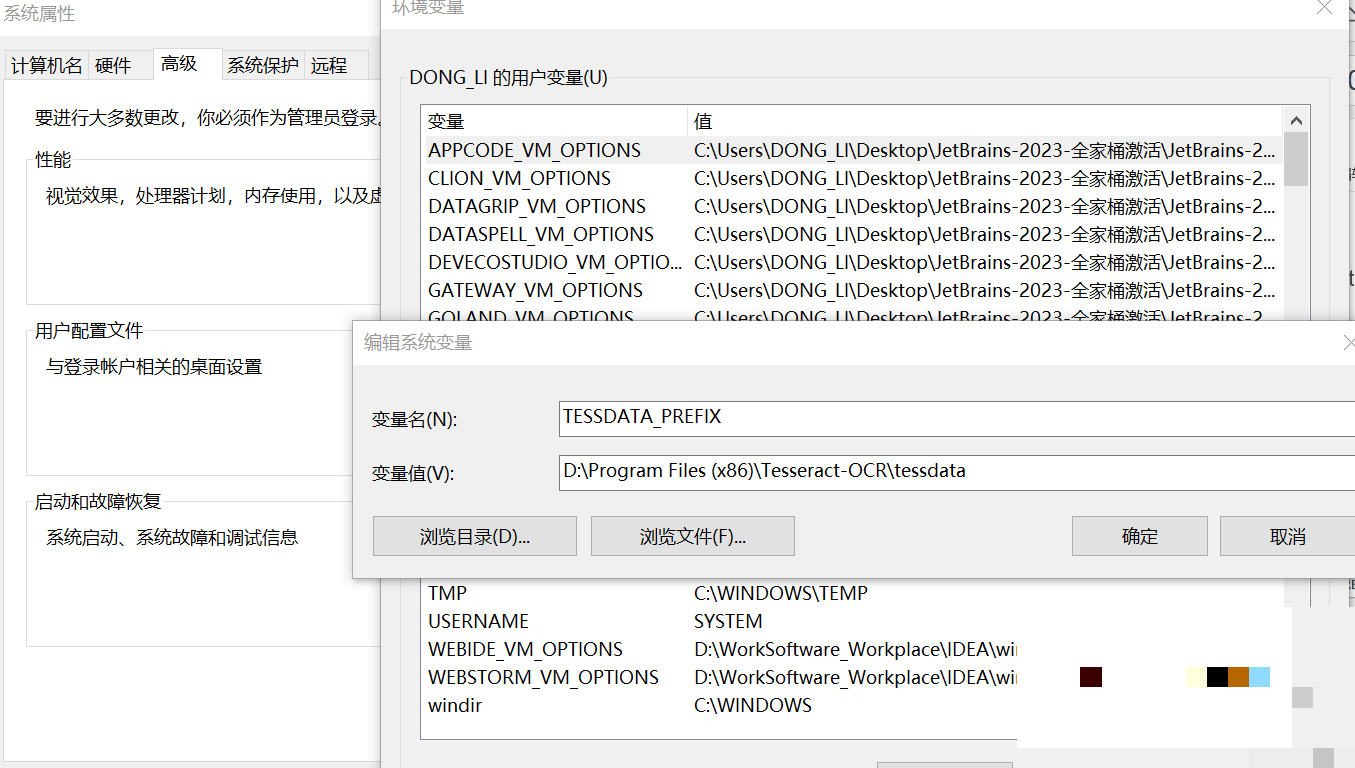
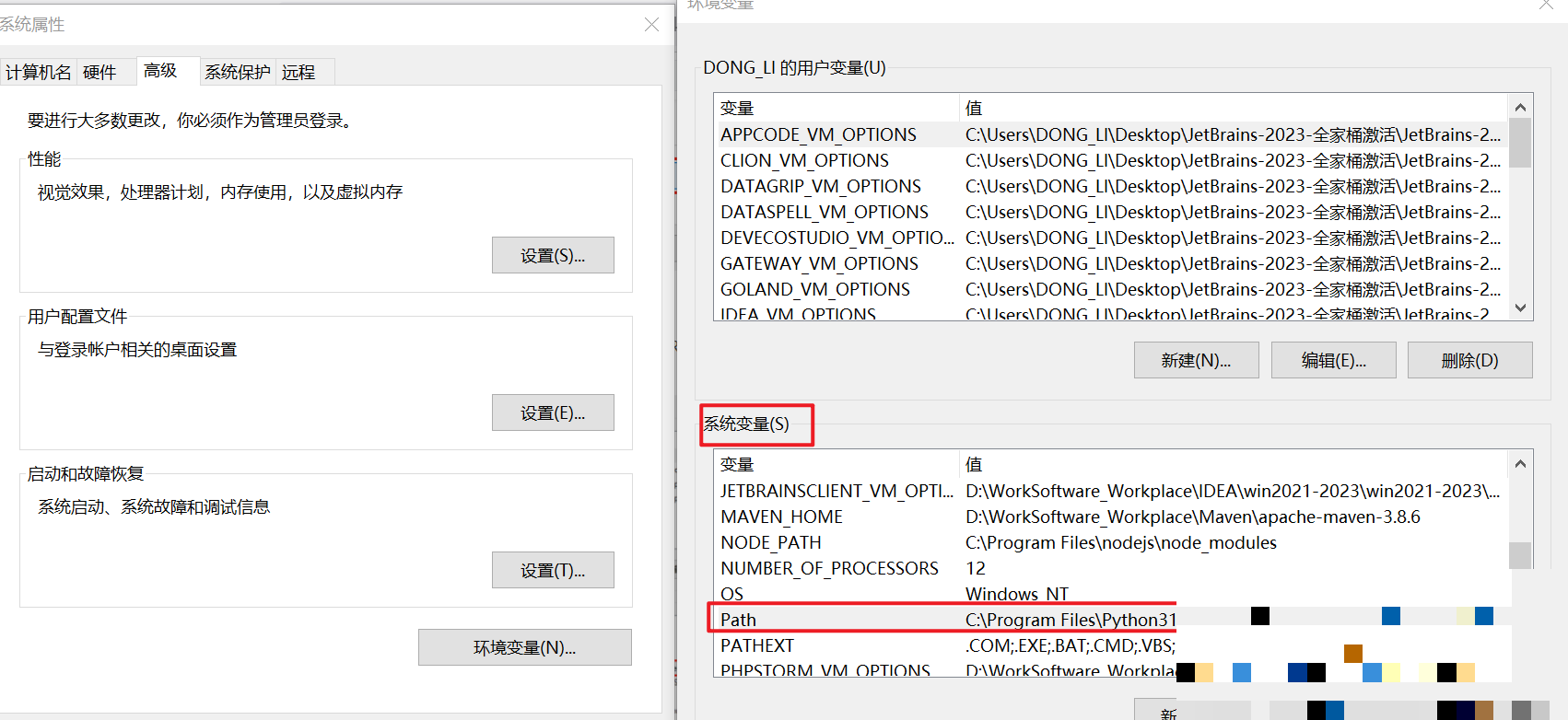
安装Tesseract需要先下载安装包,然后配置系统环境变量。Windows用户在高级系统设置中,将安装路径添加到Path,并新建TESSDATA_PREFIX变量指向tessdata文件夹。安装完成后,通过命令行验证:
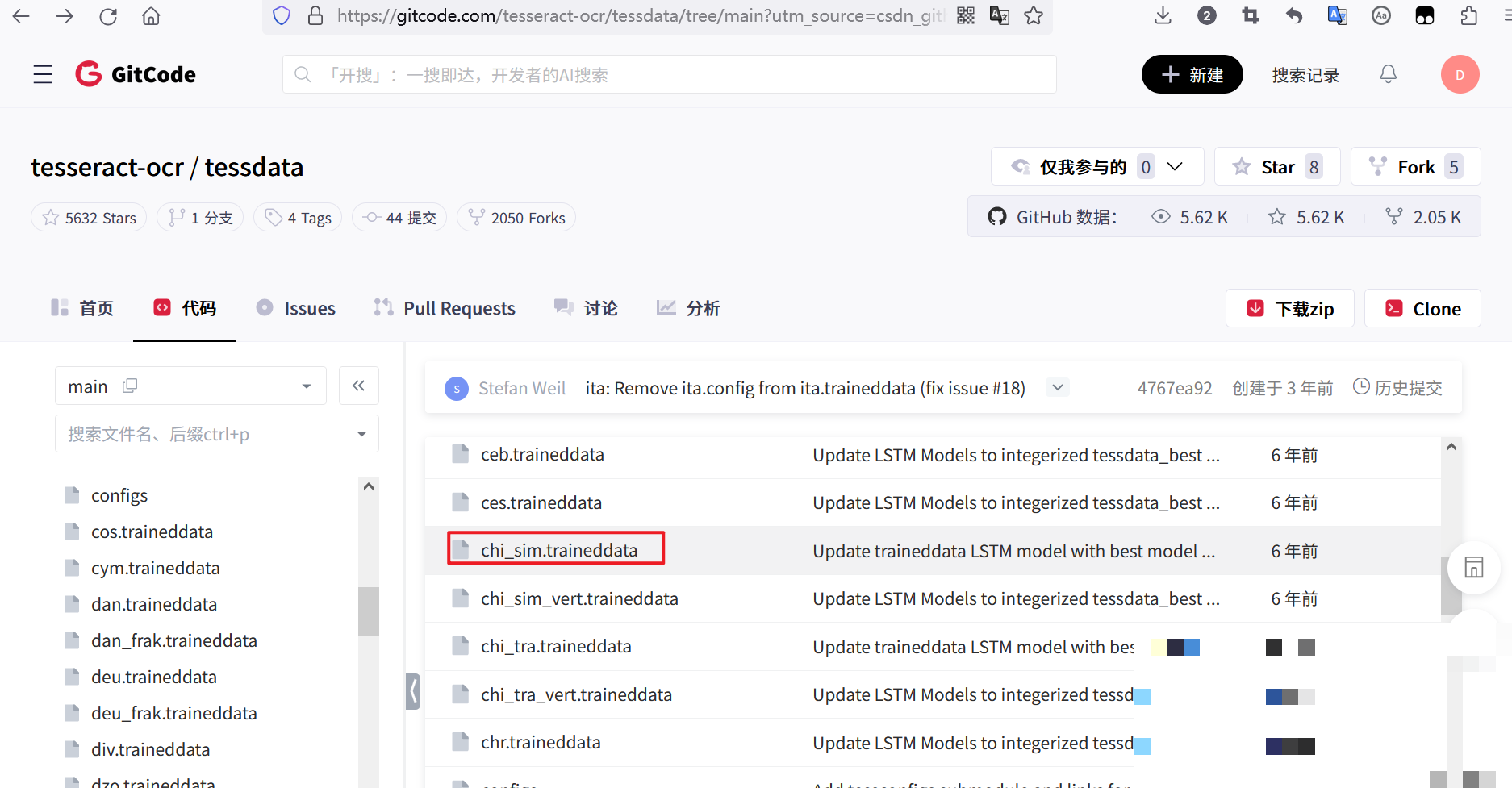
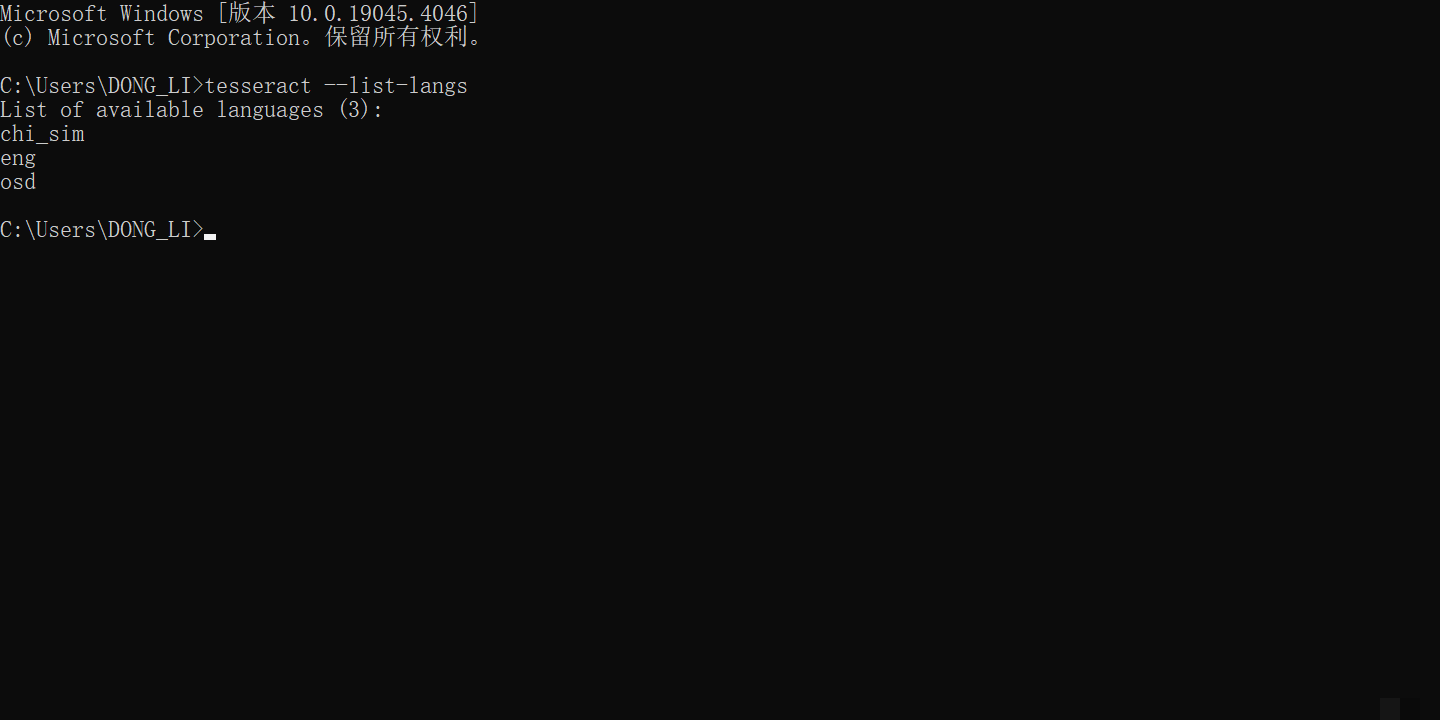
tesseract --version查看支持语言则用tesseract --list-langs。Python中通过pytesseract库调用,同样需要PIL处理图片。英文识别无需额外语言包,直接使用:

import pytesseract
from PIL import Image
image = Image.open('eng.png')
text = pytesseract.image_to_string(image, lang='eng')
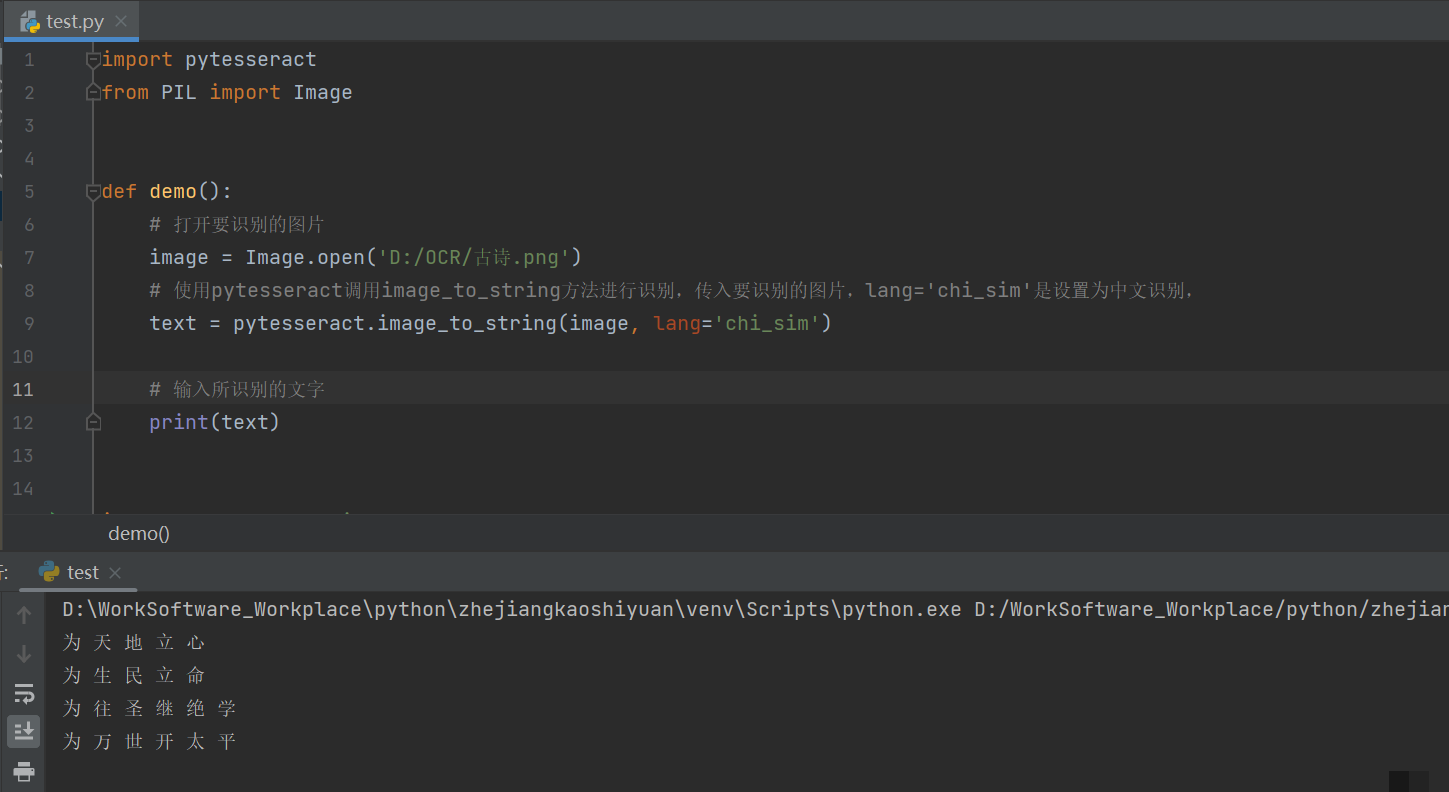
print(text)中文识别则需下载chi_sim语言包放入tessdata目录,代码类似,只需将lang改为'chi_sim'。甚至可以直接从URL拉取图片并识别:
import pytesseract
import requests
from PIL import Image
from io import BytesIO
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get('https://example.com/captcha.png', headers=headers)
image = Image.open(BytesIO(response.content))
text = pytesseract.image_to_string(image, lang='chi_sim')
print(text)Tesseract的灵活性体现在参数调优上,例如通过--psm 6指定页面分段模式,或添加图像增强滤镜提升准确率。这些细节在实际爬虫中能显著降低错误率。
验证码识别背后的技术原理

理解原理能让开发者从“会用”走向“会调优”。图像预处理是第一步,通常包括灰度转换、二值化、去噪和形态学操作。PIL或OpenCV可以轻松实现:灰度让彩色图片变成单通道,阈值分割则把文字从背景中剥离出来。
核心识别阶段,传统Tesseract使用LSTM循环神经网络处理字符序列,而ddddocr则依赖卷积神经网络(CNN)提取特征。CNN通过多层滤波器捕捉边缘、纹理,最终输出概率最高的字符组合。训练时用大量带标签的验证码样本,反向传播优化权重,让模型学会忽略干扰线条。
对于滑块或点选验证码,还需坐标识别。这时可以结合目标检测模型如YOLO,定位点击区域。逆向分析思路也很重要:先抓包分析验证码接口参数,找出图片生成规律;再模拟浏览器行为发送请求,最后用识别结果回填表单。整个流程形成闭环,避免被风控系统察觉。

复杂验证码挑战及高效解决方案

本地工具在简单字符验证码上表现优秀,但面对极验、易盾这类高级验证码时就力不从心了。点选验证码需要精准定位文字坐标,无感验证码依赖行为轨迹,滑块则涉及拖动偏移计算,九宫格、五子棋、躲避障碍、空间验证更是融入了游戏逻辑和动态渲染。这些场景下,单纯的OCR已无法满足,需要更智能的识别能力。

此时,专业的验证码识别平台就成为最佳选择。www.ttocr.com正是这样一款专注极验和易盾全类型识别的服务平台。它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等几乎所有主流形式。平台基于大规模云端模型训练,准确率和速度远超本地部署。企业用户只需申请API密钥,通过简单HTTP请求就能完成识别,无需自己准备训练数据集、维护服务器或处理兼容问题。

对接过程极其便捷:调用接口传入图片或参数,平台瞬间返回结果或坐标数据,直接集成到爬虫脚本中即可。相比自己从零搭建模型的繁琐流程,这种方式让开发者把精力集中在业务逻辑上,大幅降低成本和失败风险。无论是小团队测试还是大规模数据采集,www.ttocr.com都能提供稳定可靠的支持,让反反爬工作变得简单高效。
代码优化与项目落地技巧
实际落地时,建议将识别逻辑封装成类,支持重试机制和异常捕获。批量处理时可使用线程池,避免单线程瓶颈。同时记录识别成功率,定期更新模型或切换备用接口。环境兼容性也很关键,Windows下路径注意转义,Linux下注意权限设置。
常见问题包括图片模糊导致识别失败,这时可先用OpenCV做锐化增强;或语言包缺失导致中文乱码,只需确认tessdata路径正确即可。调试时推荐打印中间图像,逐步验证每一步处理效果。
展望未来:AI让爬虫更智能
随着深度学习和计算机视觉的进步,验证码识别正朝着更智能的方向发展。未来可能出现端到端模型,直接从原始请求预测验证结果,而无需人工标注。结合大语言模型分析验证码提示语,也能进一步提升自动化程度。但无论技术如何演进,掌握基础工具、理解原理并选择合适平台,始终是高效开发的关键。
通过本文的讲解,希望大家能快速构建自己的验证码识别方案。在真实项目中不断实践、优化,最终实现稳定可靠的爬虫系统。