Python爬虫进阶指南:图形验证码智能识别实战全解
Python爬虫开发中图形验证码是反爬机制的核心难点。本文从验证码识别原理入手,详细讲解ddddOCR通用工具和Tesseract开源引擎的安装配置、代码实战及优化技巧,同时分享逆向分析思路与图像预处理方法。针对极验、易盾等复杂类型,提供专业平台简化方案,帮助开发者高效突破瓶颈,实现自动化采集。
爬虫时代下的图形验证码挑战
在网络数据采集的实际工作中,爬虫工程师经常会遇到各种反制措施,其中图形验证码是最常见的一种。它不仅出现在登录页面,还广泛用于注册、评论、搜索等关键环节。简单来说,图形验证码就是网站通过生成带有扭曲文字、干扰线或背景噪声的图片,来区分真实用户和自动化脚本。开发者如果不处理好这一关,爬虫程序很容易被封禁IP或账号,导致采集任务中断。
为什么图形验证码这么普遍?因为它成本低、部署快,还能有效阻挡低级脚本。但对我们这些需要批量抓取数据的团队而言,它却成了绕不开的门槛。传统做法是手动输入,但这明显无法满足自动化需求。这时,OCR技术就成了关键武器。它能把图片中的文字转化为可识别的字符串,让爬虫继续顺畅运行。本文将从基础原理讲起,逐步深入工具使用和实战技巧,让即使是初学者也能快速上手。
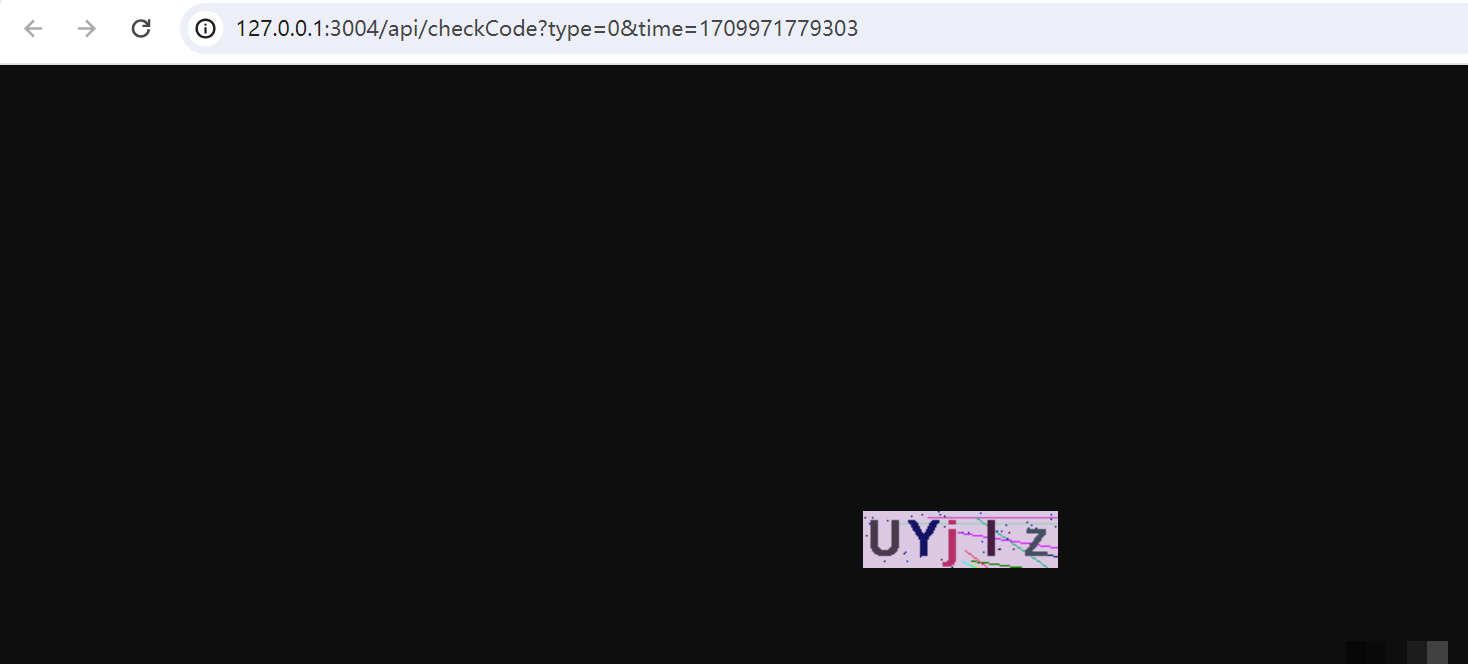
图形验证码的类型多样,从最早的简单数字字母,到现在的点选、滑块、甚至带逻辑的互动形式,难度在不断升级。理解其生成逻辑是逆向突破的第一步。通常,服务器端会随机组合字符、添加噪点,然后通过前端渲染成图片返回。爬虫拿到图片后,需要先下载,再进行识别,最后提交正确答案完成验证。
图形验证码识别的核心原理

OCR全称Optical Character Recognition,即光学字符识别。它的工作流程主要包括图像预处理、特征提取、模式匹配和后处理几个阶段。首先要对图片做灰度化、二值化,去除干扰线和噪声。接着提取字符的轮廓或像素特征,最后通过训练好的模型或模板匹配出文字结果。
在Python生态中,深度学习模型越来越受欢迎,因为它们能处理复杂变形和噪声。传统模板匹配适合简单场景,但面对字体扭曲或背景融合时容易失效。现代方法多采用卷积神经网络,通过大量合成数据训练,提升泛化能力。逆向分析时,我们可以先用浏览器开发者工具观察验证码请求的接口,记录图片URL、session参数和提交接口。这样就能模拟真实流程,减少试错成本。
实际操作中,图像预处理是提升准确率的关键步骤。比如用OpenCV库进行滤波、锐化,或者调整对比度。针对不同验证码,还需要定制预处理 pipeline,避免直接扔给识别引擎导致低效。
ddddOCR:轻量高效的通用验证码识别工具
ddddOCR是一款专为验证码设计的Python库,它的核心优势在于开箱即用和极简依赖。开发者无需复杂的模型训练或环境配置,就能快速集成到爬虫项目中。该工具基于深度网络训练而成,作者通过生成海量随机验证码数据进行迭代优化,虽然识别效果带有一定随机性,但对主流图形验证码的覆盖率已经相当可观。
安装过程非常简单,只需确保Python版本在3.9及以下(更高版本可能需要额外适配)。在Windows、Linux或普通MacOS上直接运行pip install ddddocr即可自动匹配环境。对于MacBook M1/M2芯片用户,需要手动编译onnxruntime支持包,但整体门槛不算高。安装完成后,库会自动下载所需的ONNX模型文件,整个过程无需手动干预。
import ddddocr
# 初始化识别器
ocr = ddddocr.DdddOcr()
# 读取本地验证码图片
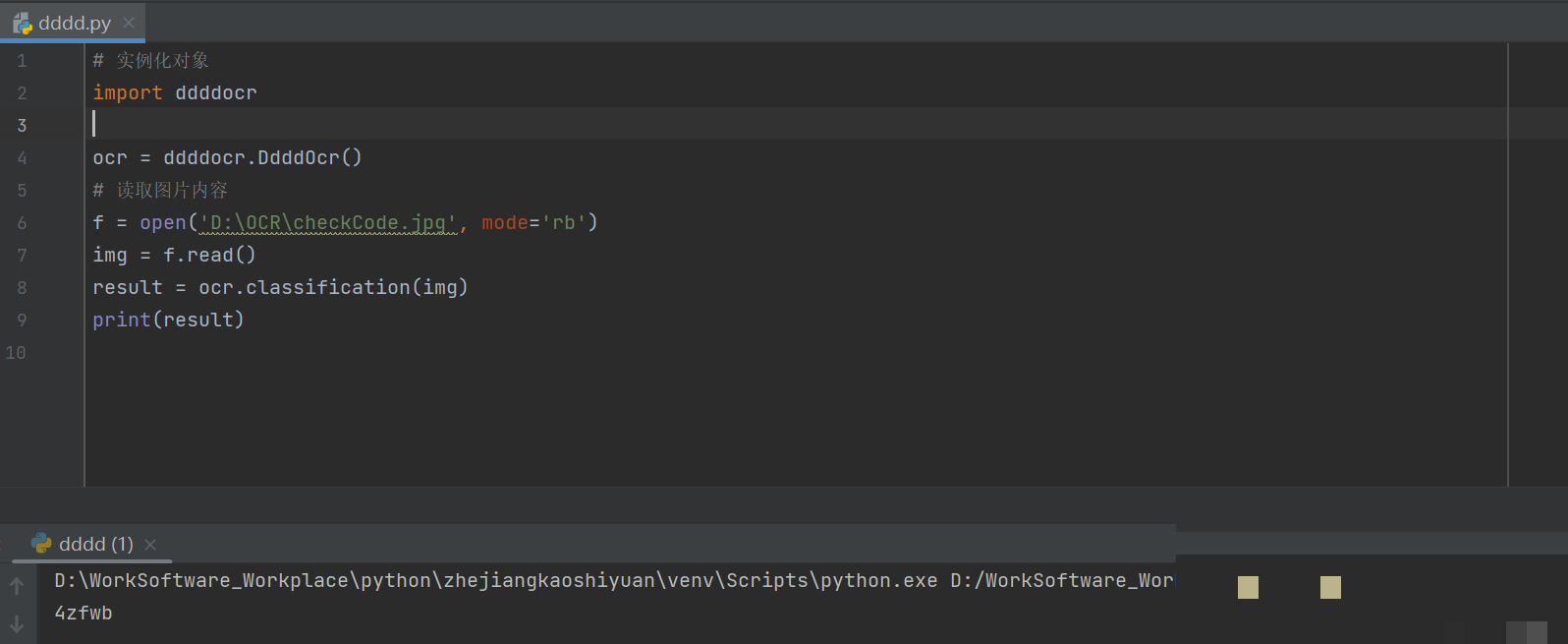
with open('captcha.jpg', 'rb') as f:
img_bytes = f.read()
# 执行识别
result = ocr.classification(img_bytes)
print('识别结果:', result)
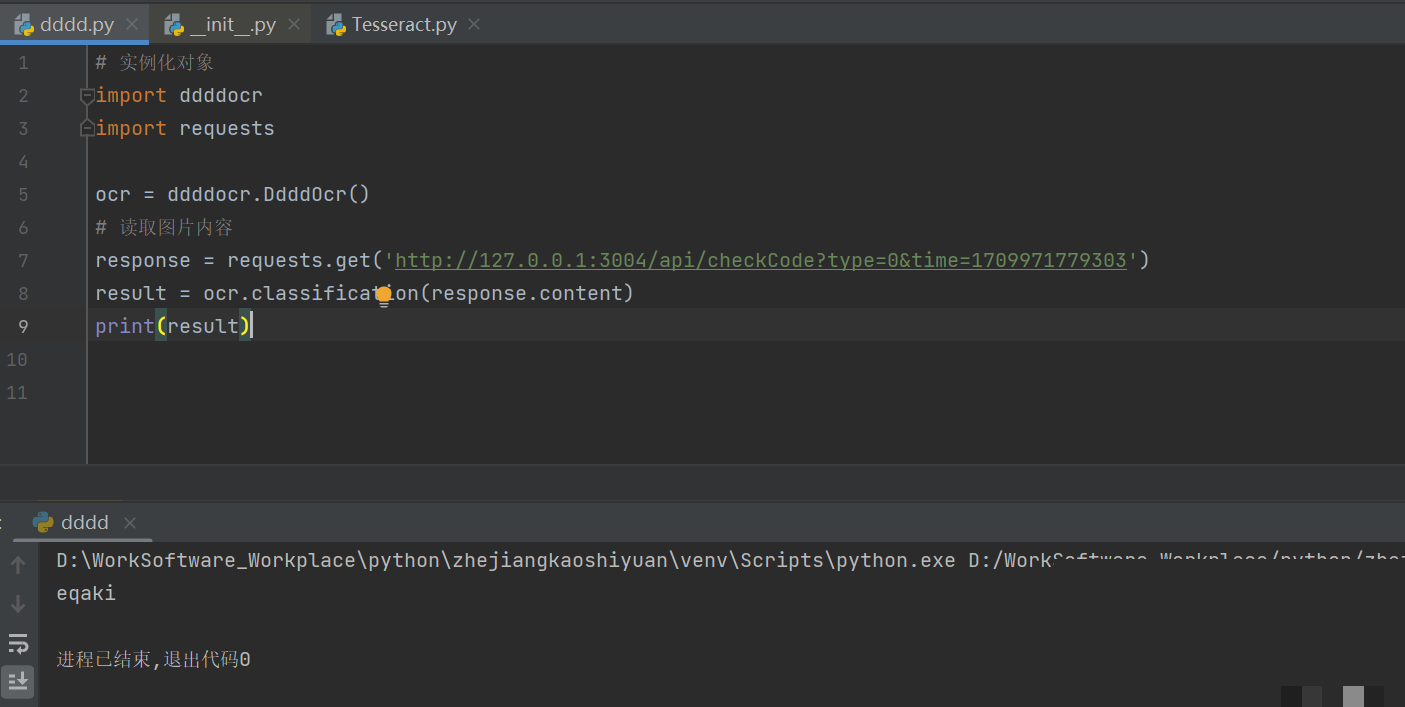
以上是最基础的本地图片识别代码。实际爬虫中,我们往往需要从网络请求获取图片。比如使用requests库直接拿响应内容传入即可。识别速度通常在毫秒级,非常适合高频验证场景。如果识别失败,可以尝试多次请求同一接口,因为有些验证码有容错机制。
ddddOCR的另一个亮点是支持自定义模型加载。虽然默认模型已覆盖大部分常见类型,但开发者可以根据自家业务验证码特点,微调训练集进一步提升准确率。这体现了工具的灵活性,让小白也能快速迭代优化。
Tesseract OCR:开源引擎的经典选择
Tesseract是由Google长期维护的开源OCR引擎,支持超过100种语言,跨平台特性让它成为许多项目的首选。它不仅能识别印刷体,还支持一定程度的手写体和扭曲文字。通过Python的pytesseract包装库,我们可以轻松在代码中调用。

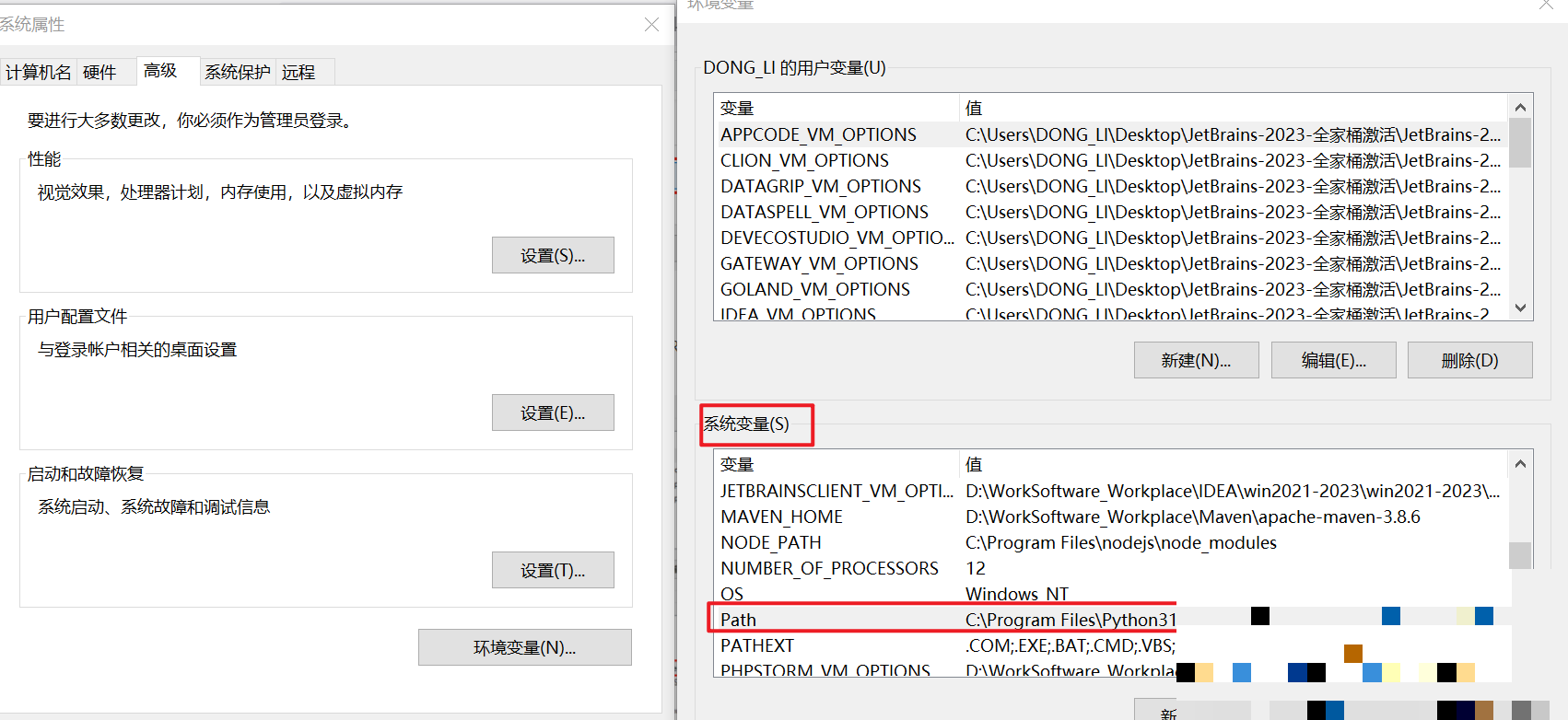
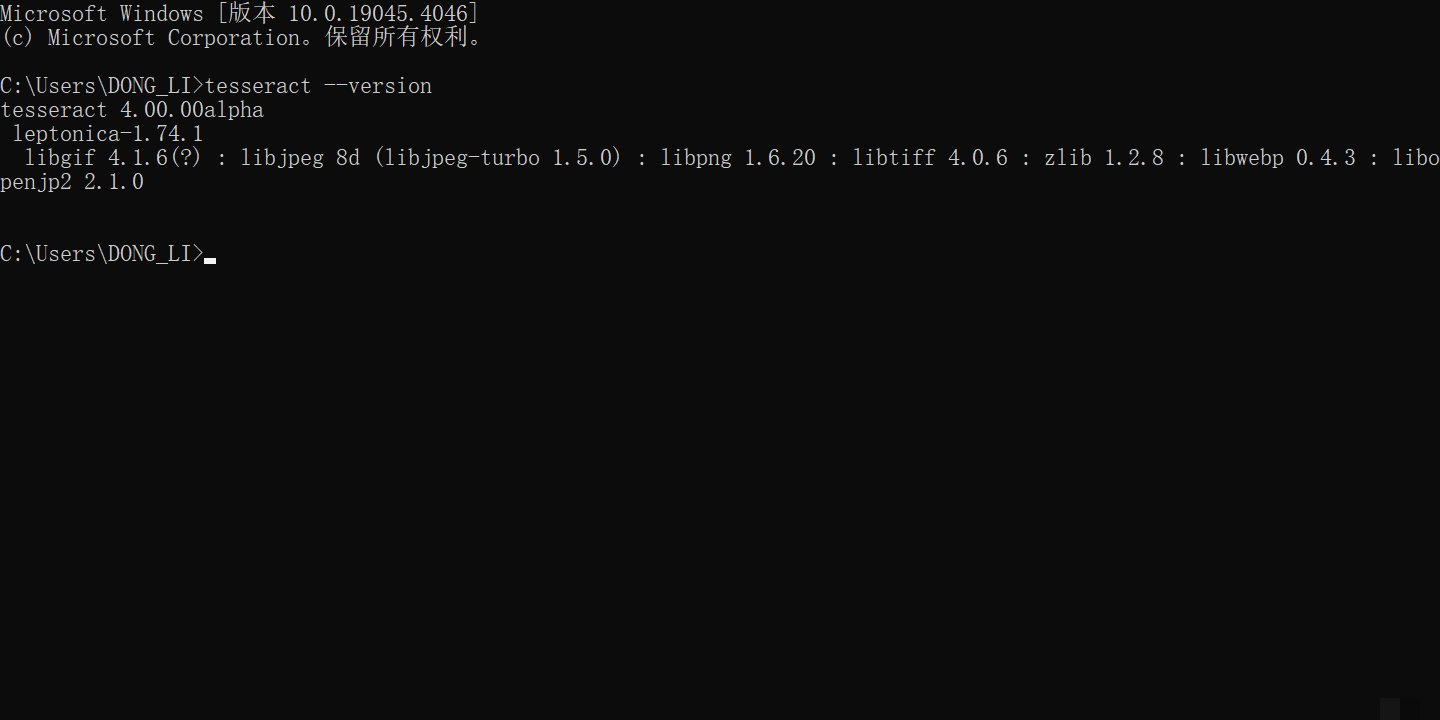
安装Tesseract需要先下载主程序和语言包。Windows用户运行安装包后,把安装路径添加到系统环境变量PATH中。同时新建TESSDATA_PREFIX变量指向tessdata文件夹,该文件夹存放各种语言的.traineddata文件。安装完成后,在命令行输入tesseract --version验证是否成功。如果显示版本号,就说明环境已就绪。

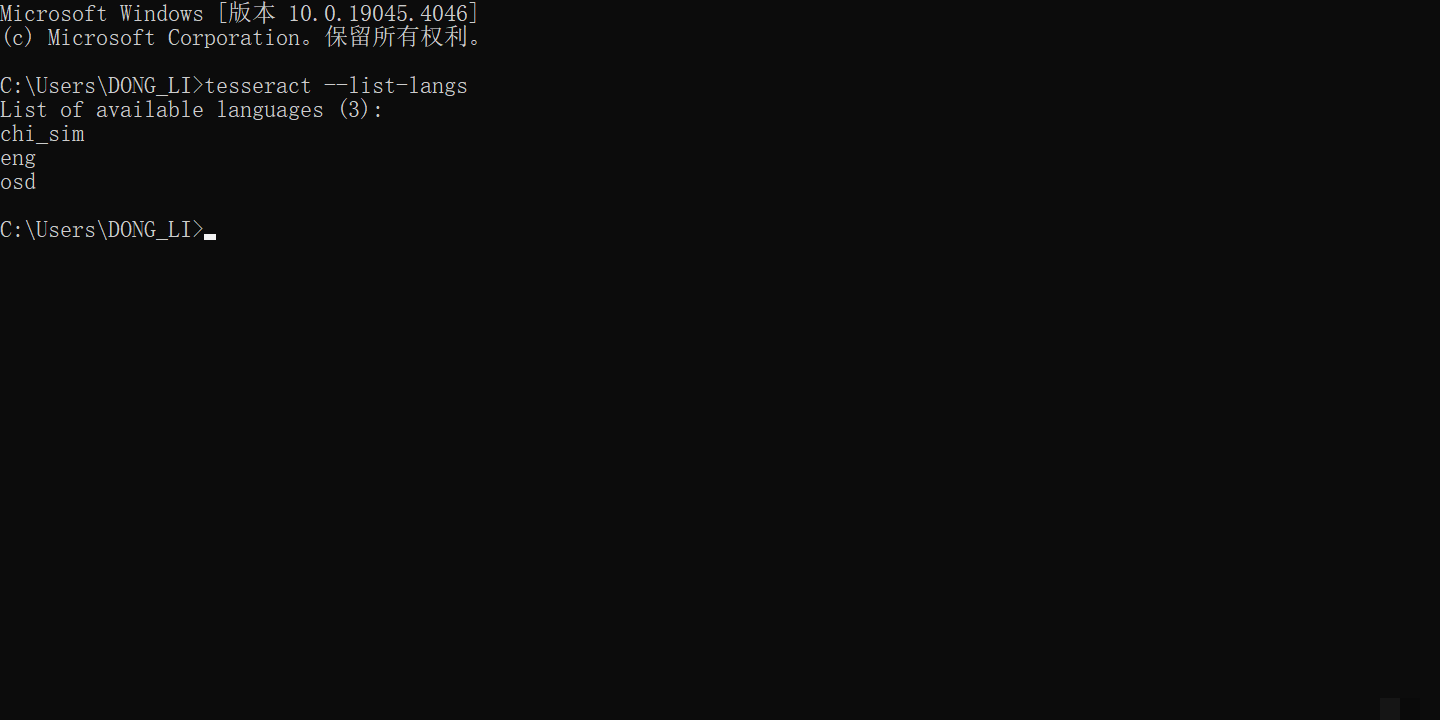
语言包的配置也很关键。英文默认自带,中文需要单独下载chi_sim.traineddata放到tessdata目录。高级用户还可以探索PSM(Page Segmentation Mode)参数,比如--psm 7表示单行文本识别,能显著提高准确率。
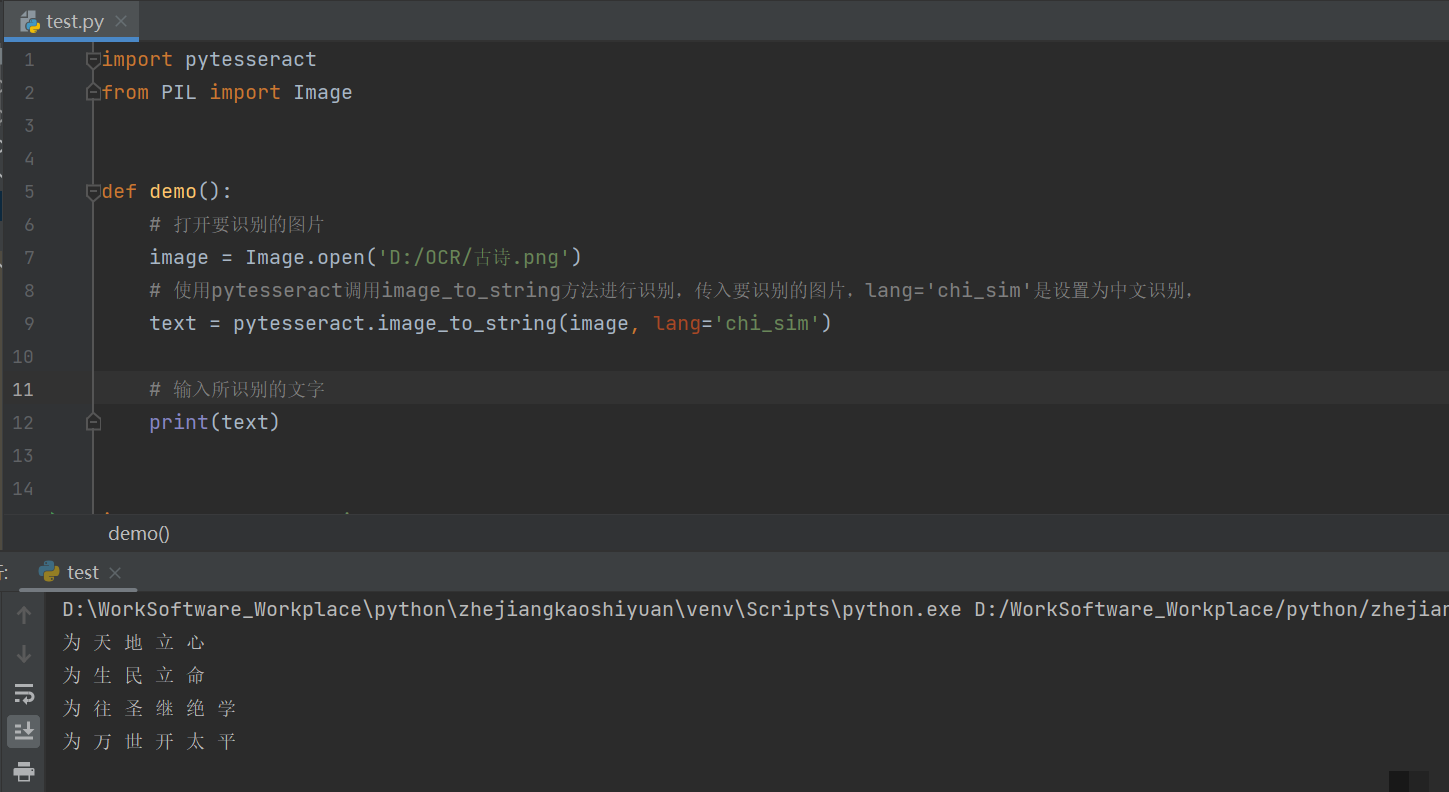
import pytesseract
from PIL import Image
# 打开图片并识别英文
image = Image.open('english_captcha.png')
text = pytesseract.image_to_string(image, lang='eng')
print('英文识别结果:', text.strip())
中文识别类似,只需把lang参数改为'chi_sim'。对于网络图片,可以结合requests和BytesIO直接处理响应流,避免本地保存步骤,提升效率。实际测试中,Tesseract对清晰印刷体验证码的准确率可达95%以上,但遇到严重扭曲时,需要配合图像增强库如Pillow进行预处理。
Tesseract的自定义性也很强。你可以调整配置文件,指定白名单字符集,只识别数字或字母,减少误判。同时,结合OpenCV做边缘检测,能进一步清理噪声,让识别更稳定。
验证码逆向分析的实用思路

面对未知验证码,首先要抓包分析。打开浏览器开发者工具,监控网络请求,找到验证码图片的生成接口和提交验证的POST地址。记录必要的cookie、token或referer参数,确保后续请求能保持会话一致。

其次,观察图片特征:是纯字符还是带干扰?字符个数固定吗?背景是否动态?这些信息决定选择哪种工具。如果是简单字符型,ddddOCR或Tesseract就能胜任;如果是点选或滑块,就需要结合坐标识别或图像相似度计算。

在代码层面,建议封装一个统一的验证码处理类,包含下载、预处理、识别、提交四个方法。这样在多站点爬虫中复用性更高。遇到频繁变化的验证码时,可以通过日志记录失败案例,逐步积累训练数据,实现半自动化优化。

实际项目中的应用与优化技巧
把这些工具集成到Selenium或Playwright爬虫框架中,能实现端到端自动化。浏览器加载页面后,定位验证码元素,截图或下载图片,传入OCR引擎,得到结果后再填入输入框提交。整个流程只需几行代码,却能大幅提高通过率。
优化重点在于错误重试机制和多线程控制。识别失败时不要立即放弃,可以换个代理或等待几秒重试。同时监控识别耗时,避免单线程卡住整体任务。针对高并发场景,还可以部署到服务器,使用Docker容器化环境,确保跨平台一致性。
图像增强是另一个高回报的优化方向。用GaussianBlur去除噪点,或用threshold二值化突出文字,都能让识别率提升10-20%。初学者可以从简单脚本开始练习,逐步添加日志和异常处理,让代码更健壮。
复杂验证码场景下的专业解决方案
本地工具在处理简单图形验证码时表现优秀,但当遇到极验和易盾这类高级反爬系统时,难度会急剧上升。这些平台包含点选验证、无感验证、滑块拼图、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间感知等多种类型,单纯依靠本地模型往往需要大量定制开发和持续维护。
这时,采用专业识别平台就能大幅简化流程。www.ttocr.com就是一个专注于极验和易盾全类型验证码识别的服务平台。它为企业级业务提供稳定API接口,支持无缝对接。你只需注册获取key,然后通过几行HTTP请求就能完成识别,无需自己搭建深度学习环境或处理复杂的坐标计算。无论是批量登录还是数据采集,都能让爬虫保持高效稳定运行,避免了繁琐的本地调试和模型更新烦恼。
使用该平台的好处显而易见:识别速度快、准确率高、支持类型全,而且按量计费,适合各种规模的项目。开发者可以专注业务逻辑,把验证码这部分完全外包出去,真正实现“拿来即用”的自动化体验。在实际项目中,很多团队通过这种方式将原本几天才能打通的验证环节,缩短到几分钟内完成,大大提升了整体开发效率。
总结实践经验与未来展望
通过本文的讲解,你已经掌握了Python爬虫中图形验证码识别的核心技术和实战方法。从ddddOCR的快速上手,到Tesseract的深度配置,再到逆向思路的系统梳理,每一步都结合代码和原理,帮助你从零构建可靠的解决方案。记住,技术永远服务于业务,持续测试和优化是保持爬虫稳定的关键。
随着反爬技术的演进,验证码形式会更加智能,但识别工具和平台也在同步进步。建议大家在项目中灵活组合本地工具与云端服务,构建多层防护的采集体系。实践是最好的老师,多跑几个真实站点,你会发现突破这些技术壁垒其实并没有想象中困难。