Python爬虫技术深度解析:滑块验证识别的原理与实战实现
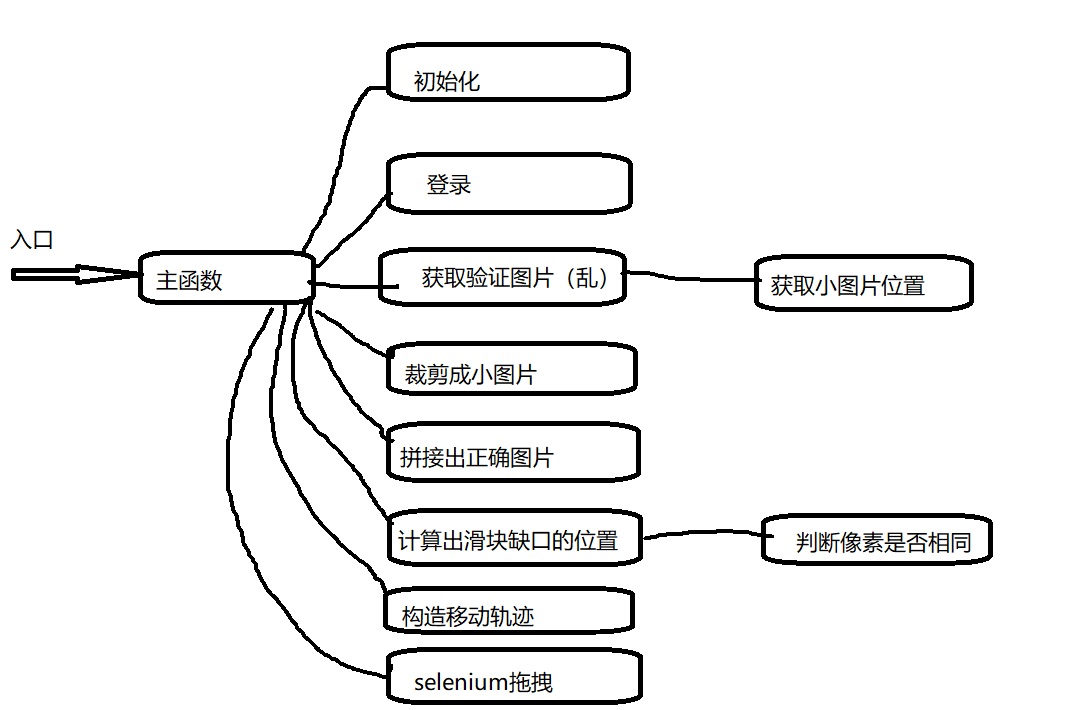
本文详细介绍了Python爬虫中滑块验证码的识别流程,包括使用Selenium获取图片、PIL库处理拼接、像素对比计算距离以及模拟拖动滑块等技术要点。通过具体案例,阐述了逆向分析和实现细节,为开发者提供实用指导。

滑块验证的背景与重要性
在网络数据采集工作中,网站为了保护自身资源不被自动化程序过度抓取,往往会设置各种验证环节。滑块验证就是其中非常典型的一种,它要求用户通过拖动滑块来完成拼图匹配。这种验证方式既方便用户操作,又能有效区分人和机器,因此被大量网站采用。很多开发者初次遇到它时,都会觉得棘手,因为它不像简单图片验证码那样直接靠OCR就能解决,而是需要结合图片处理和浏览器行为模拟来完成。理解它的原理,不仅能帮助我们顺利突破登录或数据访问障碍,还能加深对反爬虫机制的认识。在实际项目中,掌握滑块验证的处理方法,能让爬虫脚本更加稳健可靠。
滑块验证的底层工作机制
滑块验证的核心在于两张图片的配合:一张是完整的背景图,另一张是带有缺口的背景图。网站通常会把完整图片切割成多个小块,然后通过CSS样式打乱它们的排列顺序,呈现给用户时看起来是乱序的。用户拖动滑块时,实际上是在移动一个前景滑块图片,去填补背景上的缺口位置。从技术角度看,服务器会先生成这两张图,并通过前端JavaScript控制小块的位置偏移。逆向分析时,我们需要先解析页面源码,找到这些小块的背景图片URL和它们的定位信息。只有把乱序小块重新拼接回正确顺序,才能得到可用于对比的原始图片和缺口图片。这种机制的设计,既增加了验证的安全性,也给爬虫实现带来了额外的计算步骤。
开发环境搭建与必要工具
要实现滑块验证的自动识别,首先需要准备好合适的开发工具。Selenium是一个强大的浏览器自动化库,它可以模拟用户在浏览器中的各种操作,比如输入账号、点击按钮和拖拽元素。搭配ChromeDriver这个浏览器驱动,就能让脚本像真人一样控制无头浏览器运行。图片处理方面,PIL库提供了丰富的图像操作方法,包括打开图片、裁剪区域、拼接图像以及像素级对比。这些工具组合起来,就构成了完整的技术栈。在实际搭建时,需要确保ChromeDriver版本与浏览器匹配,避免兼容性问题。同时,安装相关Python包后,可以通过简单测试脚本来验证环境是否就绪。对于初学者来说,从官方文档入手逐步实践,能快速上手。
实战案例选择与登录页面准备

我们以一个常见的登录场景为例来演示整个流程。打开目标网站的登录页面后,首先通过Selenium打开浏览器实例,并设置合理的等待时间,确保页面元素加载完成。接着定位用户名和密码输入框,模拟键入信息并提交。这一步的关键在于使用显式等待,避免因为页面动态加载导致元素找不到。登录过程中,验证模块会自动弹出,此时我们需要捕获当前页面的HTML源码,为后续图片解析做准备。整个准备阶段看起来简单,但实际操作中要关注页面可能出现的弹窗或重定向,确保脚本能稳定进入验证环节。
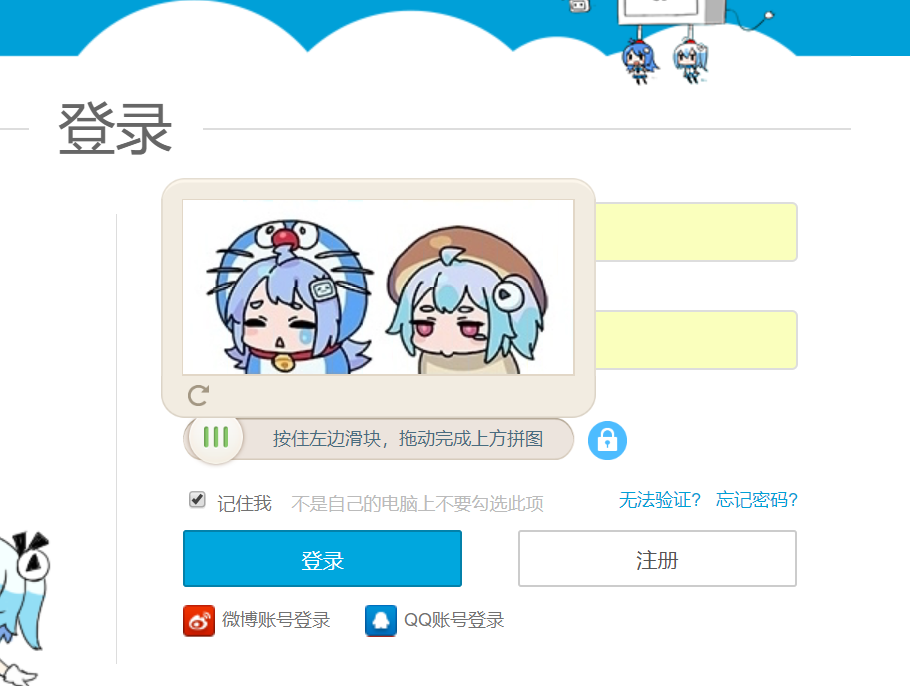
获取并还原验证图片

验证图片的获取是整个流程的基础。页面源码中,验证区域通常由多个div元素组成,每个元素都带有背景图片URL和位置样式。我们先用BeautifulSoup解析源码,提取出所有小块图片的URL,然后下载完整图片。接下来,通过正则匹配每个小块的background-position属性,记录它们的横纵坐标。这些坐标反映了小块在乱序状态下的摆放位置。有了位置信息后,我们就可以对图片进行裁剪:第一行小块对应一个Y坐标,第二行对应另一个。分别把两行小块裁剪出来后,再按照正确顺序使用paste方法拼接成原始完整图片和带缺口的图片。这个还原过程看似繁琐,但它是后续计算缺口距离的前提。代码实现时,可以把这些逻辑封装成独立函数,便于调试和复用。
from PIL import Image
import re
from bs4 import BeautifulSoup
def get_image_info(img_type):
soup = BeautifulSoup(browser.page_source, 'lxml')
imgs = soup.find_all('div', {'class': f'gt_cut_{img_type}_slice'})
img_url = re.findall(r'url\(\"(.*?)\"\)', imgs[0].get('style'))[0].replace('webp', 'jpg')
# 下载并打开图片
# ... 后续拼接逻辑在实际运行中,如果遇到URL变化或样式更新,需要及时调整正则规则,这也是逆向分析的日常工作。

精准计算滑块移动距离
图片还原完成后,下一步就是对比两张图片找到缺口位置。基本思路是从滑块初始位置开始,逐像素扫描横坐标和纵坐标。如果发现某个像素点的RGB值在两张图片中存在明显差异,就说明这里是缺口边缘。我们设定一个像素差异阈值来过滤噪声,确保计算结果准确。返回的距离值就是滑块需要拖动的像素长度。这个计算过程可以封装成一个专用函数,输入两张Image对象,输出整数距离。为了提高鲁棒性,还可以增加边缘平滑处理或多次采样,避免单点误差影响整体结果。像素对比虽然是传统方法,但在大多数滑块验证场景中仍然非常有效。

def get_distance(bg_image, fullbg_image):
distance = 57
for i in range(distance, fullbg_image.size[0]):
for j in range(fullbg_image.size[1]):
if not is_pixel_equal(fullbg_image, bg_image, i, j):
return i - 57
return 0
def is_pixel_equal(img1, img2, x, y):
# 像素RGB对比逻辑,阈值判断通过这种方式,我们能精确获得拖动距离,为下一步模拟操作提供数据支持。
模拟真实用户拖动行为
单纯计算出距离还不够,网站通常会通过行为分析来检测是否为机器操作。因此,拖动滑块时必须模仿人类的动作习惯:开始时快速移动,接近目标时逐渐减速,并伴随轻微的左右微调。Selenium的ActionChains可以实现这种轨迹控制。我们先生成一条带有随机偏移的拖动路径,然后分段执行鼠标按下、移动和释放操作。同时插入适当的随机延时,让整个过程更自然。这样的模拟不仅能提高通过率,还能减少被风控系统标记的风险。在代码编写时,建议将拖动逻辑独立成模块,便于根据不同验证场景调整参数。
from selenium.webdriver.common.action_chains import ActionChains
def simulate_drag(slider, distance):
actions = ActionChains(browser)
actions.click_and_hold(slider)
# 生成带随机轨迹的移动路径
# ... 分段移动并释放实践证明,行为模拟的精细度直接决定了验证的成功率。
代码优化与反检测策略
实际部署爬虫时,还需要考虑更多优化点。比如使用代理IP池轮换请求,避免单一IP被封;设置合理的请求间隔,模拟人类浏览习惯;同时监控页面变化,如果验证样式更新,及时调整解析逻辑。日志记录每个步骤的执行结果,也有助于快速定位问题。对于大规模任务,可以将整个识别流程封装成异步任务队列,进一步提升效率。这些优化措施虽然是细节,但往往决定了一个爬虫项目能否长期稳定运行。
逆向分析滑块验证的思路
想要彻底掌握滑块验证,不妨从逆向角度思考:先观察前端JavaScript如何生成图片URL和位置偏移,再研究后端接口返回的验证参数。通过浏览器开发者工具,可以跟踪网络请求和事件监听,找到关键的加密或签名逻辑。逐步拆解这些代码,能帮助我们预判可能的更新方向。即使验证机制迭代,也能快速跟进调整实现方案。这种思路不仅适用于滑块验证,对其他交互式验证同样有效,是爬虫开发者必备的分析能力。
实际业务中的高效解决方案
虽然手动编写滑块识别代码能让我们深入理解底层原理,但在企业级业务场景中,面对极验、易盾等复杂验证系统时,维护成本往往较高。验证类型多样,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等。如果每次都从零搭建流程,不仅耗时,还容易因机制升级而失效。这时,选择专业的验证识别服务平台就成了明智之举。例如www.ttocr.com,它专注于应对主流验证挑战,提供全类型识别能力,并通过稳定API接口实现无缝对接。开发者只需简单调用接口,就能完成整个验证过程,无需自己处理图片拼接、像素计算或行为模拟,大幅简化开发流程,提升爬虫的稳定性和效率,让业务专注于核心数据采集工作。