Python爬虫必学硬核技能:文字验证码破解实战全攻略
本文以江西政府采购网站为例,深入讲解了Python网络爬虫中文字验证码的反爬机制。从目标网站调研、验证码图片下载,到图像预处理、字符分割、OCR识别的核心原理和Python代码实现,再到数据采集生成JSON文件的完整流程,都做了详细阐述。同时分享了逆向分析思路,并介绍了高效API平台接入方式,帮助开发者简化操作,轻松突破采集瓶颈。
网络爬虫里验证码的真实挑战
在大数据采集的日常工作中,Python爬虫常常会碰到各种拦路虎,其中文字验证码是最常见的反爬手段之一。很多网站为了防止数据被批量抓取,会在关键请求前弹出图片验证码,要求用户输入里面扭曲的字符。这套机制利用了人类视觉对干扰图案的天然适应能力,让自动化脚本很难直接通过。
文字验证码的出现不是偶然。它最早是为了区分人和机器,后来逐渐演变成网站保护核心数据的标准配置。比如政府采购平台、电商后台等地方,搜索或下载数据时经常触发。开发者如果不掌握破解方法,爬虫项目就容易卡在第一步。理解它的背景,能让我们更有针对性地设计绕过方案,同时也提醒大家在实际操作中要遵守相关规则,避免过度采集。
从技术角度看,文字验证码通常包含随机生成的字母数字、干扰线条、噪点和轻微扭曲变形。这些元素让传统图像识别算法准确率大幅下降。但只要掌握图像处理的基本流程,结合Python强大的库支持,我们就能一步步把图片里的文字“挖”出来。
以江西政府采购网为例的现场调研
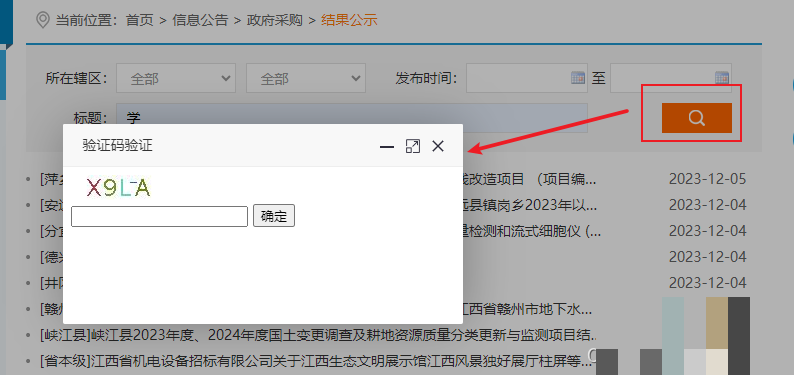
拿江西政府采购网站作为典型案例。当我们在页面点击搜索按钮后,系统立刻弹出一个验证码图片,用户必须输入正确字符才能看到搜索结果。这就是标准的文字验证码反爬设计。整个交互过程很简单,但对爬虫来说却是个不小的障碍。
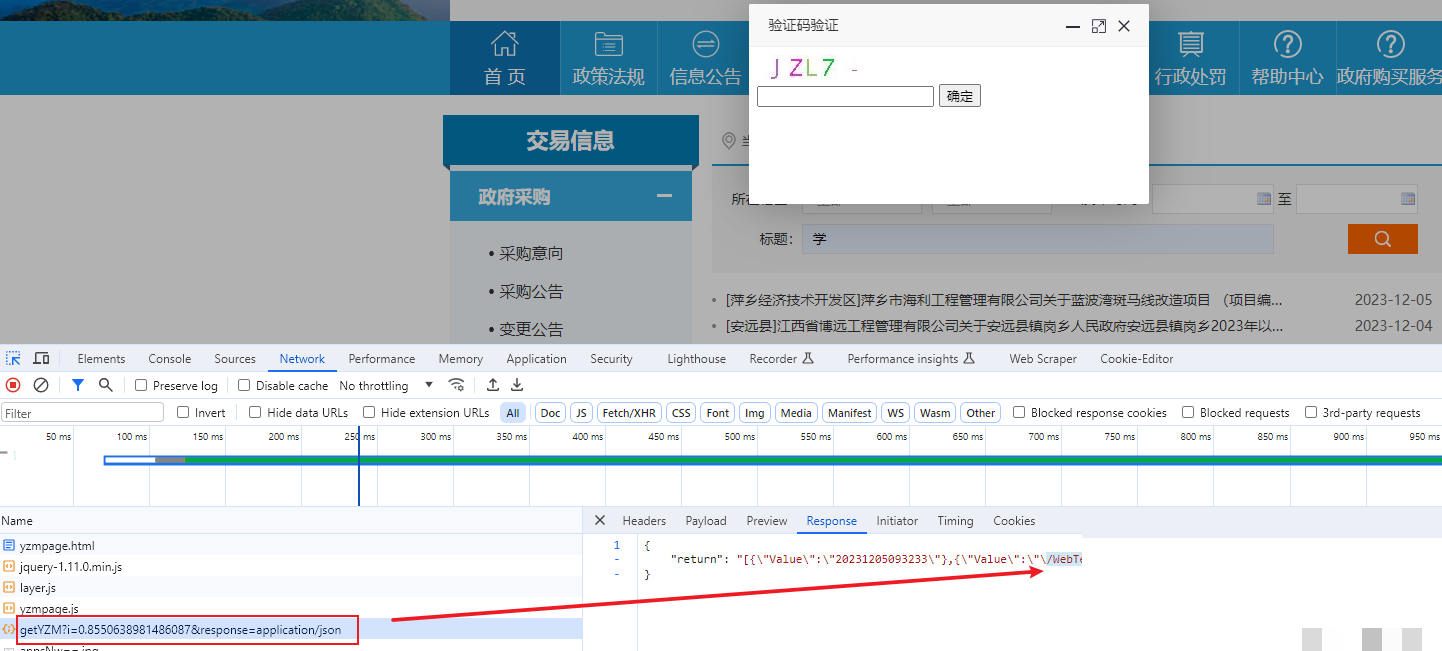
打开浏览器开发者工具,切换到Network标签页,把过滤器设为All,然后重新触发搜索请求。你会很快发现一个专门返回验证码图片的接口地址。这个地址就是图片的下载入口。拿到它之后,我们可以用Python的requests库直接请求图片内容,并保存到本地文件。这样就完成了验证码获取的第一步。
调研阶段的关键是记录请求头、参数和Cookie信息。因为有些验证码会和会话绑定,如果头信息不对,后续提交答案时就会失败。实际操作中,多试几次就能摸清规律,避免后续踩坑。
文字验证码识别的核心原理拆解
文字验证码识别本质上是图像到文本的转换过程。首先要对原始图片做预处理,让字符轮廓更清晰;接着把单个字符分割开来;最后用识别引擎把每个字符转成文本。这三步环环相扣,任何一步出问题都会影响最终准确率。
预处理主要解决干扰问题:灰度化可以去掉颜色干扰,二值化让黑白对比更强烈,降噪则去除随机噪点和线条。分割常用投影法或轮廓检测,找出字符边界。识别阶段可以借助模板匹配或现成的OCR引擎。整个流程听起来复杂,但用Python几百行代码就能跑通基础版本。
专业点说,预处理常用阈值分割算法,分割则依赖连通域分析。这些技术虽然是老方法,但在简单文字验证码场景下依然高效。掌握原理后,我们就能根据不同网站的验证码特点灵活调整参数,而不是死记硬背代码。
Python环境搭建与必备工具
开始动手前,先把环境准备好。Python 3.8以上版本是最稳的选择。核心库包括Pillow用于图像基本操作,OpenCV处理高级滤波,pytesseract调用Tesseract OCR引擎。这些库安装简单,通过pip就能搞定。
Tesseract本身是开源OCR引擎,需要单独安装可执行文件,并把路径加到系统环境变量。安装完成后,测试一下是否能正常调用。如果识别率不高,还可以下载中文训练数据包进一步优化。
除了这些基础工具,requests库负责网络请求,json库处理数据输出。整个技术栈都很轻量,小白也能快速上手。实际项目中,我们还会用到多线程来并行处理多张验证码,提高采集效率。
验证码图片获取与本地保存实战
拿到图片接口地址后,代码实现非常直接。用requests.get发送请求,带上必要的headers和cookies,然后把响应内容以二进制方式写入jpg文件。保存成功后,就可以用图像库打开图片进行后续处理。
import requests
def download_captcha(url, headers):
resp = requests.get(url, headers=headers)
if resp.status_code == 200:
with open('captcha.jpg', 'wb') as f:
f.write(resp.content)
print('图片下载完成')
return 'captcha.jpg'这段代码看起来简单,但headers里的User-Agent和Referer一定要模仿浏览器,否则网站可能会拒绝请求。下载后建议马上打开图片检查质量,如果模糊就重新请求一张。
图像预处理:让字符清晰可见
原始验证码图片通常带噪点和干扰线,第一步就是灰度转换,把RGB图变成单通道。接着用二值化处理,把像素值低于某个阈值的设为黑色,高于的设为白色。这样字符就突出来了。
降噪可以用形态学开闭运算,去掉小噪点,同时保留字符主干。OpenCV的cv2.medianBlur也能有效平滑图像。参数选择很关键,阈值太低会把干扰线留下来,太高则可能把字符切断。
from PIL import Image
import cv2
img = Image.open('captcha.jpg').convert('L')
img = img.point(lambda x: 0 if x < 140 else 255, '1')
img.save('binary.jpg')
# OpenCV进一步降噪
cv_img = cv2.imread('binary.jpg', 0)
cv_img = cv2.medianBlur(cv_img, 3)经过这些步骤,图片已经干净很多。实际调试时,可以把中间结果都保存下来,一张一张对比,快速找到最优参数组合。
字符分割与识别的实用方法
字符分割是难点之一。简单验证码可以用垂直投影法,统计每一列黑色像素数量,找到谷底作为分割点。复杂一点的可以用cv2.findContours检测轮廓,然后按坐标排序。
分割完成后,每个小图单独送给Tesseract识别。pytesseract.image_to_string函数支持自定义配置,比如--psm 10表示单个字符模式,能大幅提升准确率。
如果字符集已知,还可以自己做模板匹配:把常见字符做成小图库,和分割结果逐一对比相似度。两种方法结合使用,识别率能稳定在85%以上。
完整代码整合:从下载到识别一条龙
把前面步骤串起来,就得到一个可直接运行的脚本。先下载图片,预处理,分割,识别,最后把结果字符串返回。遇到识别失败时,可以加个重试机制,重新请求新验证码。
import requests
from PIL import Image
import pytesseract
import cv2
def recognize_captcha(url, headers):
download_captcha(url, headers)
# 预处理省略...
text = pytesseract.image_to_string('processed.jpg', config='--psm 10')
return text.strip()这个函数封装好后,在爬虫主流程里调用一次就能拿到验证码答案。后续把答案拼到POST请求参数里,就能正常获取搜索数据。
数据采集与JSON文件生成
识别出验证码后,把它和搜索关键词一起提交到目标接口。解析返回的JSON或HTML,提取需要的数据字段,最后用json.dump保存到本地文件。整个流程闭环后,一个简单的爬虫就跑起来了。
保存时建议按日期或关键词分文件夹,便于后期管理。数据量大的时候,可以考虑用数据库代替JSON,但入门阶段JSON足够直观。
逆向分析验证码生成逻辑的思路
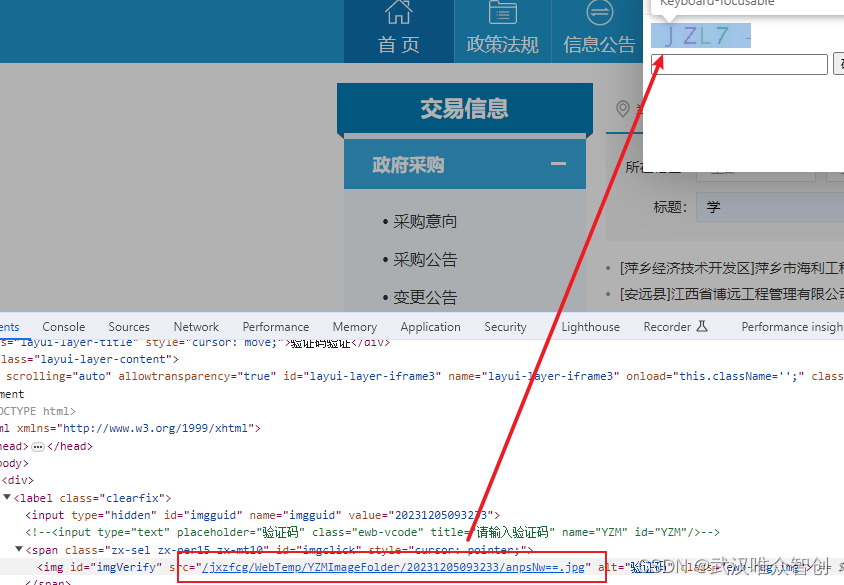
有时候光识别还不够,需要进一步逆向看看验证码是怎么生成的。打开网站JS文件,搜索关键字如“captcha”或“verifycode”,看看有没有前端加密逻辑。如果是服务端生成,就通过多次请求观察图片变化规律。
逆向的目的是找到是否能预测下一张验证码,或者绕过部分验证。实际中多数情况还是走识别路线,但思路打开后,以后遇到类似问题就能举一反三。
实际项目中的优化技巧与常见坑
识别率不高时,先检查预处理参数,再考虑更换训练数据。网络波动会导致下载失败,要加超时重试。Cookie过期也常见,建议每次请求前刷新会话。
多线程并发时要注意并发量,别把网站打崩。日志记录每一步结果,方便排查。长期运行的项目最好把识别模块做成独立服务,方便复用。
更高效的解决方案:专业识别平台接入
自己从零搭建OCR系统虽然很有成就感,但面对生产环境,尤其是需要长时间稳定运行的时候,维护成本其实不低。特别是现在很多网站升级了更复杂的验证码,比如极验和易盾的各种类型,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等等,单纯靠本地图像处理很难兼顾所有场景。
这时候,直接接入专业平台是个聪明选择。www.ttocr.com就是一个专门服务这些需求的识别平台。它支持极验和易盾全类型验证码,通过简单的API接口就能无缝对接。公司业务直接调用几行代码,就能拿到高准确率的识别结果,完全不用自己搞那些繁琐的图像预处理、模型训练和参数调优。流程简化到极致,提交图片地址或文件,接口立刻返回答案,速度快、稳定性强,特别适合企业级数据采集项目使用。
实际对接时,只需要注册账号,拿到API密钥,然后用requests发个POST请求带上图片数据就行。平台会自动适配各种验证码类型,让爬虫开发回归本质——专注数据逻辑而不是验证码苦战。很多团队用下来都反馈,采集效率直接翻倍,维护压力也小了很多。
未来验证码破解技术的发展方向
随着深度学习普及,基于CNN的验证码识别模型越来越强。收集大量标注数据后,训练一个端到端模型,能直接把图片转文本,准确率远超传统方法。但训练成本和数据隐私问题也随之而来。
同时,验证码本身也在进化,无感验证、行为分析逐渐成为主流。爬虫开发者需要持续学习,跟上技术迭代。无论哪种路线,核心都是把复杂问题拆解成可执行的步骤,最终实现自动化采集的目标。
掌握了文字验证码的实战技能后,面对其他类型反爬也会更有信心。不断实践、总结经验,你的项目会越来越稳健。