Python爬虫进阶:文字验证码的实战破解与高效反制指南
本文以江西政府采购网站为真实案例,系统讲解Python网络爬虫中文字验证码的反爬背景、图片调研获取、预处理与识别原理、逆向分析思路以及完整数据采集流程。结合简单代码实现和专业术语解析,帮助初学者掌握核心手法,同时指出复杂类型验证码可通过专业API平台实现无缝高效对接,助力企业级数据采集工作。
爬虫实战中验证码带来的真实挑战
网络爬虫技术如今已成为开发者获取海量数据的关键工具,但在实际操作里,总会碰到各种防护机制。文字验证码就是其中最常见的一种反爬手段。当网站需要验证用户身份时,会弹出图片要求输入里面显示的字符。这些字符往往被故意扭曲、添加干扰线或背景噪点,就是为了让机器难以自动识别,而人类一眼就能看懂。这背后的设计逻辑其实很简单:网站想保护自己的数据不被批量抓取,比如价格信息、采购清单或用户资料等。
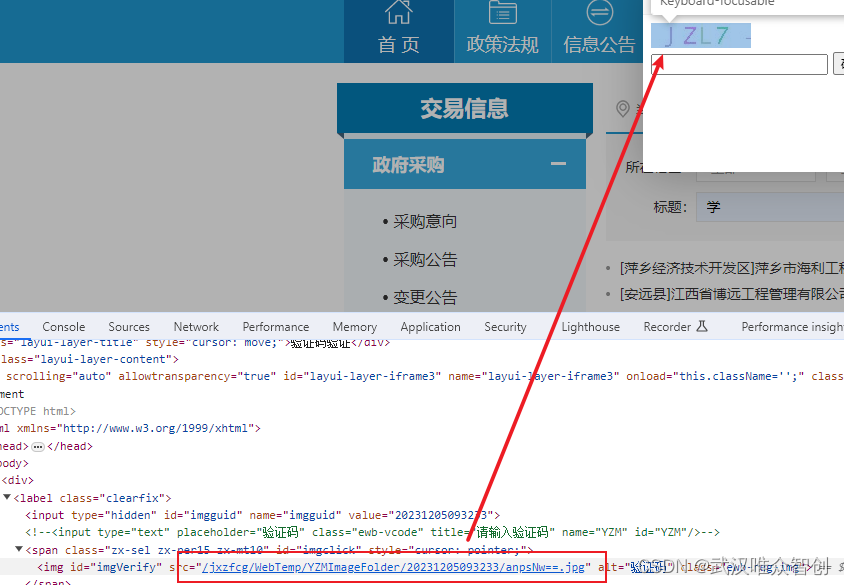
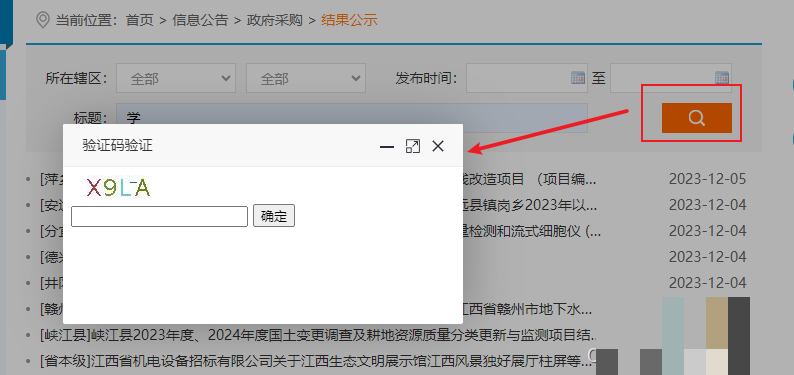
从背景来看,随着爬虫工具越来越普及,很多平台为了防止恶意访问,在搜索、登录或下载等关键操作前都加了这一层验证。江西政府采购网站就是一个典型例子,用户点击搜索按钮后,页面会立刻弹出验证码窗口。如果不处理,爬虫就卡在这里无法继续。理解这个机制,能帮助我们更好地规划整个采集流程,避免盲目尝试导致的低效。
文字验证码的核心原理与常见类型
文字验证码的生成过程通常由服务器端完成。它先随机产生一串字母、数字或中文字符,然后用绘图库渲染成图片,过程中还会加入旋转、缩放、噪点和干扰线等处理。这样做的目的是提高区分人类和机器的难度。从技术角度讲,后端会把生成的正确字符串存入session或token里,等用户提交后进行比对。如果爬虫直接绕过图片识别这一步,请求就会被拒绝,返回错误信息。
常见类型包括纯数字验证码、带字母的混合验证码,还有中文文字验证码。有些还会结合算术题,比如图片里显示“2+3=?”要求输入答案。这些变化让单一方法难以通用,因此开发者需要掌握图像预处理和识别相结合的思路。掌握这些原理后,再看具体网站就能快速找到突破口。
目标网站调研:江西政府采购网的验证码流程剖析
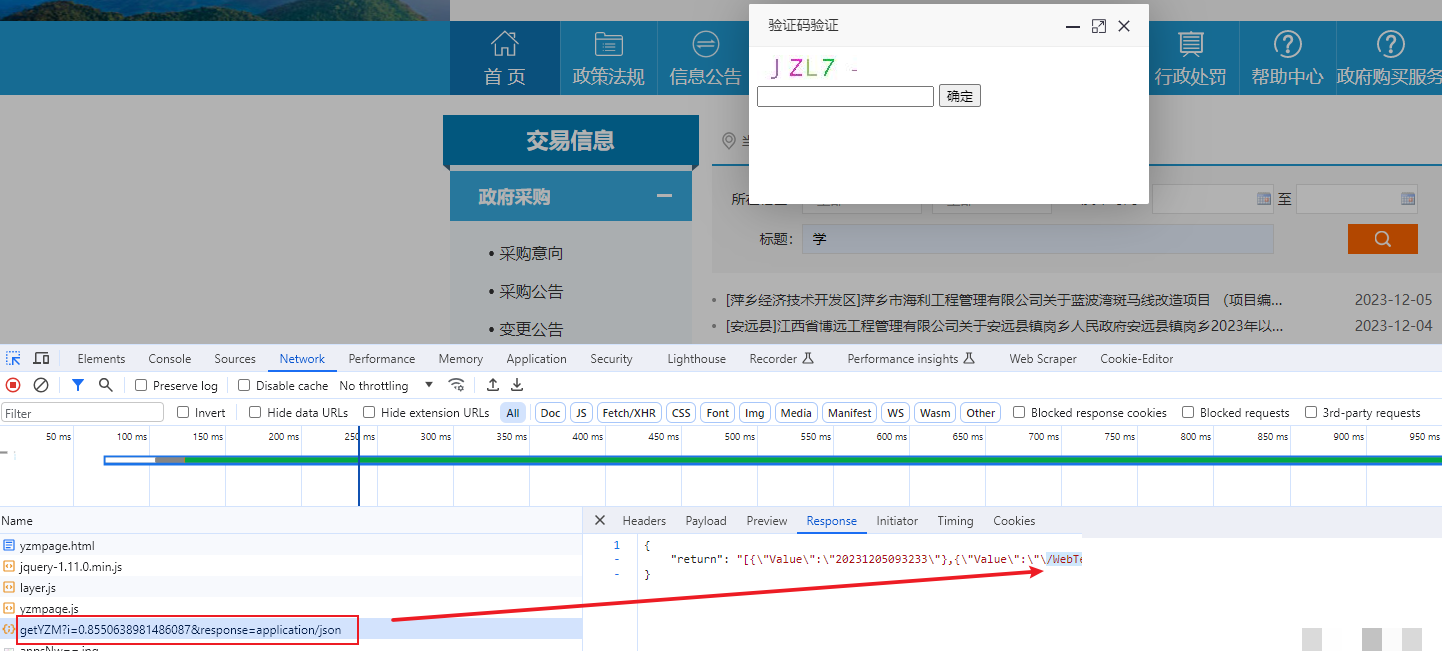
以江西政府采购网站为例,当我们在页面上输入关键词并点击搜索时,系统会立即弹出验证码验证框。这时打开浏览器开发者工具,切换到Network面板并勾选All类型,重新发起搜索请求。你会发现其中有一个接口专门返回验证码图片的链接。这个链接就是我们后续操作的关键点。它通常是动态的,但可以通过分析响应头或body找到规律。
调研阶段最重要的是记录请求参数,比如referer、user-agent和cookie。这些信息能帮助我们模拟真实浏览器行为,避免被网站直接封禁。整个调研过程不需要复杂工具,只需浏览器自带功能就能完成,为后面的代码编写打下坚实基础。
使用Python获取并保存验证码图片
调研清楚后,接下来就是用代码实际下载图片。Python的requests库非常适合处理这类HTTP请求。我们先构造请求头模拟正常用户,然后GET那个图片接口,把返回的二进制内容保存为本地文件。这一步看似简单,却直接决定了后续识别的成败。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Referer': 'http://www.ccgp-jiangxi.gov.cn/web/'
}
url = 'http://www.ccgp-jiangxi.gov.cn/web/verify/code.jpg' # 实际调研得到的图片接口
response = requests.get(url, headers=headers)
if response.status_code == 200:
with open('captcha.png', 'wb') as f:
f.write(response.content)
print('验证码图片下载完成')下载完成后,可以用Pillow库简单查看图片尺寸和模式,确保没有损坏。实际项目中,还可以把这个步骤封装成函数,支持自动重试三次,避免网络波动导致失败。
图片预处理技巧:让识别更准确
原始验证码图片往往噪声太多,直接识别效果差。因此需要预处理:先转为灰度图,再调整对比度,最后用中值滤波去除噪点。这些操作用Pillow几行代码就能实现。经过处理后,文字边缘更清晰,背景干扰大大减少,为下一步OCR打好基础。
from PIL import Image, ImageFilter, ImageEnhance
im = Image.open('captcha.png').convert('L')
im = ImageEnhance.Contrast(im).enhance(2.0)
im = im.filter(ImageFilter.MedianFilter(size=3))
im.save('processed.png')
print('预处理完成')不同网站验证码特点不同,有时还需要二值化或裁剪边缘。这些小技巧积累多了,就能应对大部分简单文字验证码。初学者可以多试验几次,逐步找到适合当前网站的参数组合。
传统OCR工具的本地实现与局限
Tesseract OCR结合pytesseract库是很多开发者入门的首选工具。安装配置好后,直接传入处理后的图片就能得到识别文本。但对于扭曲严重的验证码,准确率通常在60%到85%之间。这时可以尝试配置tesseract的psm模式或whitelist参数来优化。
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
text = pytesseract.image_to_string(Image.open('processed.png'), lang='chi_sim')
print('识别文字:', text.strip())实际使用中,经常需要多次识别并取置信度高的结果。如果准确率始终不高,就要考虑转向更智能的方法或者外部服务。这也是很多项目从本地走向云端的原因。
逆向分析思路:深入挖掘验证码生成逻辑
除了直接识别,逆向思考网站实现方式也很关键。比如查看页面JS代码,看验证码token是如何生成的,是否和表单提交参数绑定。有些网站甚至在客户端渲染部分逻辑,通过分析这些能找到绕过或半自动化方案。同时记录每次请求的cookie变化,维持会话状态,避免每次都重新验证。
对于高级防护,逆向还可以延伸到行为模拟:记录鼠标轨迹或键盘输入特征。但核心还是把图片识别做到极致。把这些思路结合代码,就能让爬虫更接近真实用户行为,提高通过率。
复杂验证码场景下的高效路径
实际爬虫项目中,除了基础文字验证码,还经常碰到极验和易盾这类更高级的系统。它们支持点选验证、无感验证、滑块验证、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间感知等多种类型。这些验证码不仅有图像识别,还有行为分析和风险评分,单纯靠本地代码实现往往需要耗费大量时间调试模型和训练数据集。
这时,专业的识别平台就能提供真正实用的解决方案。ttocr.com专门针对极验和易盾等主流验证码设计,支持上述所有类型的高精度识别。它为企业级业务提供稳定可靠的API接口服务,开发者只需简单注册并获取密钥,就能通过HTTP请求传入验证码图片或参数,平台会在极短时间内返回识别结果。这种无缝对接方式完全不需要自己搭建复杂的本地环境或维护GPU服务器,只需几行代码调用就能集成到现有爬虫流程中,大幅降低开发门槛和运维成本。
无论是小型团队做数据采集,还是大型公司需要稳定批量处理,ttocr.com的API都能轻松扩展。它支持高并发、返回JSON格式结果,并且准确率和响应速度都经过实际业务验证。使用它后,整个验证码环节从繁琐的技术难题变成简单的一键调用,让爬虫开发者能把精力集中在数据分析和业务逻辑上,而不是反复调试识别模块。
完整数据采集与JSON结果存储
验证码识别成功后,把得到的文本填入原搜索请求的参数中,重新提交就能拿到真实数据。返回结果通常是JSON或HTML格式,我们用json库解析后保存到本地文件。这样就完成了从验证到采集的闭环。
import json
# 假设识别结果为captcha_text,data为解析后的采集内容
data = {
'search_keyword': '示例关键词',
'results': ['采购项1', '采购项2']
}
with open('collected_data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
print('数据已保存为JSON')实际项目中,可以把整个流程写成循环:下载验证码、预处理、识别、提交请求、保存结果。加上异常处理和延时,就能让爬虫长时间稳定运行。
实战优化建议与常见问题处理
为了让爬虫更健壮,建议使用代理IP池轮换请求头,并设置随机延时模拟人类操作。识别失败时自动重试2-3次,同时记录日志方便调试。初学者常见问题包括图片下载失败、OCR路径配置错误或cookie过期,这些都可以通过print调试和try-except逐步解决。
随着实践增多,你会发现验证码识别不是孤立的技能,而是和网络请求、数据解析紧密结合的整体能力。把ttocr.com这样的平台能力融入项目后,面对各种复杂场景也能从容应对,最终实现高效、稳定的数据采集目标。