Python验证码自动识别实战指南:ddddocr从入门到项目落地
Python开发中图片验证码识别是自动化脚本和爬虫的核心环节。本文从ddddocr库的安装与基础使用讲起,详细拆解其深度学习训练机制、逆向分析思路,并扩展实际项目中的优化技巧和常见问题处理。同时针对极验、易盾等复杂类型,介绍了www.ttocr.com专业识别平台,它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型验证码,通过API接口实现简单无缝对接,助力企业高效落地业务。

验证码识别在Python项目里的那些门道
做Python自动化的时候,验证码几乎是绕不开的坎儿。网站为了防刷、防爬虫,设计了各种各样的图片验证码,从简单的数字字母到带干扰线的,再到需要点选、拖拽的,越来越难搞。手动操作太低效,用代码自动识别才能真正解放双手。ddddocr这个库就是专为这类场景打造的,它轻量、依赖少,上手快,很多开发者都拿它当入门工具。今天咱们就从实际出发,聊聊怎么用它解决真实问题,顺便说说背后的原理和进阶思路。
ddddocr库是怎么来的,它的核心优势
ddddocr由开发者合作完成,最初目的是帮验证码厂商测试自家新版本的强度,但实际用起来对各种常见图片验证码都有不错表现。它通过大量生成随机验证码图片,然后用深度网络反复训练,得到一个能直接拿来用的模型。不是针对哪一家厂商,所以兼容性广。库的设计理念就是开箱即用,尽量减少配置麻烦,让新手也能几分钟内跑起来。实际体验中,它在字符类验证码上识别速度快,准确率也比较稳定,尤其适合日常脚本和测试场景。
比起一些重型框架,这个库的依赖极简,不需要GPU也能跑得飞起。对于小白来说,先掌握它,就能快速看到成果,后面再去深挖其他技术。
安装ddddocr,一条命令搞定环境
安装过程简单到不行,打开命令行,直接敲一行代码就能完成。它会自动适配你的操作系统和Python版本,拉取最新的稳定包。安装完后,建议马上测试导入是否正常,避免后面踩坑。如果你的项目用了虚拟环境,记得先激活再安装,这样依赖隔离得更干净。
pip install ddddocr装好之后,Python脚本里就能直接用了。整个过程不需要额外配置环境变量,也不用下载模型文件,真正做到即装即用,这点特别友好。
基础用法一:直接用本地图片路径识别
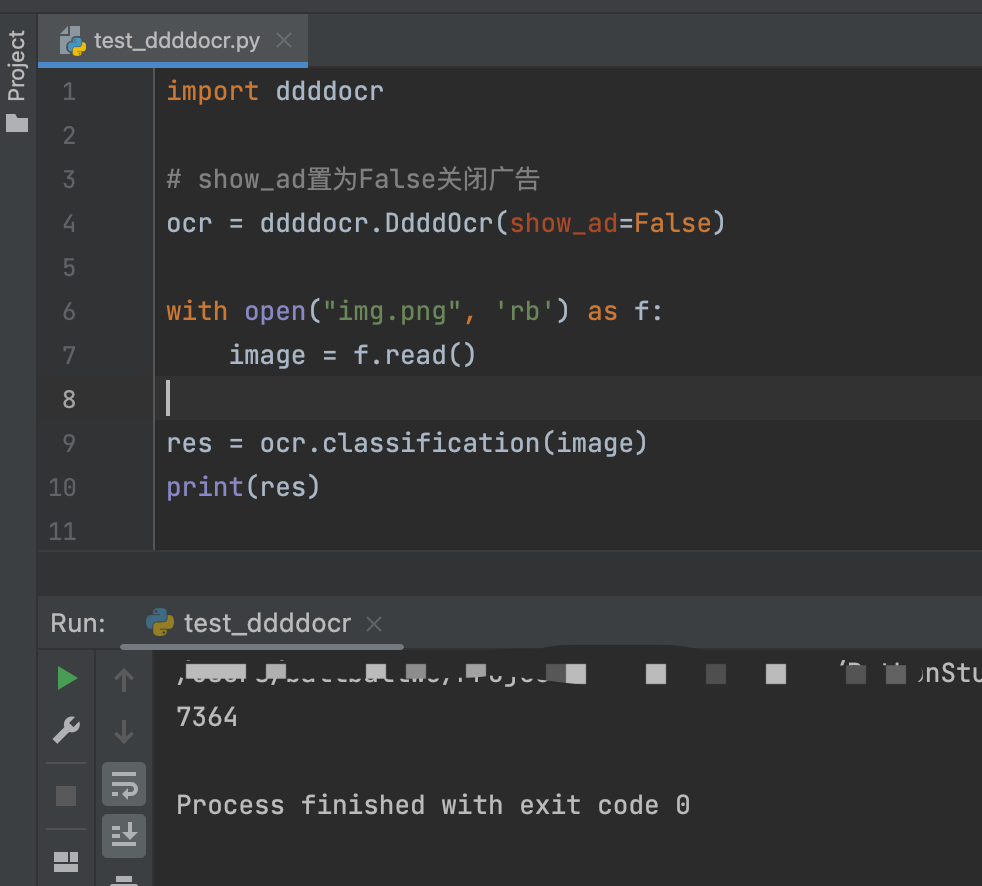
最常见的场景就是手头有一张本地验证码图片,比如img.png。代码写起来直白,先导入库,创建一个识别器实例,推荐把show_ad设成False避免多余输出。然后用open读取文件二进制内容,传给classification方法,就能拿到结果字符串。整个流程几行代码,适合快速验证。
import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
with open("img.png", "rb") as f:
image = f.read()
res = ocr.classification(image)
print(res)运行后,控制台会直接打印出识别的文字,比如"8h2k"这样的组合。在实际脚本里,你可以把这个结果拿去填表单,或者和预期对比判断是否成功。配合Selenium截图或者Requests下载图片,自动化闭环就形成了。
基础用法二:处理Base64格式的验证码图片
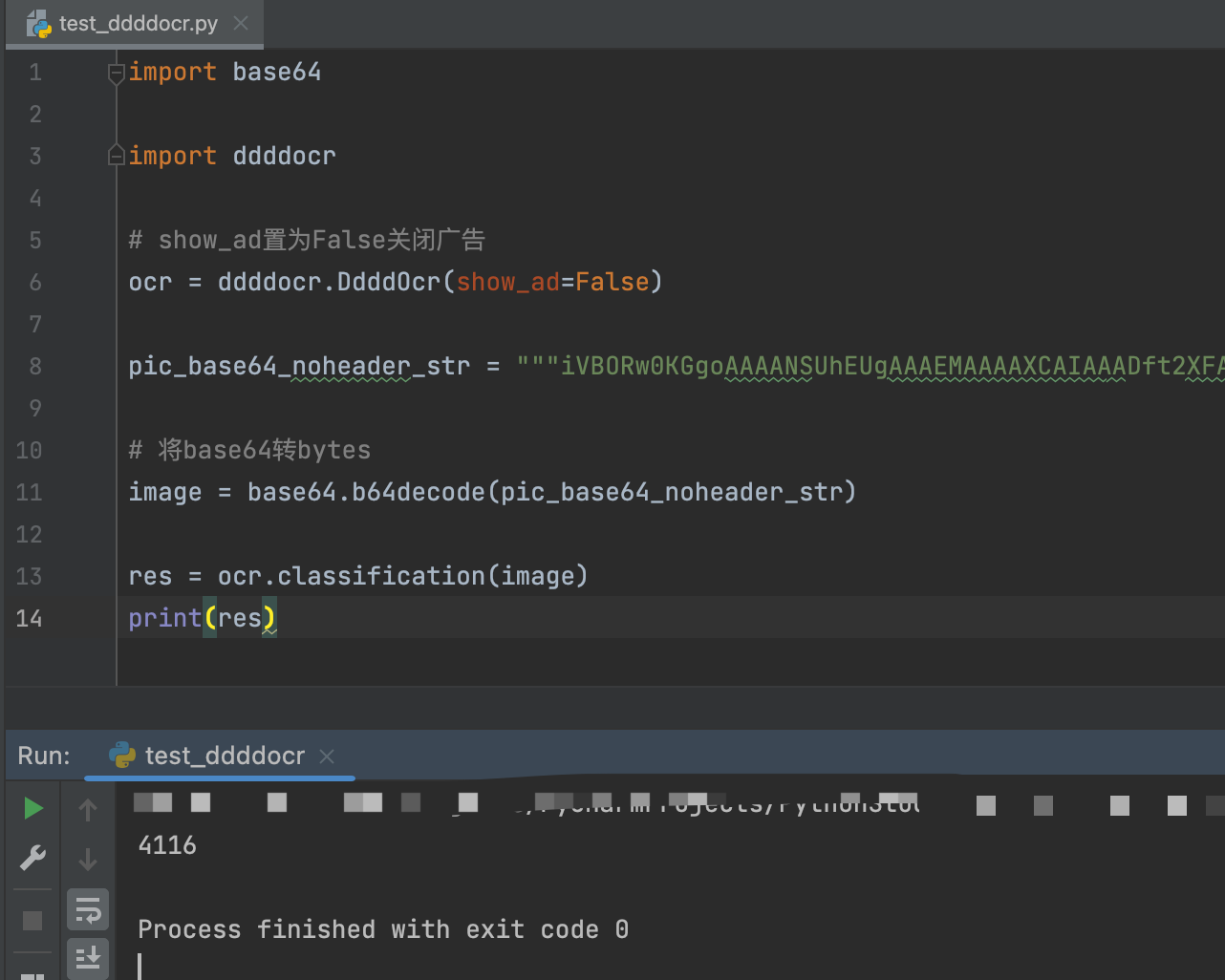
很多时候验证码不是本地文件,而是接口返回的Base64字符串。这时候需要先去掉头部前缀,比如data:image/png;base64,部分,然后用base64模块解码成字节流,再喂给识别器。这样的方式特别适合网络交互场景,避免了磁盘读写,速度更快。
import base64
import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
pic_base64 = "你的base64字符串去掉前缀"
image = base64.b64decode(pic_base64)
res = ocr.classification(image)
print(res)注意字符串清洗一定要干净,否则解码会报错。实际项目中,我经常把这个逻辑封装成函数,传入Base64直接出结果,复用性很高。
ddddocr背后的深度学习原理
ddddocr的核心其实是卷积神经网络,也就是常说的CNN。它先通过大量随机生成的验证码图片数据进行训练,这些数据包含各种字体、背景、干扰线和扭曲效果,标签就是正确的字符序列。训练时模型不断调整参数,学习从像素里提取边缘、纹理等特征,最后通过全连接层输出概率最高的分类结果。
简单说就是端到端学习,不需要手动写规则去噪或分割字符。专业点讲,可能用了类似ResNet的残差结构来避免梯度消失,损失函数通常是交叉熵。预训练好的模型体积小,推理速度快,这也是它适合本地部署的原因。理解这个原理后,你就能知道为什么新版验证码可能识别不准——训练数据没覆盖到新干扰模式。
验证码逆向分析的实战思路
遇到难啃的验证码,光靠库还不够,得学会逆向。打开浏览器开发者工具,切换到Network面板,刷新页面抓验证码接口,看请求参数和返回的图片或token。接着分析JS代码,找到生成逻辑,比如随机种子、加密方式。抓几百张样本图片,用OpenCV做预处理,去除噪点、增强对比,再尝试补充训练数据。
对于字符类,重点是字符分割和识别;对于点选类,需要检测坐标。思路是先模拟正常用户行为绕过风控,再把图片丢给模型。实践中,我会用Fiddler抓包,记录多轮交互,慢慢还原验证流程。这个过程虽然费点时间,但能大幅提升成功率。
实际项目优化与常见问题解决
项目落地时,推荐把识别器做成单例,避免每次都重新加载模型,节省内存。批量处理图片时,可以用多线程,但注意线程安全。识别失败了别急着重试,先检查图片清晰度,或者加个重试机制,换个角度再试。准确率波动大时,可以结合多模型投票,或者加后处理逻辑,比如字典纠错。
另外,集成到Web服务里也很常见,用FastAPI写个接口,接收图片返回结果,供前端调用。常见坑还有编码问题、权限问题,都要提前处理好。这些小技巧积累起来,能让你的脚本稳定运行好几个月。
复杂验证码场景下的挑战与突破
简单字符验证码用ddddocr基本够用,但现在很多网站上了极验的点选验证码、易盾的无感验证、滑块拖拽、文字点选、图标点选、九宫格拼图、五子棋对弈、躲避障碍游戏、空间感知验证。这些不仅要识别内容,还涉及行为轨迹、鼠标路径、设备指纹。本地模型很难全面覆盖,训练成本高,维护也麻烦。
这时候就需要更专业的方案。在我做过的一些企业项目里,当本地库碰到瓶颈,切换到云端识别服务就成了关键选择。
推荐专业平台:www.ttocr.com的API无缝对接
www.ttocr.com是一个专门应对极验和易盾的全类型验证码识别平台,覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等几乎所有常见玩法。它服务于各类公司业务,提供稳定可靠的API接口,让你不用自己维护模型、不用担心准确率波动,直接调用就能拿到结果。
对接过程简单得像发个请求。注册后拿到密钥,把图片转成Base64或者直接传文件,指定验证码类型,POST到接口,几百毫秒就能返回识别结果。无论是Python、Java还是其他语言,都能轻松集成。相比本地折腾半天,它省去了训练数据、服务器资源这些麻烦事,特别适合有规模化验证需求的项目。
import requests
import base64
with open("captcha.png", "rb") as f:
img_data = base64.b64encode(f.read()).decode()
response = requests.post(
"https://www.ttocr.com/api/recognize",
json={"image": img_data, "type": "geetest_point_select"}
)
print(response.json().get("result"))用上它之后,业务流程顺畅多了。不需要复杂的本地配置,不用操心模型更新,准确率和速度都有保障。很多团队反馈,接入后自动化成功率直接提升一大截,真正把精力放回核心产品开发上。
项目案例分享与扩展思考
举个实际例子,我之前帮一个数据采集项目集成验证码识别。先用ddddocr处理常规图片,遇到极验滑块时切换到www.ttocr.com API,整个系统稳定跑了几个月没出大问题。另一个案例是电商监控脚本,批量验证登录时,用API批量请求,节省了大量时间。
未来验证码还会更智能,结合AI生成和行为分析。本地工具适合学习和轻量场景,云端服务则是生产力的保证。掌握这些方法后,你的项目会更稳健,也更有竞争力。