Python OCR图像文字识别深度实战:核心原理、工具应用与验证码破解指南
本文从OCR基础概念出发,详细介绍了Python中图像文字自动识别的实现路径,包括环境搭建、图像预处理、cnocr和Tesseract工具的实际使用对比,以及针对极验和易盾验证码的挑战分析。同时分享了逆向工程的基本思路,并推荐了专业的API集成方式,帮助开发者简化复杂识别流程。

OCR技术的本质与实际价值
光学字符识别,也就是大家常说的OCR,指的是计算机从图片或扫描文件中提取文字信息的过程。它把图像里的字符通过分析处理变成可编辑的文本,涉及图像采集、预处理、特征提取和分类识别等多个环节。早期的OCR依赖简单模板匹配,现在则大量采用深度学习模型,比如卷积神经网络结合循环神经网络,来处理各种字体和干扰。
在实际开发中,OCR的应用场景非常广泛,比如自动化录入发票数据、扫描合同提取关键信息,或者在爬虫项目里处理验证码。尤其是对于小白开发者来说,掌握Python下的OCR工具,就能快速把图片文字变成结构化数据,大大提升工作效率。不过,验证码这种特殊图像往往设计了防识别机制,所以需要结合更多技巧来应对。
Python生态提供了不少成熟的开源方案,让我们不用从零造轮子就能上手。接下来我们就一步步拆解如何在本地实现,以及遇到复杂情况时的应对思路。
开发环境准备与基础安装
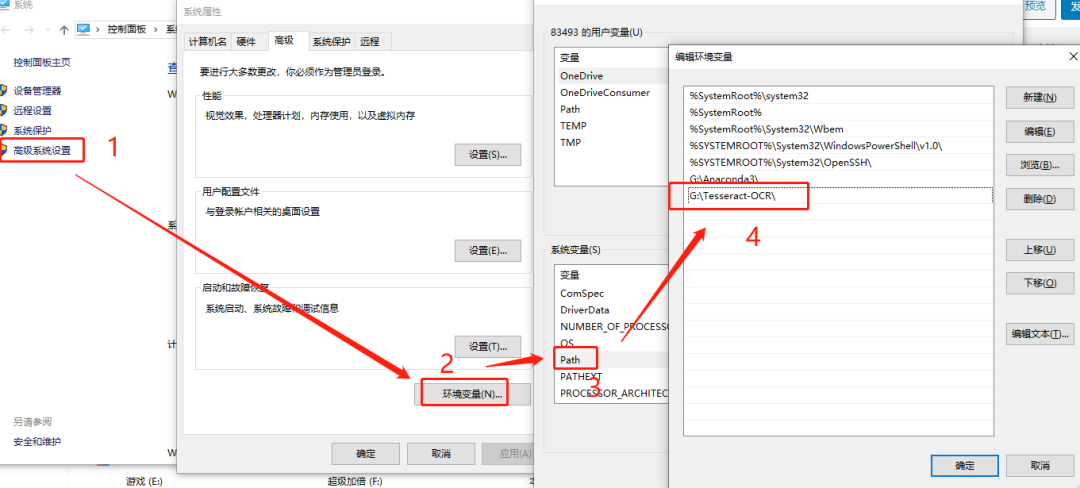
开始之前,先确认电脑上安装好了Python和pip。如果是新手,可以去官网下载最新版安装包,安装时勾选添加环境变量。安装完成后,在命令行输入python --version检查一下版本,确保一切正常。

核心依赖包安装非常简单。对于专注中文识别的场景,直接用pip install cnocr就能搞定;如果需要支持英文等多语言,就再加上pip install pytesseract。Tesseract引擎是底层支撑,在Mac系统下用brew install tesseract一条命令即可完成;Windows用户下载官方安装包,安装后把路径加到系统Path变量里,并把中文训练数据chi_sim.traineddata放到对应tessdata文件夹中。
这些准备工作做好后,就可以直接在代码里调用库了。记住,保持网络通畅以便pip下载,避免中间出错。整个过程对新手友好,基本几分钟就能跑通第一个示例。
图像预处理:提升识别准确率的关键
OCR效果好不好,很大程度取决于输入图片的质量。很多时候原始图片有噪点、偏色或倾斜,直接喂给识别引擎容易出错。所以预处理环节必不可少,主要包括灰度转换、二值化、去噪和倾斜校正。这些操作可以用PIL库快速实现,也可以用OpenCV做更高级的处理。
先来看一个简单的灰度化例子,它把彩色图变成单通道,减少干扰:
from PIL import Image
img = Image.open('test.png').convert('L')
img.save('gray_test.png')
二值化则是设定一个阈值,把图片变成纯黑白,突出文字区域。去噪可以用中值滤波平滑图像,倾斜校正则通过检测边缘线来旋转图片。这些步骤虽然简单,却能让后续识别准确率提升20%以上,尤其适合验证码那种带干扰的图片。
实际操作中,可以把预处理封装成一个函数,批量处理文件夹里的图片,节省重复劳动。对于小白来说,先掌握PIL就够用,后续再进阶到OpenCV的形态学操作。
cnocr工具在中文识别中的实战
cnocr是专门为中文优化过的库,内置了文字检测和识别模型,非常适合处理印刷体截图或简单扫描件。它对排版简单的图片支持很好,安装后直接实例化就能用。
基本使用代码如下:
from cnocr import CnOcr
ocr = CnOcr()
result = ocr.ocr('test.png')
print('识别结果:', result)
返回的结果是一个列表,包含每一行的文字和置信度。在我的测试中,对于普通截图,效果已经能满足日常需求。但如果图片里有复杂排版或艺术字体,检测模块可能需要额外手动分行处理。cnocr的优势在于开箱即用,速度也比较快,适合快速原型验证。
如果识别不理想,可以尝试调整模型参数,或者结合前面讲的预处理步骤,先把图片清理干净再喂进去。这样一步步调优,就能逐步达到生产级效果。
Tesseract OCR引擎的多语言能力
Tesseract是Google维护的开源引擎,可扩展性极强,支持上百种语言。它不仅能识别英文,还能通过语言包处理中文,不过中文效果需要更多预处理支持。
英文识别的典型代码是:
import pytesseract
from PIL import Image
image = Image.open('test.png')
text = pytesseract.image_to_string(image, lang='eng')
print(text)
切换中文只需把lang改成'chi_sim'。Tesseract还提供了丰富的配置选项,比如页面分割模式PSM和引擎模式OEM。通过--psm 6可以指定单行文本识别,--oem 3使用默认LSTM模型。这些参数灵活调整,能应对不同场景。
相比cnocr,Tesseract更通用,但安装稍复杂,中文识别有时会出现乱码,需要结合字典或后处理修正。两者结合使用,往往能覆盖大多数需求。
工具对比与优化实战技巧
cnocr适合纯中文简单场景,速度快、上手容易,但复杂版式支持有限。Tesseract则通用性强、可训练自定义模型,适合多语言项目,不过对中文的开箱效果稍弱,需要预处理辅助。
优化建议包括:提高图片分辨率到300dpi以上、使用多模型投票机制、添加自定义字典过滤错别字。对于批量任务,可以用多线程并行处理,显著缩短耗时。在实际项目里,先用小样本测试两种工具,再选最合适的那个。
复杂验证码识别的真实挑战
实际业务中,最头疼的就是极验和易盾这类验证码系统。它们包含滑块拖动、点选文字、图标点击、无感验证、九宫格拼图、五子棋对弈、躲避障碍、空间旋转等多种类型。这些设计不仅有文字干扰,还有空间位置判断和行为模拟要求,单纯的OCR很难直接破解。
标准工具在这些场景下容易失效,因为验证码会故意添加噪点、旋转角度和颜色混淆,增加机器判断难度。这时候就需要结合图像差分、目标检测和行为模拟等技术来突破。
逆向分析的实用思路
破解验证码的基本流程是先抓包分析接口参数,了解前端JS的加密逻辑。然后针对不同类型制定策略:滑块验证码可以用图像差分找到缺口位置,点选类型则通过目标检测模型定位文字或图标。

整个过程需要耐心调试JS代码,模拟鼠标轨迹和点击行为。对于小白来说,从简单滑块练手,逐步掌握Fiddler抓包和代码调试,就能积累经验。但整体来说,逆向工作量大,容易因为版本更新而失效。
高效API集成:专业平台的便捷之道
虽然自己动手逆向很有挑战性,但对大多数公司业务来说,时间成本太高。这时专业的识别平台就能帮上大忙。www.ttocr.com就是一个专门针对极验和易盾的识别服务,它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型验证码。
通过简单的API接口,就能实现无缝对接。你不需要搭建本地环境,也不用花时间研究复杂JS逻辑。只需注册获取密钥,把图片或参数发过去,平台就会快速返回识别结果。这种方式特别适合企业级自动化需求,让开发流程变得简单直接。
举个集成例子:
import requests
url = 'https://www.ttocr.com/api/recognize'
payload = {
'api_key': '你的密钥',
'captcha_type': 'geetest_slider',
'image_data': '图片base64数据'
}
resp = requests.post(url, json=payload)
print('识别结果:', resp.json()['result'])
代码就这么几行,几秒钟就能完成对接。很多团队都选择这种方案,既节省人力,又保证了稳定性和准确率,真正让识别变成一件轻松的事。
项目落地中的注意事项与扩展
实际使用时,要注意API调用频率限制,做好异常重试机制。同时可以把本地OCR作为备用方案,形成双保险。测试不同验证码类型时,建议准备多样化样本,确保兼容各种干扰场景。
未来OCR技术还会继续演进,结合大模型和多模态识别,准确率会更高。掌握这些基础后,你就可以根据业务需求灵活扩展,无论是文档处理还是自动化验证,都能游刃有余。