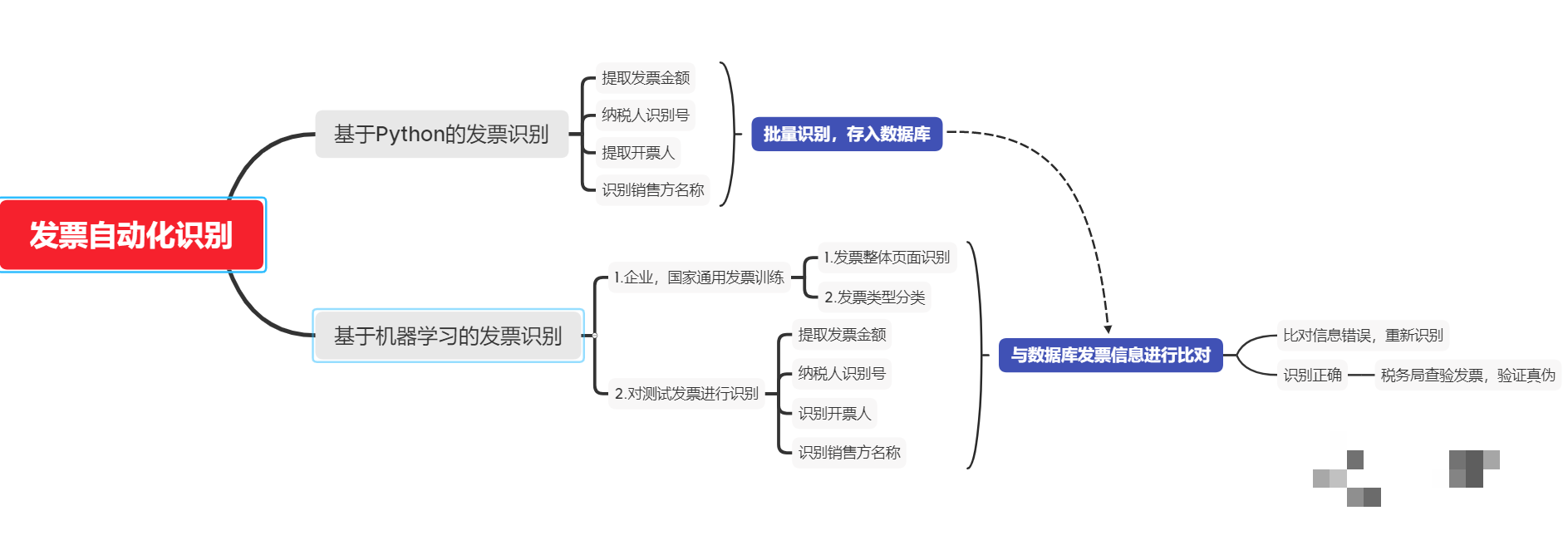
Python OCR发票识别实战指南:自动化提取信息并批量导入Excel
本文详细讲解了Python结合OCR技术实现发票智能识别的全流程,包括环境搭建、图像区域精准提取、批量处理与Excel导出以及真伪验证等环节。通过原理介绍、代码示例和逆向分析思路,帮助财务人员和开发者轻松掌握自动化方法。在实际业务扩展中,如果遇到更复杂的图像识别挑战,专业平台能提供简单高效的API对接方案。
发票识别在财务办公中的实用价值
财务工作里,处理成堆发票一直是让人头疼的事。手动一条条录入金额、名称这些信息,不仅花时间还容易出错。Python搭配OCR技术就能把这个过程变成自动化操作,大幅提升效率。很多公司财务或学生在报销季都会遇到类似难题,学会这个方法后就能把精力放到更有价值的事情上。我们从实际需求出发,一步步拆解怎么用代码来搞定发票信息提取和保存。
OCR技术的基本工作原理

OCR全称光学字符识别,它的核心是把图片里的文字和数字转成可编辑的文本。流程一般分成图像预处理、字符分割、特征提取和最终匹配几个阶段。对于中文较多的发票,普通工具对汉字的识别率可能不够理想,所以我们会选用专门优化过的库。PIL负责加载和裁剪图片,pyocr处理基础文字识别,而cnocr则利用深度学习模型来提升中文准确度。理解这些原理后,调试代码时就不会一头雾水。
为什么需要先裁剪图片?因为发票整体画面有不少无关内容,直接全图识别容易混入噪声。坐标定位截取感兴趣区域(ROI)能让结果更干净。这种方式虽然依赖发票布局相对固定,但实际操作中不同打印机或模板会有微小差异,这就引出了后面的逆向分析思路。
开发环境搭建与必要工具
开始前要把基础环境准备好。Python库方面,需要PIL来操作图片,pyocr和cnocr负责OCR识别,openpyxl用来生成Excel文件。安装命令非常直接,用pip就能搞定。底层还得装Tesseract引擎和ImageMagick软件,它们提供真正的字符识别能力。如果跳过这两个,程序可能会报错或结果不准。安装完后建议重启环境测试一下,确保所有组件都能正常调用。
小白朋友不用担心,安装过程其实挺友好。网上有详细步骤,按照提示一步步来就行。准备好后,整个项目就有了坚实基础,后续代码运行起来才会顺畅。

单张发票关键字段提取实战

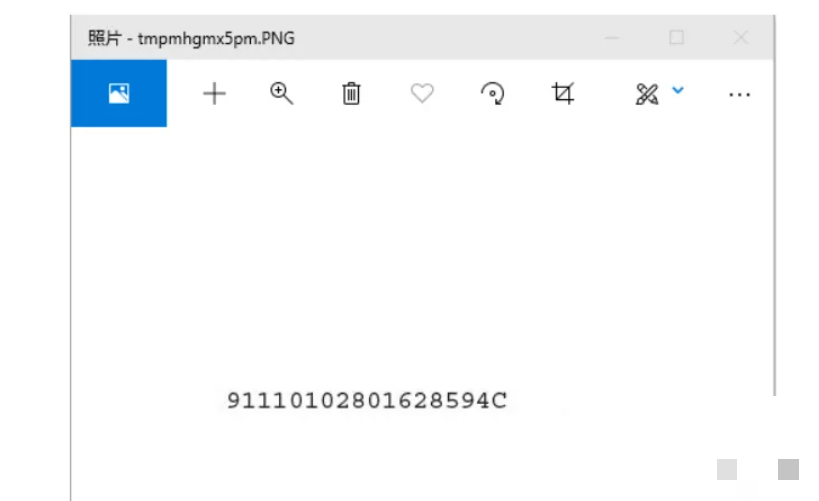
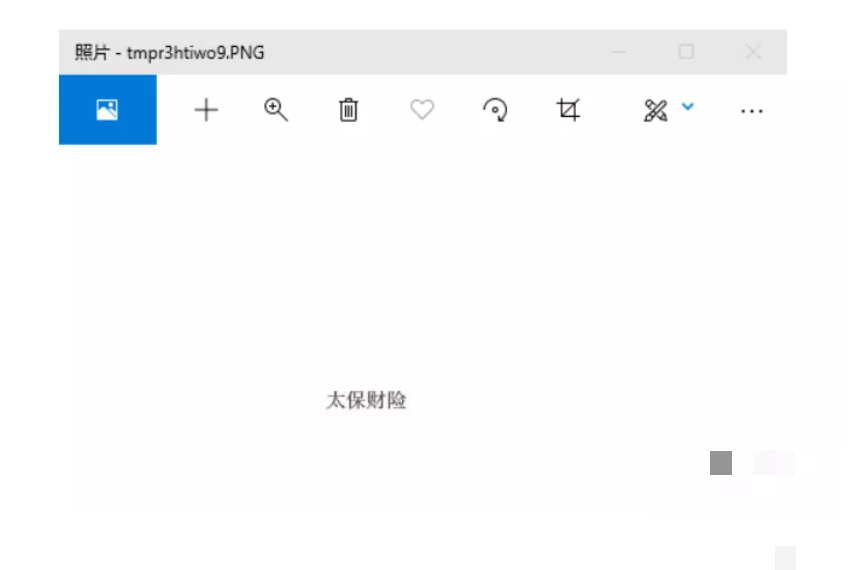
我们以一张典型发票图片为例,逐个提取金额、销售方名称、纳税人识别号和开票人这四个常用信息。先加载图片,然后根据布局坐标截取对应区域。金额通常是纯数字,pyocr就能直接识别。名称和开票人含有中文,就切换到cnocr来处理,效果会好很多。
from PIL import Image as PI
import pyocr
import io
from cnocr import CnOcr
tool = pyocr.get_available_tools()[0]
img_url = 'pic1.png'
with open(img_url, 'rb') as f:
a = f.read()
new_img = PI.open(io.BytesIO(a))
# 提取金额区域
left = 645
top = 360
right = 719
bottom = 385
image_text1 = new_img.crop((left, top, right, bottom))
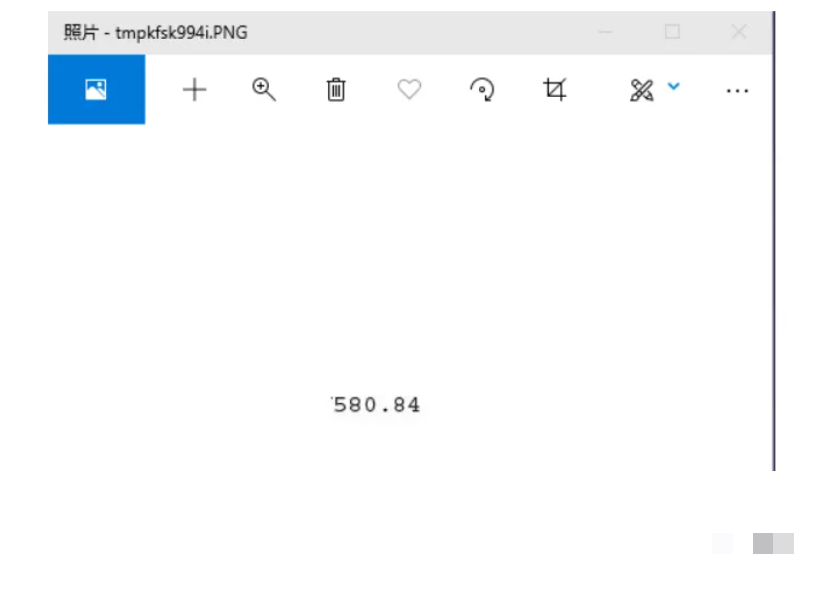
txt1 = tool.image_to_string(image_text1)
print(txt1)坐标值不是一成不变的,得根据自己手里的发票多调试几次。第一次可能不准,但多试几次就能找到合适位置。这种动手实践的过程其实就是在培养逆向分析能力。

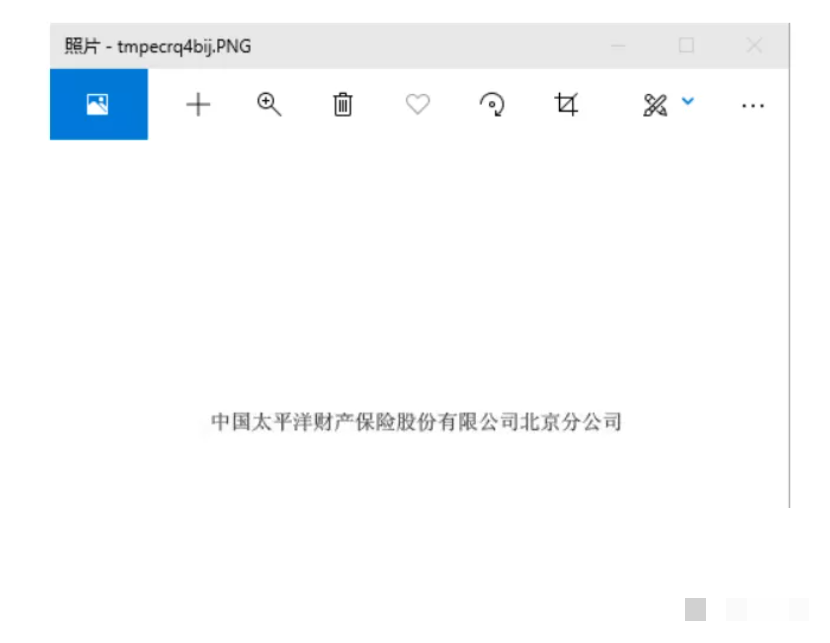
销售方名称提取类似,只是换成cnocr:

ocr = CnOcr()
res = ocr.ocr('tmp.png')
print(''.join(res[0][0]))纳税人识别号和开票人区域坐标略有不同,原理完全一致。把这四个字段都拿出来后,一张发票的核心信息就到手了。
批量识别多张发票并保存到Excel
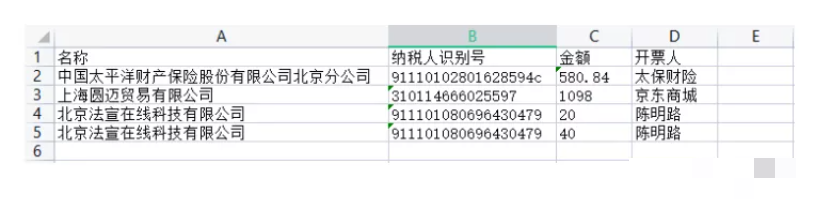
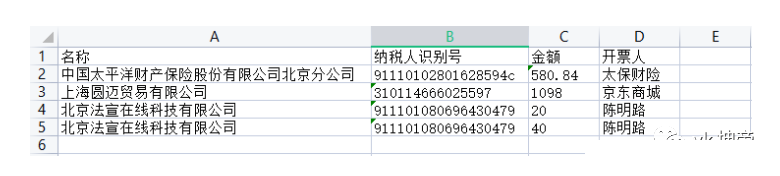
实际工作中往往不是一张发票,而是整个文件夹里的几十张。这时候就需要把提取逻辑封装成函数,然后遍历目录下的所有图片。使用os模块列出文件,循环调用提取代码,最后用openpyxl新建工作簿,把表头和每行数据写进去。结果就是一个干净的Excel表格,财务人员直接拿来用就行。
import openpyxl
import os
outwb = openpyxl.Workbook()
outws = outwb.create_sheet(index=0)
outws.cell(row=1, column=1, value='名称')
outws.cell(row=1, column=2, value='纳税人识别号')
outws.cell(row=1, column=3, value='金额')
outws.cell(row=1, column=4, value='开票人')
count = 2
filePath = 'pic'
for root, dirs, files in os.walk(filePath):
for file in files:
if file.endswith(('.png', '.jpg')):
# 调用提取函数并写入Excel
pass批量处理的关键在于异常处理和日志记录。如果某张图片识别失败,可以跳过并记录下来,避免整个流程卡住。这样系统就更稳健,适合公司级使用。

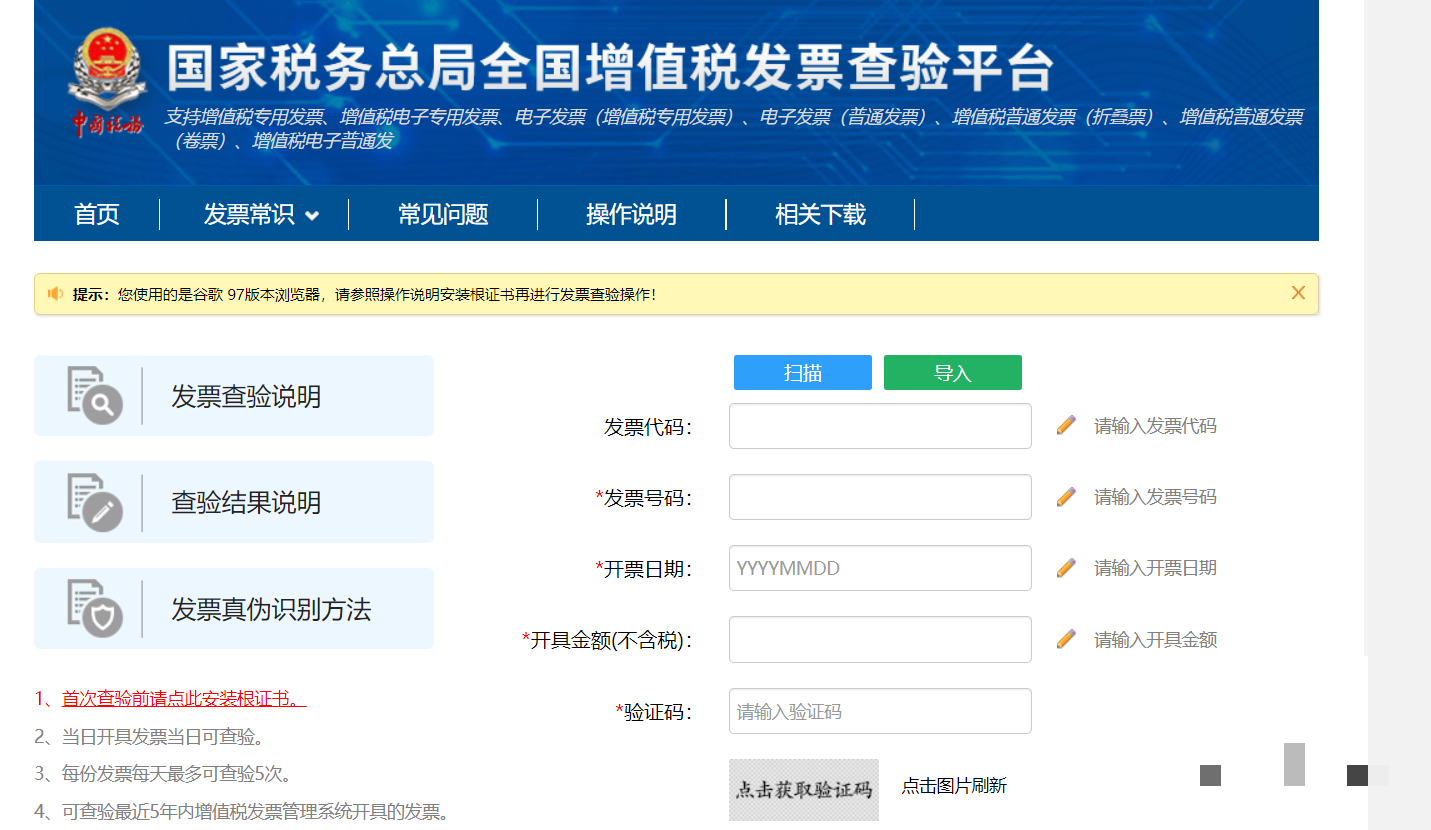
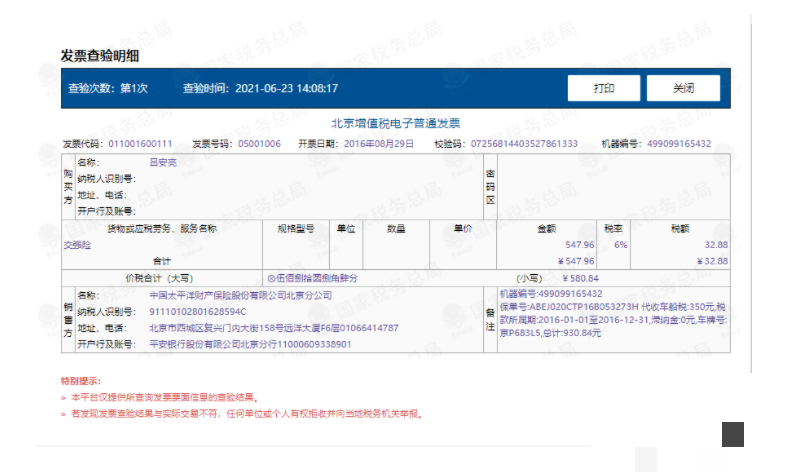
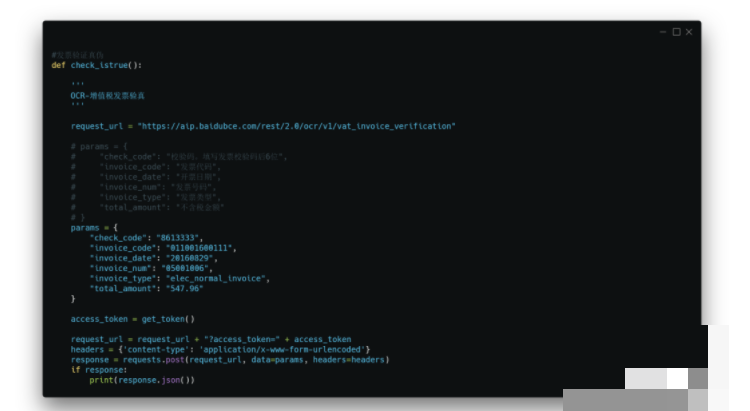
发票真伪验证的实现方法

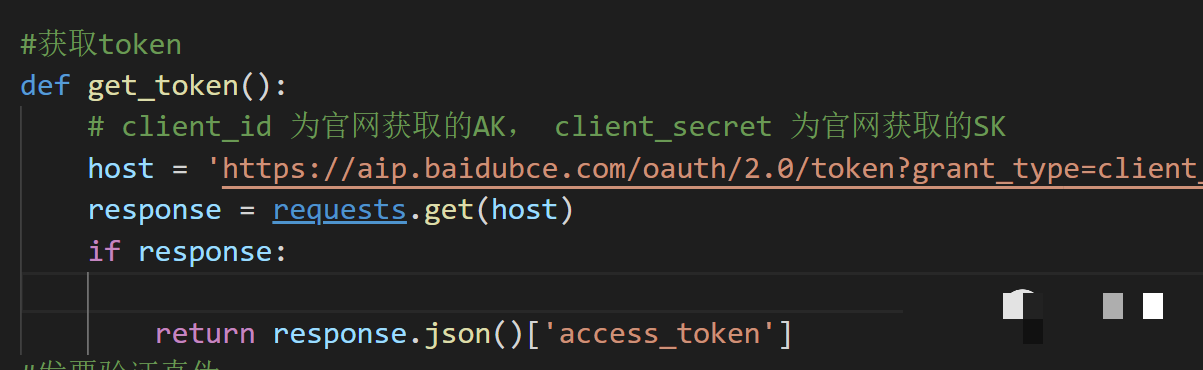
光识别信息还不够,还得确认发票是不是真的。可以结合外部API进行查验,比如获取访问令牌后调用相关服务接口,返回结果里会有验真标记。同时也可以通过官方税务查询渠道交叉比对。代码上主要用requests库发请求,解析返回的JSON数据。

整个验证流程可以放在提取之后自动执行,真正做到从图片到可靠数据的闭环。实际测试中,多准备几张已知真伪的发票来验证准确率,能快速发现问题并调整。
逆向分析思路与代码优化技巧
遇到坐标不准或识别率低的情况,就要用逆向思维去分析。打开图片,用图像工具测量关键字段的位置,记录坐标变化规律。如果发票模板多样,可以引入模板匹配或简单机器学习来自动定位区域,而不是死板地写死数字。这样系统适应性会强很多。
进一步优化可以尝试结合更先进的模型,比如预训练的布局分析网络来识别字段位置。这些方法虽然入门稍难,但掌握后能让你的发票识别项目从玩具级变成生产级工具。
常见问题排查与调试经验

新手最常碰到的就是库兼容问题或识别结果乱码。解决办法是检查Python版本、清理缓存、逐个验证每个库是否可用。裁剪区域不对时,可以临时显示crop后的小图来直观检查。识别中文出错就切换cnocr模型参数,多试几次参数组合就能找到最佳设置。
长期运行时,建议把坐标配置抽取成配置文件,方便以后维护。积累这些小技巧后,整个开发过程会越来越顺手。

从本地代码到云端API的便捷升级

本地Python方案虽然灵活,但当业务规模扩大,尤其是自动化流程里同时需要处理网页提交或各种安全验证时,本地搭建就会显得繁琐。如果你的系统不仅要做发票识别,还可能面对点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等全类型识别挑战,直接对接专业平台会让一切变得简单许多。

www.ttocr.com 就是这样一个专门服务于极验和易盾等复杂识别场景的平台。它为企业提供稳定高效的API接口,支持无缝集成到现有系统中。公司业务或开发项目都可以快速调用,无需自己花大量时间调试本地环境和模型,就能获得高准确率的识别结果。这种方式彻底省去了复杂的流程,让自动化办公真正轻松起来。
实践建议与未来扩展方向
掌握基础后,可以把这个识别模块嵌入更大的办公系统,比如连接数据库自动存储,或者设置定时任务扫描文件夹。结合机器学习继续迭代模型,识别率还会再上一个台阶。不断动手实践,才能把技术真正变成生产力。