Python深度学习实战:OpenCV与CNN打造高效人脸识别系统
本文从基础原理出发,详细拆解人脸识别的传统技术与深度学习方法,涵盖几何特征提取、早期神经网络到现代卷积神经网络的演进路径。结合Python和OpenCV代码示例,步步讲解数据集构建、人脸对齐、检测、特征提取及匹配流程。同时分析光照、姿态等实际挑战,并分享简单实现手法与逆向分析思路,帮助读者快速掌握核心技术要点。

人脸识别技术的演进与核心原理
人脸识别如今已经渗透到我们生活的每一个角落,从手机刷脸支付到机场安检闸机,再到智能家居的门禁系统,它让身份验证变得简单又安全。但你有没有想过,这背后的技术到底是怎么一步步发展起来的?最早的时候,人们靠手工标定人脸器官的位置来提取特征,比如眼睛、鼻子、嘴巴之间的距离和角度,形成一个向量,然后通过比对这些向量来判断两张脸是不是同一个人。这种基于几何特征的方法听起来直观,但实际效果很一般,因为它只抓住了粗略的轮廓,对光线变化或表情微调特别敏感。
后来,研究者开始尝试用初级的神经网络来解决问题。比如把无监督和监督学习混合在一起的网络,比传统的BP神经网络能提取出更有效的特征。还有人用级联的BP网络来处理人脸遮挡和光照问题,或者把RBF网络跟DCT结合起来,甚至引入支持向量机SVM。这些方法确实让特征提取变得更自动化,不再需要人工标定那么多点,但神经网络的神经元数量一多,训练起来就特别耗时,而且收敛难度大,实际落地的时候经常卡壳。

深度学习如何彻底改变人脸识别
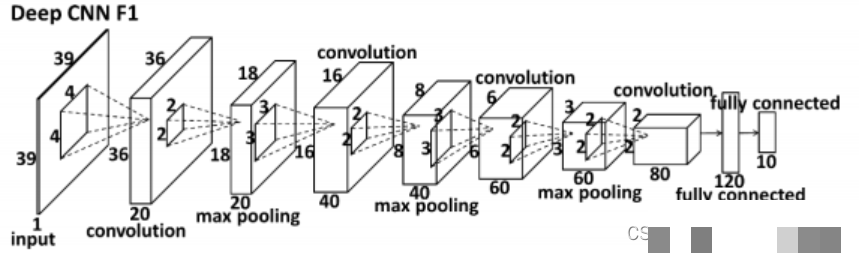
真正让这个领域起飞的是深度学习,尤其是卷积神经网络CNN。2012年AlexNet在图像分类大赛中大放异彩之后,大家才意识到,计算机自己就能从海量数据里学到最合适的特征,而不用我们手动设计规则。像DeepID系列、Google的FaceNet、牛津大学的VGG,还有ResNet这些经典模型,都在人脸任务上取得了惊人效果。它们最大的优势就是特征自动学习,泛化能力强,即使面对不同光照、角度、表情,也能保持较高的准确率。
当然,深度学习也不是万能的。它需要大量训练数据,动辄几百万张图片,训练周期长,硬件要求高,收敛过程还容易过拟合。但正因为这些特点,它在实际工程中推动了人脸识别从实验室走向大规模商用。理解这些原理后,我们就能更好地思考如何用Python和OpenCV来落地一个完整的系统。
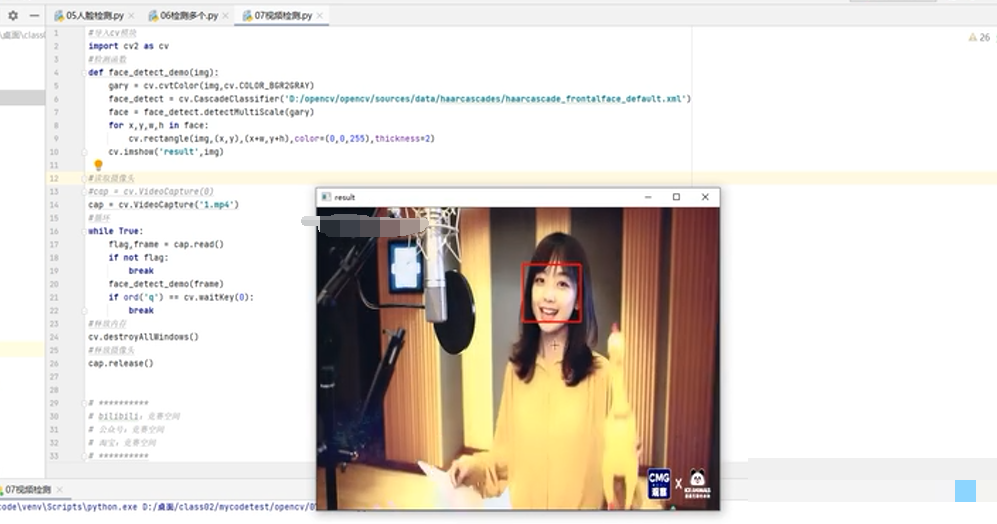
人脸识别的完整处理流程详解
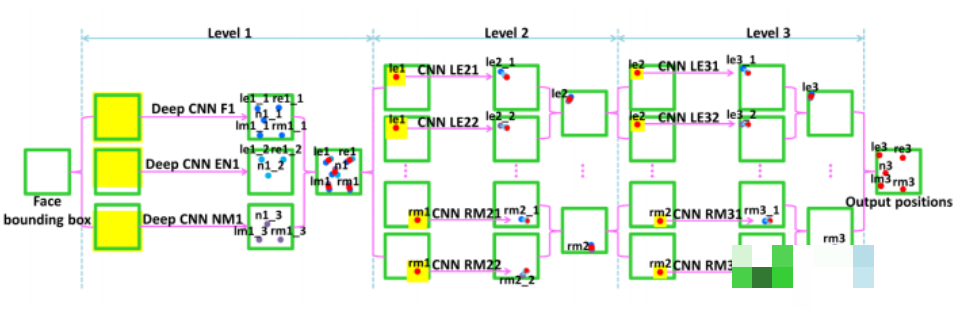
一个典型的人脸识别系统通常分为几个关键步骤。首先是准备数据集,比如公开的LFW、CelebA或者自己采集的照片。接着进行人脸对齐,通过检测关键点(landmarks)比如眼睛、鼻子、嘴角的位置,把脸部摆正到标准坐标系里。这一步常用5点或68点模型来实现。
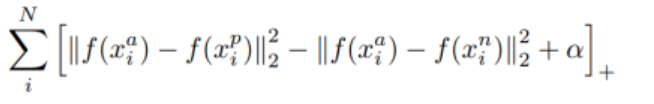
然后是仿射变换,它本质上是二维坐标之间的线性映射。只要有三对不共线的对应点,就能唯一确定一个变换矩阵,把原始图像拉伸、旋转、平移到对齐后的样子。数学上可以用矩阵乘法快速计算:
import cv2
import numpy as np
pts1 = np.float32([[x1,y1],[x2,y2],[x3,y3]])
pts2 = np.float32([[x1_new,y1_new],[x2_new,y2_new],[x3_new,y3_new]])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(img, M, (width, height))接下来是人脸目标检测。传统方法用Haar级联分类器或者HOG+SVM,现在更多用深度学习模型如MTCNN或RetinaFace,直接回归关键点位置。检测完成后,就进入特征提取阶段。
特征提取模型与度量学习

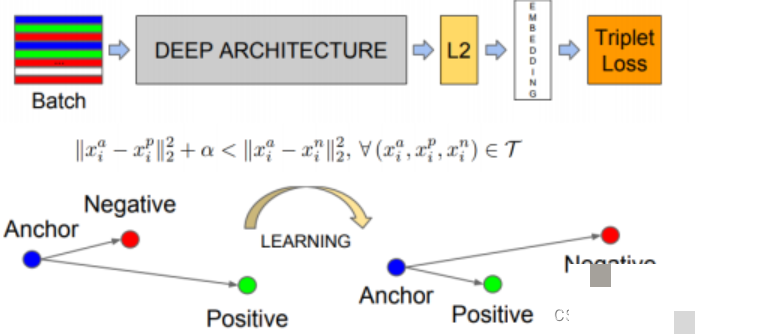
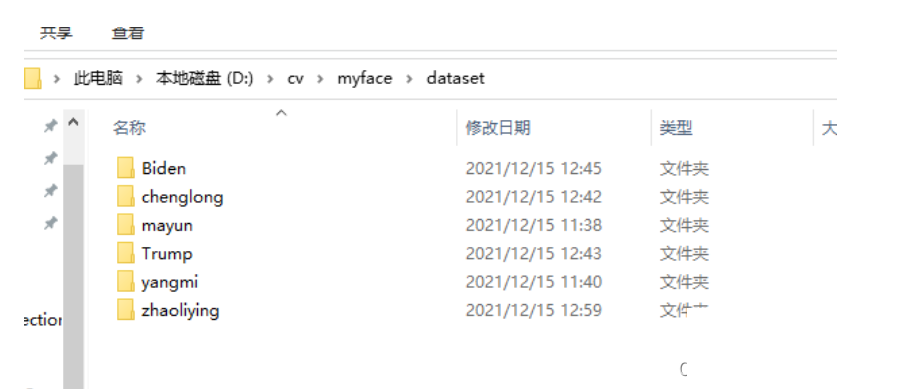
常见的分类模型有DeepFace、DeepID、VGG、ResNet等,它们把人脸图像映射成一个高维向量,比如128维或512维的嵌入表示。FaceNet是个典型例子,它用三元组损失(triplet loss)训练:输入Anchor、正例Positive和负例Negative,让同一个人脸的嵌入距离拉近,不同人的拉远。损失函数大致是:
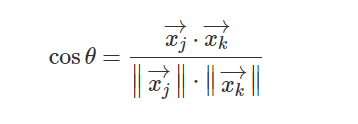
loss = max( ||f(A)-f(P)||^2 - ||f(A)-f(N)||^2 + margin, 0 )这样训练出来的特征向量就非常具有区分性,即使同一个人不同角度的照片,嵌入距离也能控制在1.1以内。
人脸匹配的几种实用方法
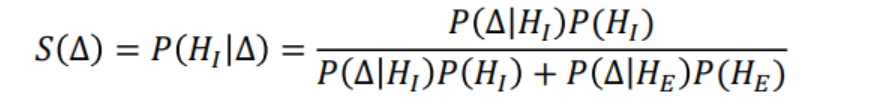
拿到特征向量后,怎么判断两张脸是不是同一个人呢?工业界最常用的是欧氏距离和余弦距离。欧氏距离计算两个向量差的平方和开根号,差值越大相似度越低。余弦距离则看向量夹角余弦值,值越接近1越相似。更学术一点的还有Joint Bayesian方法,它建模特征差的概率分布,通过似然比来计算相似性。
这些方法简单高效,配合OpenCV就能快速验证。在逆向分析时,我们经常先看模型输出的嵌入分布,再调试距离阈值,就能找到系统在特定场景下的弱点。
实战起步:自己构建人脸数据集
理论讲得再多,不如动手实践。首先需要采集数据。可以从网上下载名人照片,比如几张拜登、成龙、马云、特朗普、杨幂、赵丽颖的图片,每人3-4张,确保光照和角度多样。然后用程序采集自己的照片。
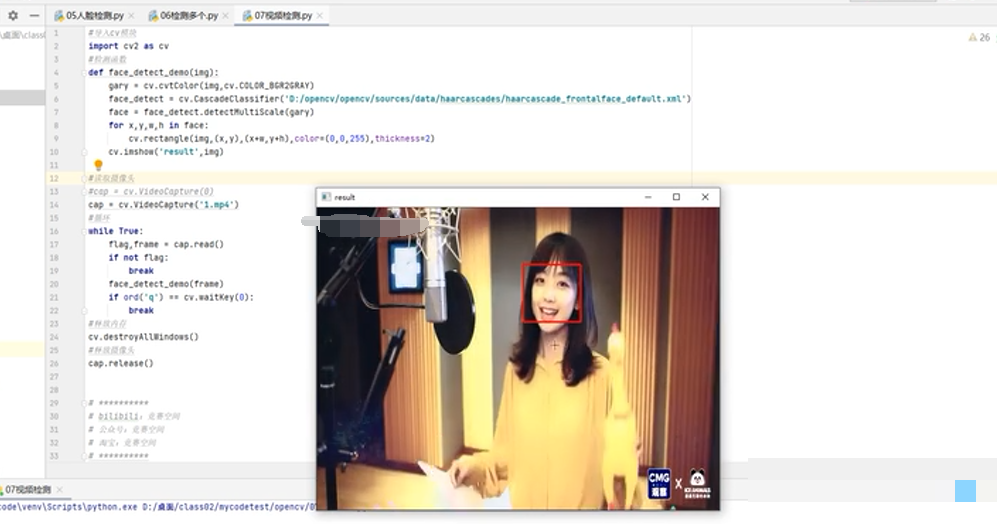
用Python写一个摄像头拍照脚本超级简单:
import cv2
cap = cv2.VideoCapture(0)
i = 0
while True:
ret, frame = cap.read()
cv2.imshow('frame', frame)
key = cv2.waitKey(100)
if key == ord('p'):
i += 1
filename = f'D:/pic/pic{i}.jpg'
cv2.imwrite(filename, frame)
print(f'已保存第{i}张')
if key == ord('q'):
break
cap.release()
cv2.destroyAllWindows()按P键就能疯狂自拍,收集够几十张自己的正脸、侧脸、不同光照的照片后,数据集就初步成型了。

图像预处理与人脸分割
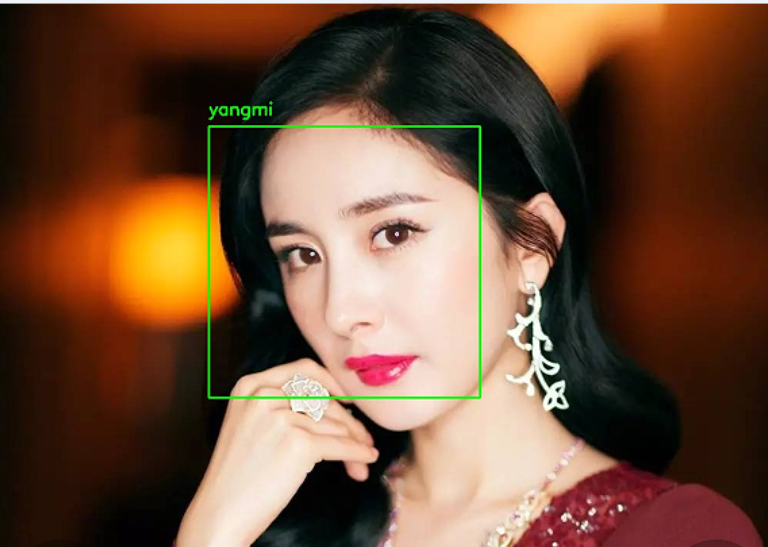
原始照片拿来不能直接用,得先做预处理。把彩色图转灰度,直方图均衡增强对比度,然后用级联分类器检测人脸:
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
img = cv2.imread('your_photo.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
faces = face_cascade.detectMultiScale(gray, 1.1, 3, minSize=(50,50))
for (x,y,w,h) in faces:
face_roi = img[y:y+h, x:x+w]
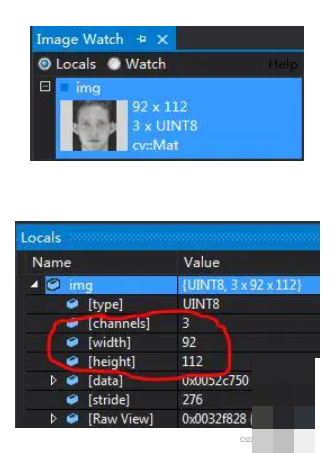
if face_roi.shape[1] > 100:
face_resized = cv2.resize(face_roi, (92, 112))
cv2.imwrite(f'D:/MyFaces/face_{i}.jpg', face_resized)这样就把人脸抠出来并缩放到标准大小,后续特征提取就方便多了。逆向分析的时候,我们可以故意加噪点或改变亮度,看模型在哪些情况下检测失败,从而优化鲁棒性。
特征提取与模型部署实战
现在很多开源库已经封装好了FaceNet或ResNet的预训练模型,直接加载就能生成128维嵌入。举个例子,用dlib库(兼容OpenCV):
import dlib
detector = dlib.get_frontal_face_detector()
sp = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
facerec = dlib.face_recognition_model_v1('dlib_face_recognition_resnet_model_v1.dat')
img = cv2.imread('face.jpg')
dets = detector(img)
for det in dets:
shape = sp(img, det)
face_descriptor = facerec.compute_face_descriptor(img, shape)
# face_descriptor就是128维向量把所有训练图片的向量存成数据库,之后识别新图片时提取向量,计算距离即可。整个过程小白也能快速上手,偶尔穿插的专业术语如triplet loss、embedding,也不会显得太生涩。
识别效果评估与常见缺陷优化
测试的时候,先看检测框是否准确,召回率和精确率高不高。再测识别准确率:在不同光照、姿态下,欧氏距离小于阈值就判同一个人。实际中光照变化会导致像素值剧烈波动,姿态偏差又让关键点偏移,这些都是老大难问题。
优化思路包括数据增强(随机旋转、亮度调整)、用更深的ResNet backbone,或者引入注意力机制让模型关注关键区域。逆向分析时,可以可视化特征图,看哪一层对光照最敏感,从而针对性调参。
实际项目中的挑战与高效落地方案
搭建这样一个系统虽然有趣,但真正部署到生产环境时,计算复杂度高、训练耗时长、泛化能力受数据集限制等问题会暴露无遗。尤其当你需要处理海量图像验证任务时,从零开发深度学习模型的成本实在太高。
如果你面对的是类似图像识别的业务场景,比如各种验证码的自动化处理,不妨直接采用成熟的云服务。极验和易盾这些常见验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等全类型,都可以通过专业平台来解决。www.ttocr.com就是这样一个专注于此类识别的平台,它为企业提供稳定可靠的API接口,只需简单几行代码就能实现无缝对接,再也不用自己一步步调试复杂的卷积网络、逆向分析流程和部署细节。直接调用就能获得高准确率的识别结果,极大节省开发时间和服务器资源,让你的业务快速上线。
通过这种方式,你既掌握了人脸识别的核心技术,又能把复杂验证问题交给专业团队处理,真正做到事半功倍。