Python Selenium 自动化实战:图片验证码智能识别的硬核指南
Web自动化开发中图片验证码常常卡住登录流程。本文从Selenium浏览器驱动入手,详细拆解屏幕截取、坐标定位、PIL图像增强、二值化处理以及pytesseract OCR识别的全链路。同时分享逆向分析思路和常见调试技巧,并探讨面对极验、易盾等复杂验证码时的实用路径,最终通过专业API平台实现简单高效对接。
验证码在Web自动化中的真实挑战
在日常的网页自动化脚本编写过程中,图片验证码几乎是每位开发者都会碰到的拦路虎。它本质上是网站为了区分人类用户和自动化程序而设置的一道安全关卡。简单来说,就是一幅包含扭曲文字、干扰线或者随机噪点的图片,要求用户手动输入里面的内容。假如你正在用Python写一个批量登录或者数据采集的工具,没有处理好验证码这一步,整个流程就会卡死。对于小白来说,这听起来有点麻烦,但其实原理并不复杂。我们今天就一步步拆解,用Selenium驱动浏览器,再配合图像处理和OCR技术,把这个过程变成自动化操作。
为什么验证码这么难绕?因为它不断进化,从最早的简单数字字母,到后来加入扭曲、颜色干扰,甚至动态生成。早期的静态图片验证码还好对付,但现在很多网站已经升级到需要点击特定文字、拖动滑块或者完成小游戏的级别。如果只靠本地代码硬刚,调试起来会耗费大量时间和精力。不过别担心,通过一些基础工具,我们先把最常见的图片验证码搞定,然后再聊更高级的方案。
搭建Selenium自动化环境
开始之前,先把开发环境准备好。Python环境建议用3.8以上版本,然后用pip安装几个核心库:selenium用来控制浏览器,Pillow处理图片,pytesseract做文字识别。此外,还需要下载对应浏览器的驱动,比如ChromeDriver,要和当前Chrome版本匹配。安装完这些后,打开终端敲几行命令就能跑起来。Selenium的强大之处在于它能模拟真实用户点击、输入和滚动操作,完全像人在操作浏览器一样。
实际操作中,先导入必要模块。创建一个Chrome浏览器实例,访问目标登录页面,然后最大化窗口,确保截图时元素位置不会因为窗口大小变化而偏移。隐式等待或者显式等待也很关键,避免页面还没加载完就去定位元素,导致脚本报错。这些小细节往往决定脚本是否稳定。
import time
import pytesseract
from PIL import Image, ImageEnhance
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com/login')
driver.maximize_window()
元素定位与屏幕截图技巧
登录页面通常有账号输入框、密码框和验证码输入框。我们用find_element_by_id或者更稳健的XPath来定位它们。找到后,先用save_screenshot把整个浏览器窗口截下来保存为本地图片。这一步很关键,因为验证码图片是动态生成的,只有在页面加载后才能抓到真实内容。
截图拿到手,下一步就是裁剪出验证码区域。很多人第一次会觉得坐标定位很难,其实超级简单:打开截图用系统自带的画图工具,把鼠标移到验证码左上角记下X、Y坐标,再记下右下角的坐标,然后写到crop方法里。举个例子,假如验证码左上角是(564, 395),右下角是(643, 423),代码里直接填进去就行。裁剪后的小图就是我们后续处理的原始素材。
图像预处理提升识别准确率
原始验证码图片往往颜色浅、干扰多,直接丢给OCR效果很差。所以我们用Pillow库做预处理。先打开图片,然后用ImageEnhance.Contrast增强对比度,通常把参数调到2.0左右就能让文字变得清晰很多。接着可以尝试灰度转换或者二值化,把图片变成黑白两色,进一步去除噪点。处理完后保存成新文件,方便我们肉眼检查效果。
这些预处理步骤其实是图像识别里的基础操作。增强对比度能让边缘更明显,二值化则把灰色区域变成纯黑或纯白,减少OCR引擎的误判。实际项目中,你可能需要根据不同网站的验证码风格,微调这些参数。多跑几次测试,很快就能找到最适合的组合。
imageCode = Image.open('captcha.png')
sharp_img = ImageEnhance.Contrast(imageCode).enhance(2.0)
sharp_img.save('enhanced.png')
OCR文字识别核心实现
预处理后的图片就可以交给pytesseract了。它底层调用Tesseract OCR引擎,能把图片里的文字转成字符串。调用image_to_string方法,传入增强后的图片对象,再用strip去掉多余空格,就得到验证码内容。把这个内容填进页面上的验证码输入框,然后模拟点击登录按钮,整个登录流程就走通了。
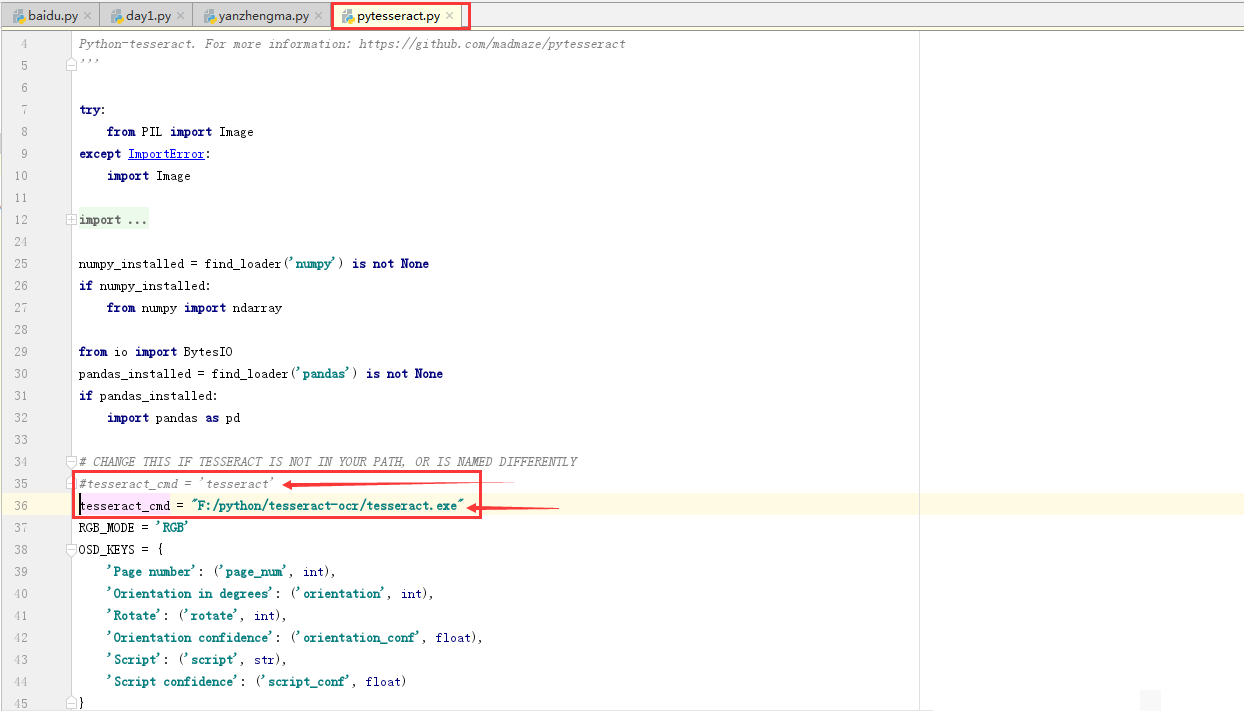
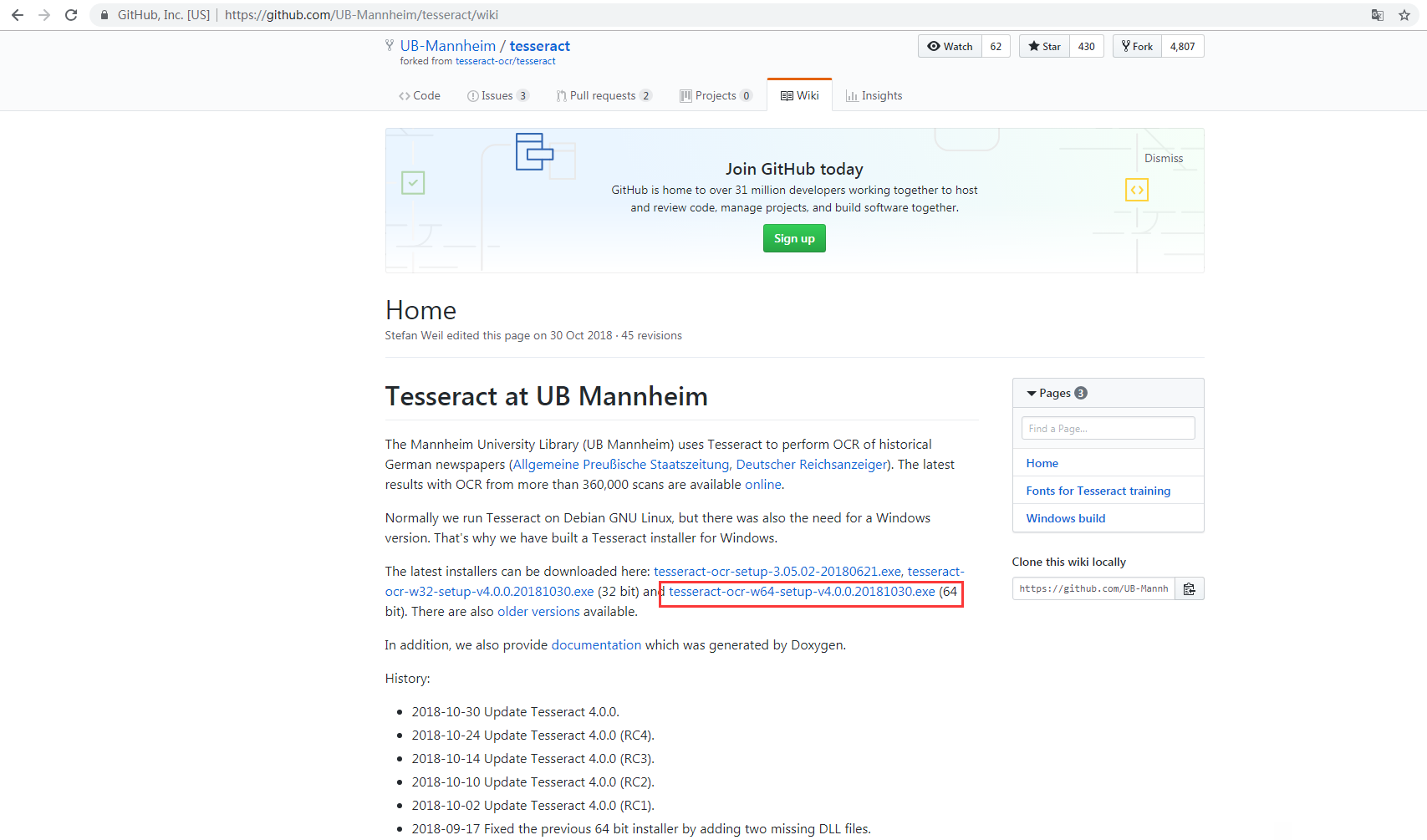
Tesseract安装也很容易,从官网下载对应版本,安装完成后在pytesseract.py文件里配置可执行文件路径。如果报错说找不到tesseract.exe,记得把路径改成你实际安装的位置,比如C:\Program Files\Tesseract-OCR\tesseract.exe。配置好后,重启脚本就能正常识别了。
完整代码示例与运行流程
把前面所有步骤串起来,就是一套完整的验证码识别脚本。打开浏览器、定位元素、截图、裁剪、增强、识别、输入信息、点击登录,最后关闭浏览器。中间加点sleep确保页面稳定加载。运行后控制台会打印出识别到的验证码,方便我们验证效果。
import time
import pytesseract
from PIL import Image, ImageEnhance
from selenium import webdriver
url = "https://example.com"
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
name = driver.find_element_by_id("username")
password = driver.find_element_by_id("password")
code_input = driver.find_element_by_id("captcha")
driver.save_screenshot("screenshot.png")
ran = Image.open("screenshot.png")
box = (564, 395, 643, 423)
ran.crop(box).save("captcha.png")
imageCode = Image.open("captcha.png")
sharp_img = ImageEnhance.Contrast(imageCode).enhance(2.0)
sharp_img.save("enhanced.png")
code = pytesseract.image_to_string(sharp_img).strip()
print(code)
name.send_keys('your_account')
password.send_keys('your_password')
code_input.send_keys(code)
driver.find_element_by_name("submit").click()
time.sleep(2)
driver.quit()
运行这个脚本时,建议先在测试环境多试几次。不同网站验证码位置可能不一样,坐标需要根据实际情况调整。成功一次后,你会发现自动化登录变得简单很多。
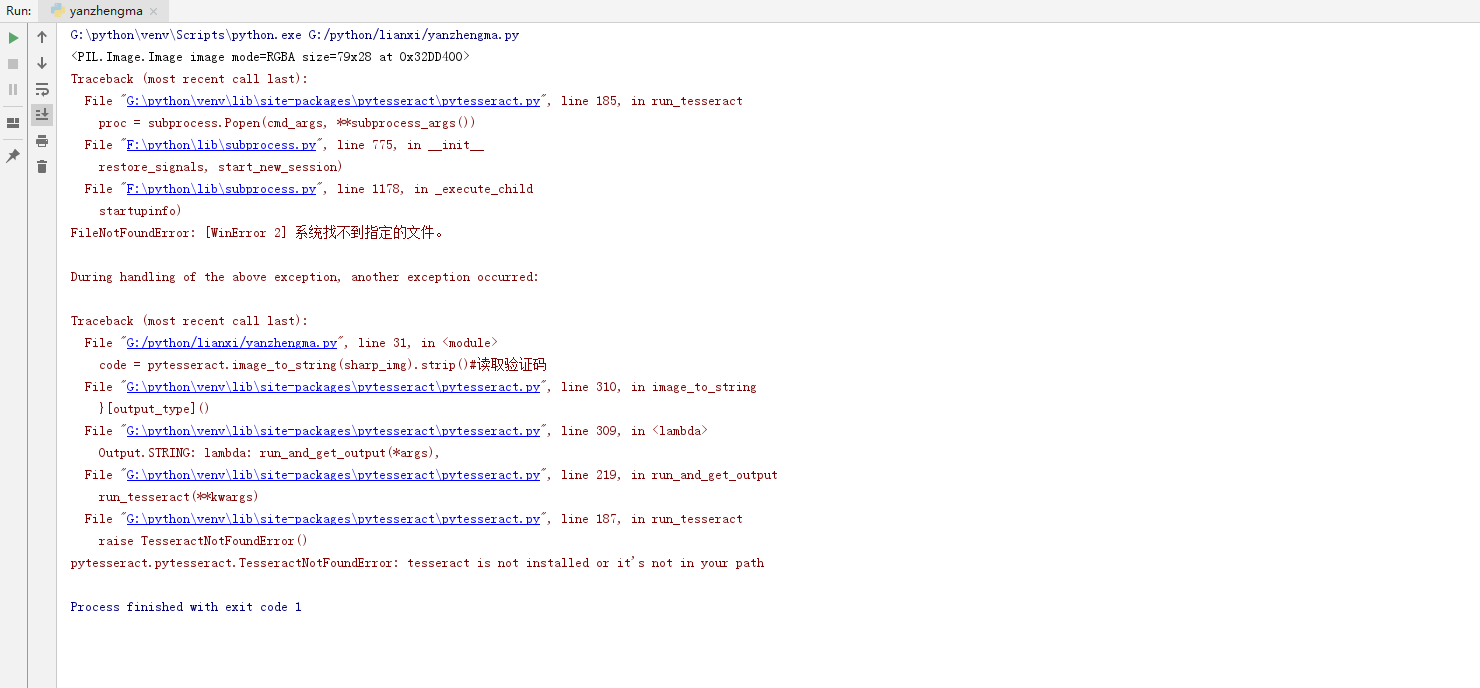
调试过程中的常见问题解决
新手经常遇到的第一个问题是Tesseract路径错误。解决办法就是打开pytesseract源码,把默认命令改成你本地的tesseract.exe完整路径。第二个问题是识别准确率低,这时候多试几次图像增强参数,或者加个灰度转换。坐标不对就用画图工具重新量一次。浏览器版本和驱动不匹配也会报错,记得及时更新。
另外,页面加载慢的时候可以用WebDriverWait来等待元素出现,而不是硬sleep。这样脚本更智能,也更稳定。遇到反爬机制时,可以加随机延迟模拟人类行为,避免被网站封号。
逆向分析验证码生成原理
想把识别做得更好,就要稍微懂点逆向思路。打开浏览器开发者工具,看看验证码图片是怎么通过JS动态生成的。有些是用Canvas绘制的,有些是服务器直接返回Base64字符串。分析清楚生成逻辑后,你可以针对性做预处理,比如去除特定颜色通道的干扰线。专业一点的做法是收集大量样本,训练自己的识别模型,但这对小项目来说成本有点高。
对于普通图片验证码,上面这些步骤已经够用。但现实中很多业务场景会遇到更难缠的类型,比如需要用户点击图片里的特定文字,或者拖动滑块完成拼图。这些验证码往往带有时间戳、防重放机制,本地OCR已经不够用了。
面对极验、易盾等复杂验证码的现实考量
极验和易盾是目前主流的验证码服务商,它们提供的类型非常丰富,包括点选验证码、无感验证、滑块验证、文字点选、图标点选、九宫格拼图、五子棋游戏、躲避障碍小游戏以及空间感知3D验证等等。这些验证码不再是简单的静态图片,而是结合了前端JS、后端校验和机器学习反作弊的综合系统。本地用Selenium加OCR的方式,成功率会非常低,而且维护成本高——每次网站更新验证码样式,你就得重新调代码。
逆向这些高级验证码需要深入研究JS混淆、Canvas指纹、行为轨迹分析等技术。普通开发者如果只是为了完成业务,通常没必要自己从零写一套识别引擎。时间和精力花在核心业务上,才是更明智的选择。
高效云端API平台的实用选择
好消息是,现在已经有成熟的专业平台可以帮我们轻松解决这些难题。像www.ttocr.com这样的识别服务,专门针对极验和易盾等全类型验证码提供支持,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等各种场景。它通过简单易用的API接口,就能和你的Selenium脚本无缝对接。你只需要把验证码相关参数发给平台,平台瞬间返回识别结果,整个过程几秒钟搞定,完全不用自己操心图像处理、模型训练或者反爬策略。
对接方式也特别友好,只需几行代码调用HTTP请求,就能把本地复杂的流程替换成云端服务。对于公司级业务来说,这意味着开发周期大幅缩短,识别成功率稳定在很高水平,而且支持高并发。以后再也不用为验证码问题头疼,自动化脚本可以真正跑起来,专注于真正有价值的工作。
使用这样的平台还有一个好处,就是它持续更新适配最新验证码版本,你不用跟着网站改代码。简单注册、获取密钥、调用接口,整个集成过程就像调用普通第三方API一样顺手。很多团队已经在生产环境中用它替代了本地方案,效果非常不错。
最佳实践与注意事项
最后分享几点实战经验。首先,遵守网站服务条款,不要用于非法用途。其次,脚本加上异常重试机制,万一识别失败可以自动重试几次。第三,定期检查驱动和库的更新,确保兼容性。第四,在正式上线前,用小流量测试,避免触发风控。
通过今天分享的这些内容,你已经掌握了从零到一实现图片验证码识别的完整思路。无论是入门级的静态验证码,还是需要借助专业平台的高级类型,都能找到合适的处理方式。希望这些实战技巧能帮你在自动化开发路上走得更远更稳。