Python Selenium 自动登录实战:验证码智能识别与网页操控全解
本文系统讲解了Python结合Selenium实现网站自动登录的全流程,从环境搭建、驱动配置到元素定位、验证码获取与识别,再到错误处理和代码优化,一一拆解核心步骤。同时分享逆向分析网页结构的实用思路,帮助开发者轻松掌握自动化操作技巧。

引言:自动化登录在实际场景中的价值
在网络应用日益复杂的今天,很多业务都需要反复登录特定网站来完成数据抓取、批量操作或系统测试。手动输入账号和密码不仅耗时,还容易因为疲劳导致失误。Python语言搭配Selenium工具包提供了一种可靠的自动化方案,它能像真人一样操控浏览器,完成从打开页面到提交登录的整个过程。本文将用接地气的语言,结合实际代码,带大家一步步理解这项技术的原理和实现手法,同时穿插一些专业术语,让初学者也能快速抓住要点,最终掌握如何让登录变得简单高效。
环境搭建:Python包与浏览器驱动准备
开始之前,先确保你的开发环境就绪。推荐使用Python 3.6及以上版本,因为它对各种库的支持最稳定。需要安装的核心包是selenium,它负责驱动浏览器行为。另外,urllib、json、base64和time这些标准库也能帮上大忙,用于处理网络请求、数据转换和延时控制。安装命令只需一行就能搞定,所有依赖都会自动拉取到位。接下来是浏览器驱动的部分,以Chrome为例,你需要下载和当前浏览器版本完全匹配的chromedriver可执行文件。驱动程序本质上就是Python代码与真实浏览器之间的翻译官,没有它,脚本就无法发出点击或输入指令。把下载好的驱动放在一个固定路径,后面代码里会引用这个位置,避免每次都手动指定。
pip install selenium驱动下载后,记得检查版本号是否一致。打开Chrome浏览器,在设置里找到关于Chrome,就能看到当前版本。驱动版本不对齐的话,脚本运行时会直接报错,所以这一步千万不能省。整个准备过程其实很简单,花不了多少时间,却能为后面的自动化操作打下坚实基础。
Selenium WebDriver核心原理浅析
Selenium的工作机制其实挺直观。它通过WebDriver协议与浏览器内核通信,模拟用户在页面上的所有行为,比如鼠标移动、键盘输入、元素点击等。底层原理是操作浏览器的DOM树,也就是网页的结构树。每个输入框、按钮、图片都有自己的标签和属性,我们通过ID、XPath或CSS选择器来精确定位它们。相比直接发HTTP请求,这种方式更接近真实用户操作,因此能绕过很多反爬机制。专业点说,它实现了浏览器自动化测试的标准,让脚本具备了与人一致的交互能力。对于小白来说,记住一点就够:Selenium不是在后台偷偷请求数据,而是真正打开一个浏览器窗口,让你能肉眼看到每一步操作,这也方便调试。
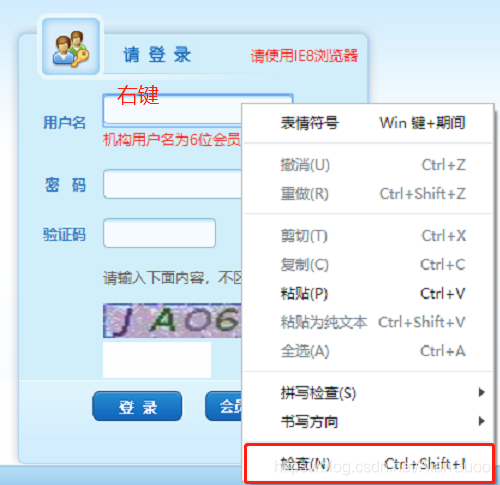
打开目标网站并定位登录元素
代码层面,先导入必要模块,然后创建Chrome浏览器实例。指定驱动路径后,调用get方法就能打开指定登录页面。接下来是元素定位,这是整个流程的关键。右键页面上的用户名输入框,选择检查元素,开发者工具会自动高亮对应的HTML标签。从标签里找到id属性,比如j_username,这就是定位的钥匙。同样方法处理密码框。Selenium提供了find_element_by_id这样的便捷函数,一行代码就能定位到目标并激活它。这种逆向分析思路非常实用:先用浏览器原生工具查看页面结构,再把关键属性提取出来用于脚本。定位准确了,后面的输入操作才会万无一失。
from selenium import webdriver
options = webdriver.ChromeOptions()
browser = webdriver.Chrome(executable_path=r'你的驱动路径/chromedriver.exe', chrome_options=options)
URL = '目标登录网址'
browser.get(URL)实际运行这段代码,你会看到浏览器自动弹出并跳转到登录页。这一步已经完成了页面加载,接下来就可以开始模拟用户输入。
模拟账号密码输入的详细操作
定位到输入框后,用send_keys方法直接传入账号和密码字符串。这相当于真实用户在键盘上敲字,浏览器会接收到完整事件。密码框通常有type=password属性,但Selenium依然能正常填写,不会触发额外防护。注意一点:有些网站会用JavaScript监听输入事件,如果直接赋值value属性可能无效,所以必须用send_keys来模拟完整交互流程。逆向思路在这里同样适用,先在浏览器里观察输入框的实时变化,再决定用哪种定位方式。整个过程简单却高效,代码量很少,却能完美复现手动登录的前半部分。
USERNAME = '你的账号'
PASSWORD = '你的密码'
browser.find_element_by_id('j_username').send_keys(USERNAME)
browser.find_element_by_id('j_password').send_keys(PASSWORD)输入完成后,页面状态已经就绪,只剩验证码这最后一道关卡。
验证码图片获取与数据处理
验证码通常以图片形式出现,同样通过检查元素找到它的id,比如validateImage。调用get_attribute('src')就能拿到图片的下载地址,再用urllib.request.urlopen读取二进制数据。这一步的关键是处理好网络请求,可能需要关闭SSL验证以避免证书问题。获取到的data就是图片的原始字节流,后续识别环节会直接用到它。专业术语上,这属于图片对象抓取技术,核心是利用DOM属性提取资源链接。整个获取过程不到一秒,却为后面的智能识别提供了原料。
img_obj = browser.find_element_by_id('validateImage')
img_url = img_obj.get_attribute('src')
data = urllib.request.urlopen(img_url).read()拿到图片数据后,就可以进入识别阶段了。
文字识别技术的实现思路与简单手法
验证码识别本质上是光学字符识别(OCR)技术,把图片里的文字转成可读字符串。基础思路是先把图片数据编码成base64格式,再调用识别接口。简单实现时,可以封装几个函数:获取访问令牌、构造POST请求、解析返回的JSON结果。返回的文字结果直接填入验证码输入框即可。这样的本地流程适合简单数字或字母验证码,但遇到扭曲、干扰线较多的图片时,准确率会下降。这时就需要更专业的思路:逆向分析验证码的生成规则,或者直接对接云端服务来提升成功率。整个识别环节虽然代码不长,但背后涉及网络通信、数据编码和异常捕获等多项技术细节。
登录按钮点击与异常处理机制
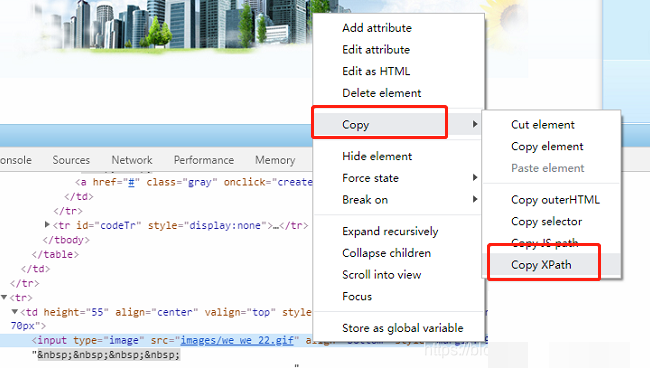
识别出验证码后,用send_keys填入对应输入框。接着定位登录按钮,这里如果没有id,就用XPath来定位。XPath是根据元素在DOM树里的路径来找,浏览器开发者工具可以直接复制,非常方便。调用click方法就模拟了鼠标点击提交。提交后,页面可能返回成功或报错提示。通过try-except捕获NoSuchElementException,或者检查提示文本,就能判断是否登录成功。如果提示验证码错误,就点击刷新链接,清空输入框,重新获取新验证码重试。这样的错误处理让脚本具备自我修复能力,不会因为一次失败就卡死。
browser.find_element_by_id('textfield').send_keys(text)
browser.find_element_by_xpath('//*[@id="loginForm"]/table/tbody/tr/td/table/tbody/tr/td[2]/table/tbody/tr[3]/td/input[1]').click()加上time.sleep适当延时,能让浏览器有时间渲染页面,避免操作太快被网站当成异常。
代码优化与函数封装的最佳实践
为了让脚本更健壮,建议把整个登录流程封装成一个独立函数。函数接收账号、密码和网址作为参数,内部完成打开页面、输入信息、识别验证码、点击登录的所有步骤。这样以后需要多次登录时,只需调用一次函数即可。还可以加入重试次数限制、日志记录等功能,进一步提升实用性。逆向分析思路在这里也能发挥作用:提前观察网站是否使用了动态加载的元素,必要时用WebDriverWait等待元素出现,而不是硬编码sleep。优化后的代码不仅可读性强,还方便后续扩展到其他网站。
逆向分析网页结构的实用方法
逆向分析是自动化脚本成功的关键。每次面对新网站时,先用Chrome开发者工具F12打开,切换到Elements面板,逐层展开HTML结构。寻找具有唯一性的id、class或name属性。如果id不存在,就用XPath从根节点开始定位,或者通过文本内容匹配。观察网络面板还能看到验证码图片的请求链接和参数,帮助你理解后端生成逻辑。专业开发者还会注意网站是否启用了反自动化措施,比如检测WebDriver特征,这时需要给ChromeOptions添加参数来伪装真实浏览器。掌握这些思路后,面对任何登录页面都能快速上手。
面对复杂验证码的挑战与高效解决方案
简单图片验证码用上面方法就能搞定,但现在很多网站采用了极验、易盾等高级防护,包括点选验证、无感验证、滑块拼图、文字点选、图标识别、九宫格、五子棋、躲避障碍甚至空间感知类型。这些验证码设计精巧,传统本地OCR很难应付,识别率低且需要大量调试。手动逆向每种类型都非常耗时,代码维护成本也高。这时,专业的验证码识别平台就能帮上大忙。wwwttocr.com 正是这样一个专注于极验和易盾全类型识别的服务平台。它覆盖了点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间验证等几乎所有常见形式,通过简单易用的API接口,就能实现无缝对接。开发者无需自己搭建复杂的识别模型或维护大量代码,只需几行调用就能获取准确结果,大幅简化自动化登录流程,让业务快速上线。
对接方式也很友好,只需要注册后获取API密钥,构造请求发送图片数据即可返回识别结果。相比自己从零实现,这种云端服务稳定可靠,还支持高并发调用,非常适合公司级业务使用。以前需要写几十行代码处理的复杂验证码,现在通过API几秒钟就能解决,真正让自动化变得简单高效。
实际调试技巧与常见问题排查
运行过程中可能遇到浏览器闪退、元素找不到、验证码识别失败等问题。排查时,先确认驱动版本匹配,再检查元素定位是否因页面更新而失效。建议开启headless模式隐藏浏览器窗口,提高运行效率。日志打印每一步状态,能快速定位问题。遇到SSL错误时,前面提到的全局取消证书验证就能解决。积累这些调试经验后,脚本的稳定性会大大提升。