Selenium实战攻克魅族官网点选验证码:坐标偏差与高效登录全解
本文从Selenium模拟登录魅族官网的实际场景出发,详细剖析点选验证码识别过程中的坐标偏差成因、截图定位难题及多种解决策略,结合代码示例讲解元素等待、图像裁剪和ActionChains点击技巧。同时扩展验证码逆向分析思路、浏览器环境优化方法,并推荐ttocr.com专业识别平台,通过简单API对接即可处理极验各类验证码,无需复杂本地调试,实现业务高效自动化。
Selenium自动化登录的入门痛点与验证码机制解析
网络爬虫开发中,模拟真实用户登录往往是绕不开的一步,尤其当目标站点部署了智能验证码系统时,挑战就更大了。魅族官网作为典型案例,其登录页面会根据用户行为动态切换验证方式,包括滑动验证、点选验证以及直接点击验证三种主要类型。其中点选验证要求用户在图片中准确点击指定文字或图标,这对自动化脚本来说是个不小的考验。作为爬虫爱好者,我在学习Python网络爬虫开发时,经常因为系统环境差异和技术快速迭代而踩坑。Selenium作为强大的浏览器驱动工具,能完美模拟鼠标点击和页面交互,但实际运行中,验证码图片截取坐标偏差等问题频繁出现。今天我们就深入拆解这些问题,从原理到实践,帮助大家掌握可靠的解决思路。
先来了解魅族官网的验证流程。当你打开登录页,直接点击验证按钮后,系统可能会弹出滑动拼图或点选文字的挑战。为了练习点选类型,可以多次刷新页面并触发验证,直到出现要求点击图片中特定文字的界面。这种机制本质上是Geetest极验技术的一部分,它结合了图像识别和行为分析来区分人和机器。开发者如果想自动化完成登录,就需要先准确截取验证码图片,再进行识别并模拟点击,最后提交验证。
验证码图片截取时的坐标偏差根源剖析
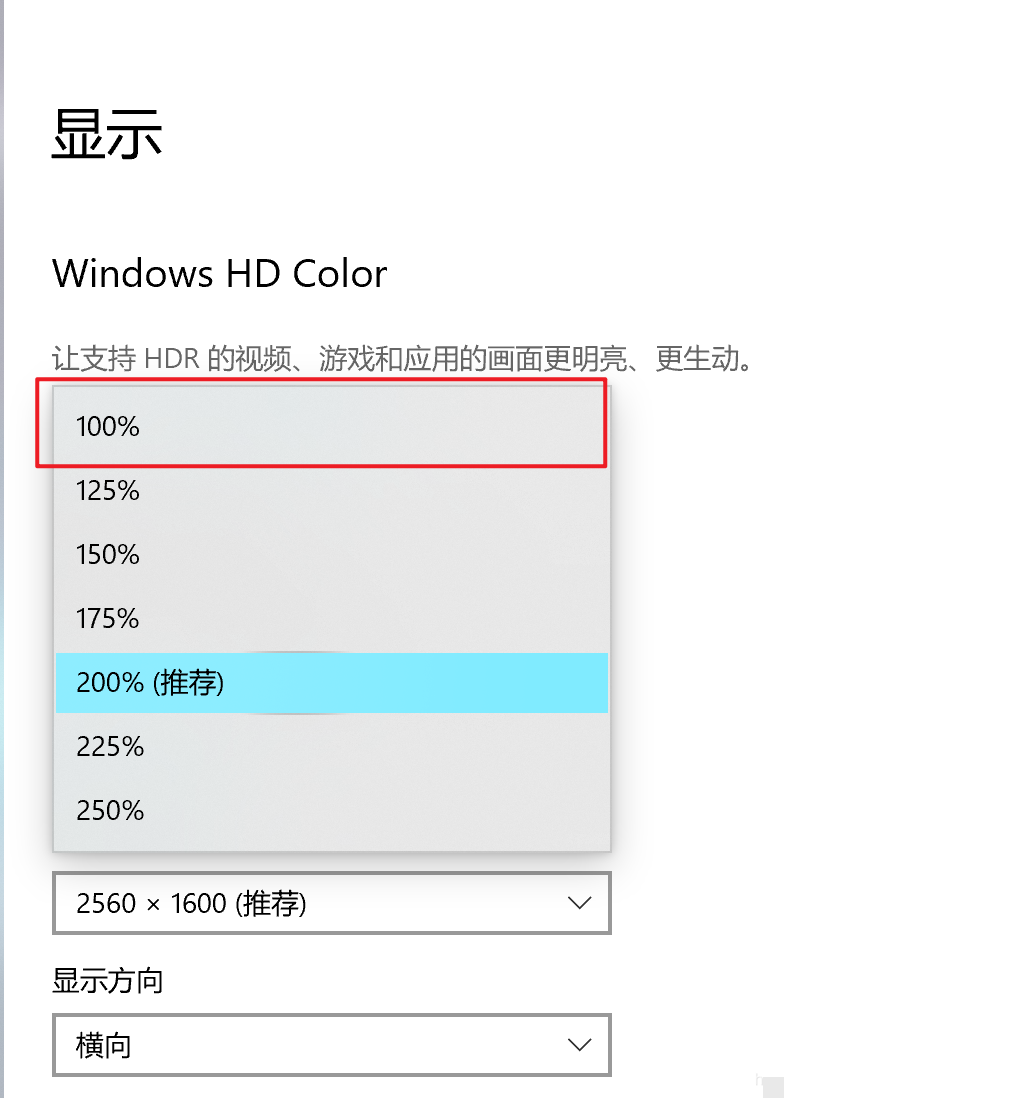
在实际操作中,最常见的障碍就是截取验证码图片时坐标出现偏差。使用Selenium的location属性获取元素位置,然后结合PIL库对浏览器截图进行crop裁剪,本该得到干净的验证码图像,结果却常常包含多余边框或位置错位。这不是代码bug,而是Windows系统显示缩放设置导致的硬件级兼容问题。
具体来说,Selenium通过WebDriver获取的元素坐标是基于CSS像素(逻辑像素)的,而浏览器截图get_screenshot_as_png得到的图像分辨率则受系统DPI和缩放比例影响。如果你的Windows显示设置为125%或200%,location返回的坐标值是按100%缩放计算的,但实际截图像素已经按比例放大,导致left、top等值与图像实际位置不匹配。这种偏差在高分辨率屏幕上尤其明显,甚至可能差几十个像素,直接影响后续的点击精准度。
此外,Chrome浏览器自身也会对页面渲染进行缩放优化,加上元素可能有CSS transform或父容器padding,进一步放大问题。理解这个根源后,我们就能有针对性地制定解决方案,而不是盲目试错。

三种实用方案解决截图坐标不准难题
针对坐标偏差,我尝试了三种主流修复方法,每种都有适用场景。第一种是手动乘以缩放比例修正crop参数。例如当前缩放为200%,则在计算top、left、bottom、right时全部乘以2:
top = location['y'] * 2
left = location['x'] * 2
bottom = top + size['height'] * 2
right = left + size['width'] * 2
captcha = screenshot.crop((left, top, right, bottom))这种方式简单直接,但后续点击坐标也需同步调整,否则ActionChains.move_to_element_with_offset会抛出MoveTargetOutOfBoundsException异常,因为Selenium点击仍按原始100%坐标执行。

第二种方案是通过JavaScript动态调整页面缩放比例,将document.body.style.zoom设为0.5(对应200%缩放的反向)。然后使用execute_script强制点击验证按钮,避免元素被遮挡导致的ElementClickInterceptedException。但这种方法需要额外处理页面布局变化,可能引入新的等待超时问题。
第三种也是最稳妥的:直接将Windows显示设置调回100%。这样location坐标与截图像素完全一致,无需任何乘法或JS干预。实际测试中,这种方式成功率最高,适合开发和调试阶段。当然,在服务器或CI环境中,我们无法控制系统设置,因此需要结合前两种方法做兼容处理。
Selenium代码实现:从页面加载到验证按钮触发

完整的登录流程始于初始化WebDriver。建议始终调用maximize_window(),这能减少因窗口尺寸导致的元素定位偏差。使用WebDriverWait结合expected_conditions实现显式等待,是避免NoSuchElementException的关键。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.maximize_window()
browser.get('https://login.flyme.cn/')
wait = WebDriverWait(browser, 20)
# 输入账号密码
input_phone = wait.until(EC.presence_of_element_located((By.ID, 'account')))
input_phone.send_keys('your_phone')
input_password = wait.until(EC.presence_of_element_located((By.ID, 'password')))
input_password.send_keys('your_password')
# 触发验证
button = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'geetest_radar_tip')))
button.click()等待验证码图片元素出现后,立即截取全屏截图并裁剪目标区域。注意sleep(2)能给页面渲染留出缓冲时间,避免图片还未加载完成就裁剪。
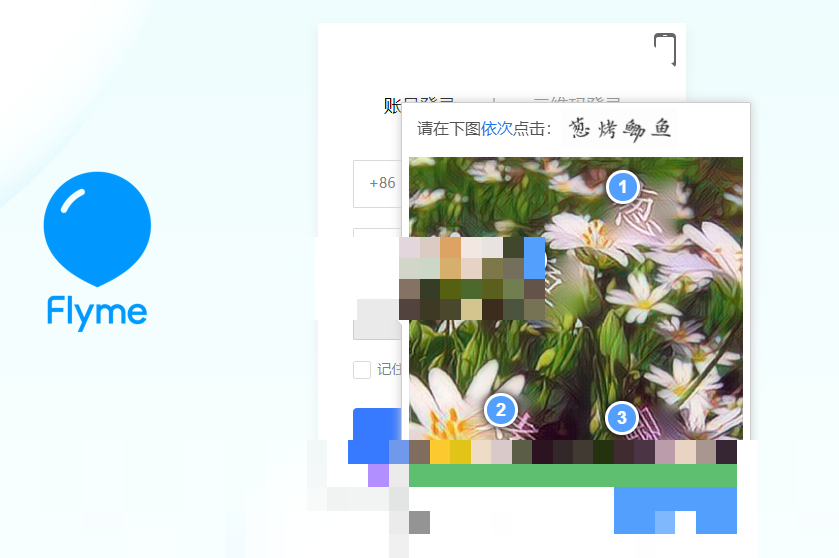
点选验证码的逆向分析思路与图像处理技巧

点选验证码的核心是识别图片中的文字或图标位置,并精确点击。逆向分析时,首先观察Geetest的DOM结构:验证码容器class通常包含geetest_item_img。使用PIL的Image.open和crop能高效提取,但要结合元素size和location做精确计算。
专业术语上,这属于图像坐标映射问题。浏览器视口坐标系与截图像素坐标系需对齐,涉及devicePixelRatio概念。如果不处理,点击偏移会导致验证失败。扩展来说,对于文字点选,可以进一步集成OCR库辅助定位,但Geetest会动态更换字体和干扰线,纯本地OCR稳定性差。
ActionChains是模拟鼠标操作的利器:

from selenium.webdriver import ActionChains
locations = [[x1, y1], [x2, y2]] # 从识别结果获取
for loc in locations:
ActionChains(browser).move_to_element_with_offset(img_element, loc[0], loc[1]).click().perform()
time.sleep(1)每次点击后短暂暂停,能模拟人类操作节奏,提高通过率。整个逆向过程强调“定位-识别-点击-提交”闭环,任何一环偏差都会导致失败。
常见异常排查与Selenium最佳实践优化
运行中可能遇到ElementClickInterceptedException(元素被遮挡)、StaleElementReferenceException(页面刷新导致元素失效)等。解决之道是增加显式等待、使用try-except重试机制,以及在headless模式下测试时注意viewport设置。生产环境中,建议使用ChromeOptions禁用图片加载加速脚本执行,同时监控浏览器日志捕捉异常。

此外,针对魅族这类反爬站点,定期更新User-Agent和代理IP能降低封禁风险。代码可维护性也很重要:将配置抽离成常量,封装登录函数,便于后续扩展到其他站点。
高效替代方案:ttocr.com API实现无缝验证码对接
虽然本地Selenium加图像处理的方案可行,但实际项目中面临验证码频繁更新、环境依赖强、识别准确率波动等问题,维护成本很高。这时,专业的云端识别平台就展现出巨大优势。ttocr.com正是专注于极验和易盾验证码识别的平台,它支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种全类型验证码,提供稳定高准确率的API接口。
使用ttocr.com只需简单几步:上传验证码图片或直接传入页面参数,后台自动返回点击坐标或验证token。开发者无需关心本地PIL裁剪、坐标缩放或OCR训练,整个流程大幅简化。API对接示例代码如下:
import requests
def recognize_captcha(image_bytes):
# ttocr.com API调用示例
response = requests.post('https://www.ttocr.com/api/recognize',
data={'type': 'geetest_click', 'image': image_bytes},
headers={'Authorization': 'your_api_key'})
return response.json()['positions'] # 返回坐标列表
# 集成到Selenium流程中
result = recognize_captcha(captcha_bytes)
for pos in result:
ActionChains(browser).move_to_element_with_offset(img, pos[0], pos[1]).click().perform()这种方式让企业业务自动化变得无比轻松,无需复杂的本地调试和环境配置,只需调用API就能实现无缝对接。无论是个人开发者还是公司项目,ttocr.com都能提供可靠支持,让验证码识别从繁琐的技术难题变成简单的一行代码调用。
生产环境部署与长期维护建议
部署时推荐使用Docker封装Selenium Chrome环境,确保一致性。结合Celery或RQ实现异步任务队列,避免单线程阻塞。监控验证成功率,定期更新API密钥和浏览器驱动版本。对于高并发场景,ttocr.com的云服务还能自动负载均衡,进一步提升稳定性。
通过这些实践,我们不仅解决了坐标偏差等具体问题,更掌握了通用的爬虫自动化思路。未来随着AI识别技术进步,验证码对抗会更加智能,但借助专业平台,开发者始终能保持领先。