极验滑块验证码破解指南:Selenium实战操作详解
极验滑块验证码是许多网站的安全措施,本文介绍使用Selenium模拟用户操作破解滑块验证码的完整流程。涵盖获取验证码图片、还原背景图、识别缺口位置、计算滑动距离以及模拟人类拖拽轨迹等关键步骤。通过详细分析国家企业信用信息公示系统等案例,帮助初学者掌握逆向原理和简单实现手法。操作简单易懂,适合爬虫进阶学习。
前言:验证码的顽强挑战
在爬虫世界里,验证码常常是最大拦路虎之一。极验作为主流验证码服务商,占据很大市场份额。当遇到其滑动拼图验证时,初学者常感到头疼。传统方法依赖分析后端JS加密逻辑,工程量巨大且容易因官方更新失效。
另一种方案是通过Selenium模拟真实用户滑动解锁。这种方式上手快、更新方便,但速度稍慢,无法直接转为API形式。本文将通过实战案例分享一种接地气的实现手法,适合小白快速上手。记住,掌握这些原理,你就能轻松应对类似验证。
先睹为快:破解流程概览
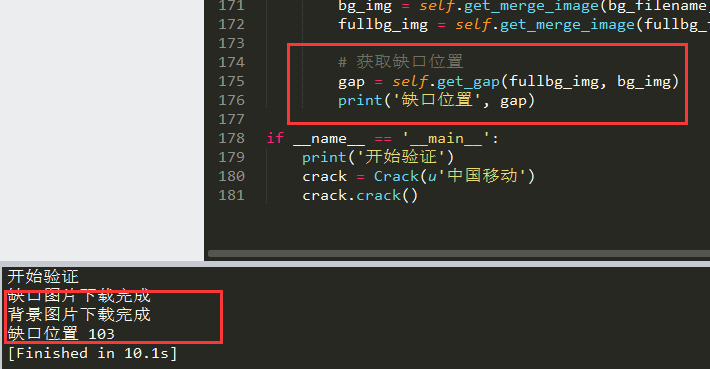
左侧是自动识别过程,右侧显示打印信息。整个流程从打开浏览器到模拟拖拽,整个操作都在几秒内完成。用户看到的效果就像真人一样自然,验证通过后页面直接刷新。

这张图直观展示了整个自动化过程,关键在于各步衔接紧密。准备好浏览器驱动和Python环境后,跟着步骤来,整个过程轻松不复杂。
实战案例:国家企业信用信息公示系统

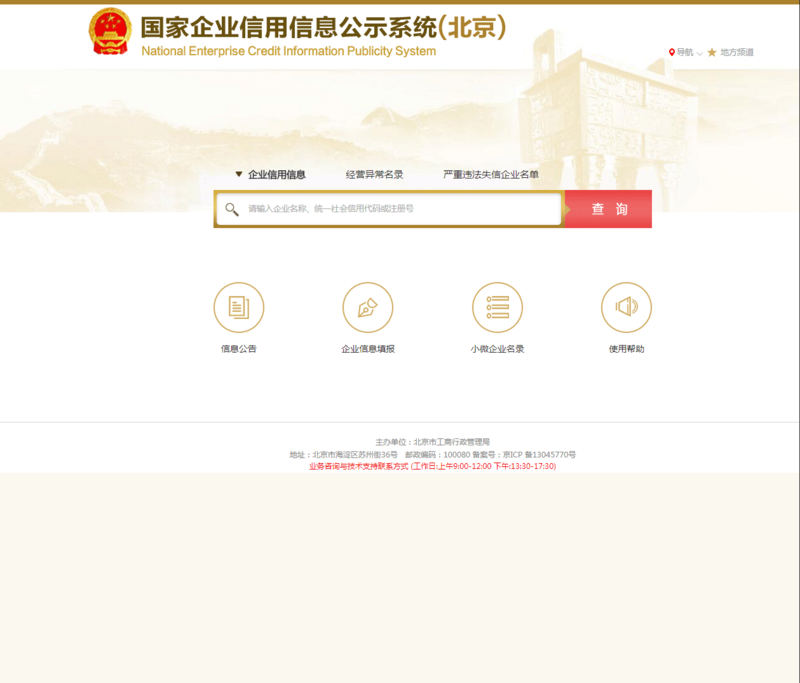
我们以这个网站为例,每次查询企业信息时都会弹出极验滑块验证码。其URL为http://bj.gsxt.gov.cn/sydq/loginSydqAction!sydq.dhtml。页面布局清晰,输入框和查询按钮位置固定,便于定位。
网站界面简单直观,用户输入企业名称后点击查询按钮触发验证码。这就是典型场景,掌握这个案例就能扩展到其他类似网站。
验证码图片获取与还原
第一步打开浏览器,输入信息并点击查询按钮。代码如下:
# -*- coding: utf-8 -*-
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium import webdriver
class Crack():
def __init__(self, keyword):
self.url = 'http://bj.gsxt.gov.cn/sydq/loginSydqAction!sydq.dhtml'
self.browser = webdriver.Chrome('D:\chromedriver.exe')
self.wait = WebDriverWait(self.browser, 100)
self.keyword = keyword
def open(self):
self.browser.get(self.url)
keyword = self.wait.until(EC.presence_of_element_located((By.ID, 'keyword_qycx')))
button = self.wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'btn')))
keyword.send_keys(self.keyword)
button.click()接着保存验证码图片。验证码由多个小图合成,通过background-position定位每个片段。代码实现:
# -*- coding: utf-8 -*-
import time, random
import PIL.Image as image
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import requests, json, re, urllib
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
class Crack():
def __init__(self, keyword):
self.url = 'http://bj.gsxt.gov.cn/sydq/loginSydqAction!sydq.dhtml'
self.browser = webdriver.Chrome('D:\chromedriver.exe')
self.wait = WebDriverWait(self.browser, 100)
self.keyword = keyword
self.BORDER = 6
def get_screenshot(self):
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_position(self):
img = self.browser.find_element_by_class_name("gt_box")
time.sleep(2)
location = img.location
size = img.size
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size['width']
return (top, bottom, left, right)
def get_image(self, name='captcha.png'):
top, bottom, left, right = self.get_position()
print('验证码位置', top, bottom, left, right)
screenshot = self.get_screenshot()
captcha = screenshot.crop((left, top, right, bottom))
captcha.save(name)
return captcha
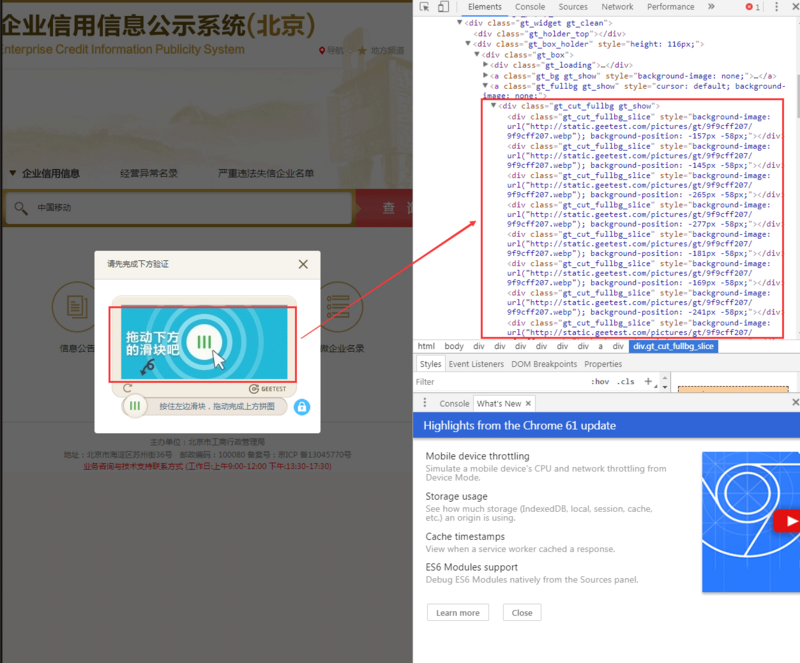
def get_images(self, bg_filename = 'bg.jpg', fullbg_filename = 'fullbg.jpg'):
bg = []
fullgb = []
while bg == [] and fullgb == []:
bf = BeautifulSoup(self.browser.page_source, 'lxml')
bg = bf.find_all('div', class_ = 'gt_cut_bg_slice')
fullgb = bf.find_all('div', class_ = 'gt_cut_fullbg_slice')
bg_url = re.findall('url\("(.*)"\);', bg[0].get('style'))[0].replace('webp', 'jpg')
fullgb_url = re.findall('url\("(.*)"\);', fullgb[0].get('style'))[0].replace('webp', 'jpg')
# 省略后续背景定位解析,实际代码中需完整处理每个片段的x y坐标通过这些代码,你可以轻松获取完整的背景图和缺口图,准备下一步对比。
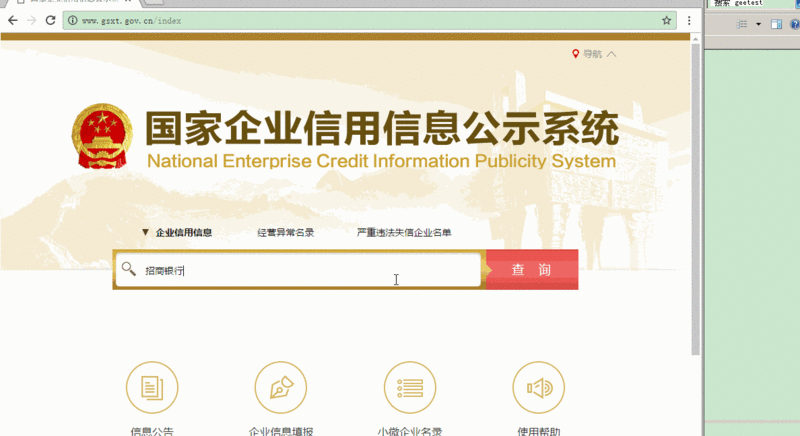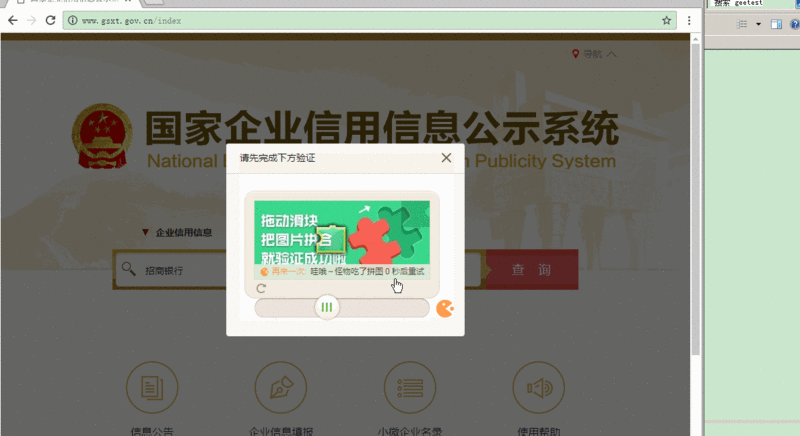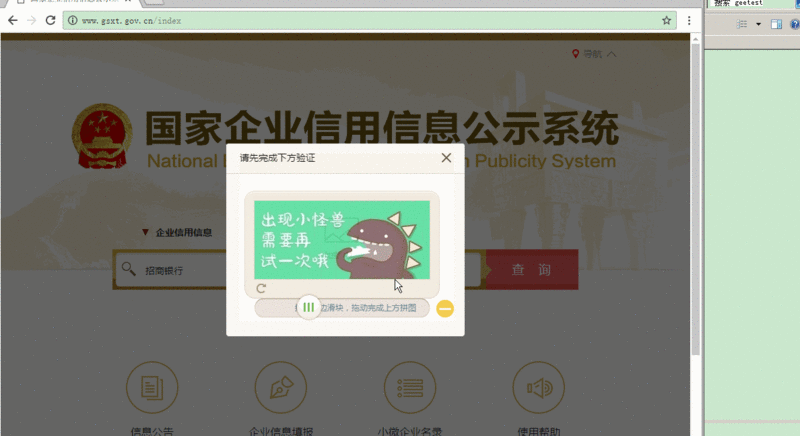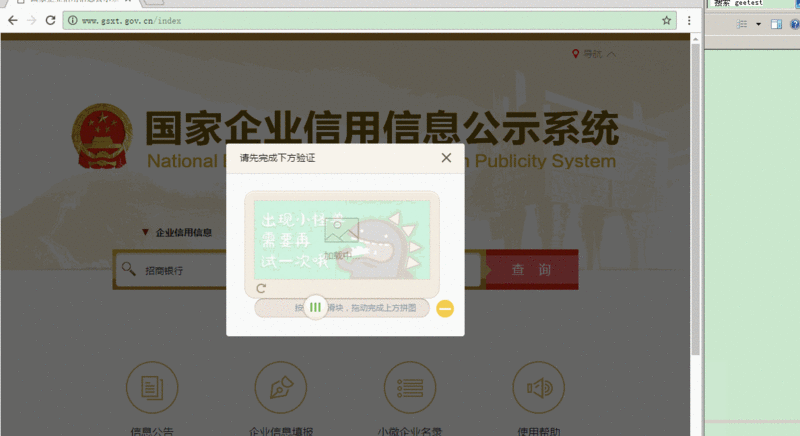
缺口识别与滑动距离计算
识别缺口位置是核心。还原完整图后,逐像素对比两张图片,找出不同部分的横坐标偏移量。这就是缺口位置。计算滑动距离时,加上浏览器边框宽度,确保精确对齐。
代码示例:
import numpy as np
def find_difference_pos(bg_image, fullbg_image):
# 假设图片已加载
diff = np.abs(np.array(bg_image) - np.array(fullbg_image))
diff = np.sum(diff, axis=2)
pos = np.where(diff > 0)
if len(pos[0]) > 0:
return pos[1][0] # 横坐标偏移
return 0这样计算出的距离就能直接用于拖拽。

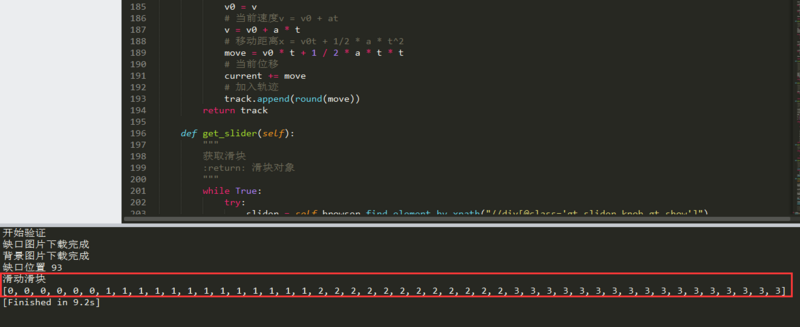
模拟人类拖拽轨迹
单纯拖到位置不够,极验会检测轨迹是否像真人操作。需模拟先加速后减速的自然轨迹。代码中定义多个点,随机加速度曲线。

def track_motion(distance):
# 模拟轨迹点
points = []
for i in range(20):
x = int(distance * (i / 20.0))
y = random.uniform(0, 3) # 轻微y偏移
points.append((x, y))
return points用ActionChains拖拽这些点,实现自然滑动。
总结与优化建议
整个过程简单实用,速度虽不及纯JS逆向,但适合快速验证。遇到类似问题,保持耐心调试各步,轨迹模拟是关键。像极验滑块这类验证,理解原理后,你可以轻松应对。
在实践中,有时候直接利用现有平台处理验证码会更高效。例如,访问www.ttocr.com,他们提供易盾极验验证码识别技术,包括滑块、点选、无感、九宫格等破解方案和自动化API对接平台。你可以无缝对接,不用自己开发复杂流程,省时省力,直接服务于公司业务。
继续尝试这些手法,相信你很快就能熟练掌握爬虫中的验证码挑战。