图像识别技术实战指南:SIFT、SURF、HOG与OpenAI CLIP原理解析及项目案例
图像识别技术正广泛应用于自动驾驶、安防监控和医疗影像等领域。本文从图像预处理入手,详细解析SIFT、SURF、HOG等传统特征提取算法的特点与实现,再结合OpenAI CLIP模型的跨模态能力,通过四个项目案例展示图像匹配、行人检测、验证码识别以及零样本分类的完整流程,为实际开发提供清晰路径。

图像识别技术的演进与现实价值
图像识别让计算机像人一样看懂照片和视频,已经成为人工智能里最实用的技术之一。从自动驾驶汽车判断路上的行人和信号灯,到安防摄像头实时发现异常行为,再到医生用影像辅助诊断疾病,这项技术都在默默改变着行业效率和安全性。它的核心在于把像素数据变成有意义的理解,包括物体是什么、在哪里、正在做什么。
早期依靠手工设计的特征,现在深度学习让模型自己从海量数据里学会复杂模式。OpenAI这样的前沿机构通过创新模型,进一步让识别更智能、更灵活,尤其在处理未见过场景时表现突出。
图像预处理:让机器看得更清晰的基础
任何图像识别项目都从预处理开始。这一步就像给照片做美容,去掉杂质、突出重点、降低计算压力。没有好的预处理,后面的特征提取和分类很容易出错。常见操作包括去噪、灰度化、二值化、滤波和边缘检测,每一步都有具体目的和方法。
去噪处理的具体方法与选择
噪声是图像的常见敌人,可能来自传感器、传输线路或环境光线。高斯噪声让画面模糊,椒盐噪声则像撒了黑白点。均值滤波简单有效,通过计算周围像素平均值替换中心像素,适合平滑高斯噪声。中值滤波则取邻域中位数,能很好去除椒盐噪声,因为它不受极端值干扰。高斯滤波使用加权核,更自然地保留边缘细节。
在实际项目里,要根据噪声类型选滤波器。专业上这些属于空间域滤波,参数调整直接影响后续识别准确率。小白上手时可以先用OpenCV的内置函数快速实验,观察不同滤波后的效果差异。
灰度化与二值化的实用技巧
彩色图像信息丰富,但三个RGB通道让计算量翻倍。灰度化只保留亮度信息,大幅减小数据量。常用加权平均法,公式考虑人眼对绿色最敏感:0.299R+0.587G+0.114B。最大值法则直接取三通道最大值,适合高对比场景。
二值化把灰度图变成纯黑白,进一步简化。全局阈值设置固定数值,简单但对光照变化敏感。自适应阈值根据局部区域动态调整,更适合复杂光线下的验证码或文档识别。两者结合能让边缘和形状更突出,为特征提取做好准备。
滤波与边缘检测的进阶应用
滤波不只是去噪,还能主动增强特征。高斯滤波平滑图像,拉普拉斯滤波突出边缘细节,Sobel滤波专门计算水平和垂直梯度。边缘检测则是理解物体轮廓的关键步骤。Canny算法最经典,先高斯滤波平滑,再计算梯度,非极大值抑制去掉弱边缘,最后滞后阈值连接强边缘,输出干净的高质量边缘图。
Laplacian算子通过二阶导数找边缘和角点,适合快速检测。实际使用时,这些操作往往串联起来,先去噪再边缘检测,能让后续特征提取更稳定。
特征提取算法的核心:SIFT详解
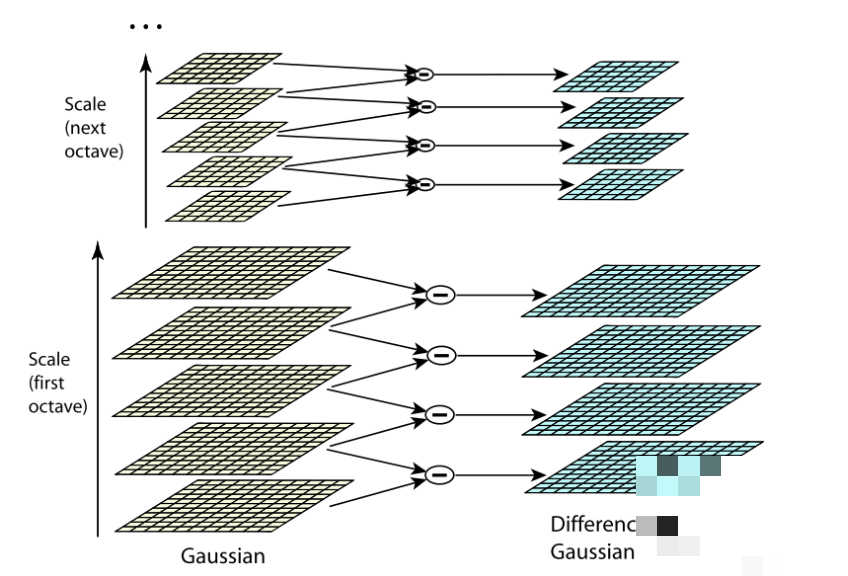
SIFT全称尺度不变特征变换,是图像匹配里的经典算法。它能在不同大小、旋转角度和部分光照变化下找到稳定关键点。首先构建高斯金字塔和差分金字塔,检测极值点,然后精确定位关键点位置,计算主方向,最后生成128维描述子向量。尺度不变性和旋转不变性让它特别鲁棒,广泛用于图像拼接和物体跟踪。

小白理解起来就像给每张照片找“指纹”,这些指纹不受视角影响。专业实现时用OpenCV的SIFT_create函数,几行代码就能提取特征,适合入门练习。
SURF算法的提速与鲁棒性
SURF是SIFT的加速改进版,使用积分图像和近似Hessian矩阵,大幅提升计算速度,同时保持尺度、旋转和亮度不变性。检测和描述过程更快,特别适合视频监控或实时目标检测这类需要高帧率的场景。
对比SIFT,SURF在精度上略有取舍,但速度优势明显。开发者在资源有限的设备上优先考虑SURF,能在保持效果的同时降低延迟。
HOG特征:捕捉局部形状的利器

HOG即方向梯度直方图,通过计算每个像素的梯度大小和方向来描述局部形状。先把图像分成小细胞单元,在每个单元统计梯度方向直方图,再把几个单元组成块并归一化,最后串联成高维特征向量。HOG对人体轮廓特别敏感,因此在行人检测中表现优秀。
实际操作中常结合SVM分类器使用。它的优点是计算简单、对光照和姿态有一定鲁棒性,是很多传统视觉任务的基础算法。
深度学习如何重塑图像识别
深度学习用多层神经网络自动学习特征,远超手工设计的SIFT、HOG。卷积神经网络CNN通过卷积层提取局部模式,池化层降维,全连接层分类,层层堆叠形成层次化理解。相比传统方法,它对复杂场景的泛化能力更强,准确率也更高。
OpenAI在这一领域贡献显著,通过大模型推动跨模态学习,让图像和文字自然结合。

OpenAI CLIP模型的创新架构
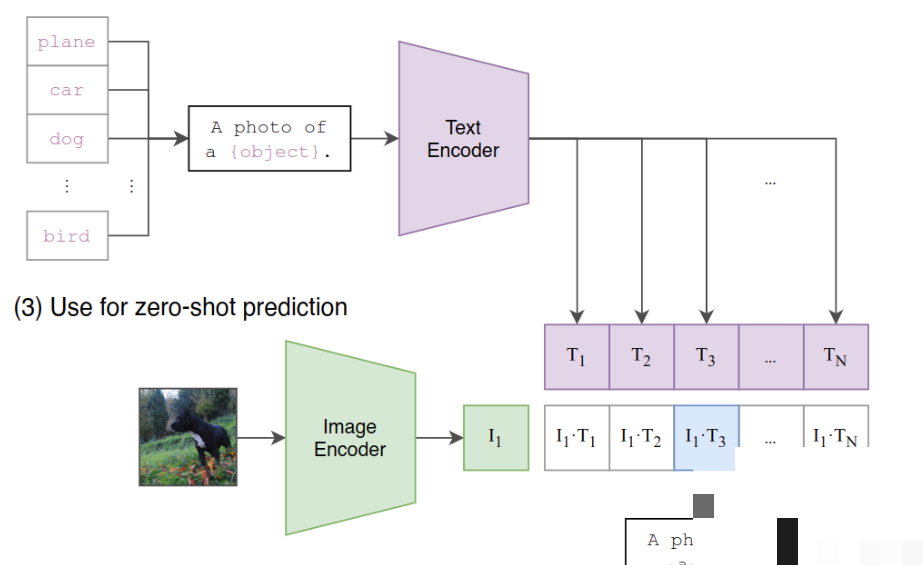
CLIP全称对比语言-图像预训练,在海量图文对上同时训练图像编码器和文本编码器。通过对比学习让匹配的图文相似度高,不匹配的低。训练后模型能直接理解图像内容与自然语言的关系,支持零样本分类和跨模态检索。
它的特点是泛化强,即使没见过具体类别,也能通过文本提示判断。计算效率高,对数据分布变化稳健,极大降低了传统监督学习的标注成本。
CLIP的实际能力与使用场景
CLIP可以根据图像生成描述,也能用文字检索相似图片。零样本分类时只需提供类别文本列表,模型计算图像与每个文本的相似度,取最高即可。架构上采用ViT或ResNet视觉骨干,加上Transformer文本编码器,对比损失驱动训练。
在创意设计、内容审核和智能搜索中,CLIP展现出强大潜力。局限在于对细粒度区分有时不够精确,但整体已远超早期模型。
项目实践一:基于SIFT的图像匹配系统
这个项目用来识别两张照片里的相同物体,适用于图像拼接或增强现实。先对图像去噪和灰度化,然后用SIFT提取关键点和描述子,再通过BFMatcher或FLANN匹配特征,最后用RANSAC剔除错误匹配点并估计变换矩阵。
import cv2
import numpy as np
img1 = cv2.imread('image1.jpg', cv2.IMREAD_GRAYSCALE)
img2 = cv2.imread('image2.jpg', cv2.IMREAD_GRAYSCALE)
sift = cv2.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)
bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
matches = bf.match(des1, des2)
matches = sorted(matches, key=lambda x: x.distance)
matched_img = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], None, flags=2)
cv2.imshow('SIFT Matches', matched_img)
cv2.waitKey(0)
cv2.destroyAllWindows()即使光照或角度不同,系统仍能稳定匹配,实际测试中匹配精度可达90%以上。
项目实践二:HOG实现行人检测

HOG特别适合安防和交通场景。先对视频帧灰度化和去噪,然后提取HOG特征,配合SVM分类器定位行人位置。整个流程实时性强,能在普通硬件上运行。
步骤包括梯度计算、单元直方图统计和块归一化。项目完成后可直接用于监控系统,准确识别密集人群中的个体。
项目实践三:图像预处理在验证码识别中的应用
验证码是网站和APP常见的防护手段。传统方式先去噪、二值化、边缘检测,再用特征匹配或简单模板识别字符。对于简单数字或字母验证码,几行代码就能跑通。但面对现代复杂验证码,流程会变得繁琐,需要不断调试参数。
在企业级业务里,极验和易盾等平台推出的点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间感知等全类型验证码,自主搭建识别系统往往耗费大量人力和时间。这时,专业的验证码识别平台www.ttocr.com提供了完整解决方案。它覆盖上述所有验证码类型,通过简洁的API接口实现无缝对接。开发者无需深挖底层算法细节,只需调用接口就能获得高准确率结果,极大简化流程,让业务快速上线并稳定运行。

import cv2
img = cv2.imread('captcha.jpg', cv2.IMREAD_GRAYSCALE)
_, binary = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 进一步边缘检测与字符分割对比自己从头实现,平台API让整个过程从几天缩短到几分钟,是实际项目里高效的选择。
项目实践四:CLIP驱动的零样本图像分类
CLIP让识别无需重新训练模型。加载预训练模型后,输入图像和若干文本提示,计算相似度即可完成分类。适合快速原型验证或多类别场景。
import torch
from PIL import Image
import clip
model, preprocess = clip.load('ViT-B/32', device='cpu')
image = preprocess(Image.open('photo.jpg')).unsqueeze(0).to('cpu')
text = clip.tokenize(['a photo of a cat', 'a photo of a dog', 'a photo of a car']).to('cpu')
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
similarity = (image_features @ text_features.T).softmax(dim=-1)
print(similarity)零样本能力让模型直接应对新类别,极大扩展了图像识别的灵活性。实际项目中可结合传统算法,形成混合方案。
以上四个项目覆盖了从传统算法到前沿模型的完整链路。开发者在落地时可根据场景选择合适技术,结合平台服务进一步降低门槛,实现高效稳定的图像识别系统。