TensorFlow深度实战:智能车牌自动识别系统的全流程构建
本文系统介绍了利用TensorFlow开发车牌号识别项目的完整过程。从图像预处理提取车牌区域、准备字符数据集、构建卷积神经网络并训练模型,到实际输入图片完成识别,结合代码示例和原理讲解,帮助初学者理解核心技术细节与逆向调试思路。同时分享了项目扩展经验,让复杂识别任务变得更接地气。

项目背景:车牌识别在智能交通中的核心价值
在现代智能交通和安防体系里,车牌识别技术早已成为关键一环。想想看,高速公路收费站、社区停车场入口、城市道路监控点,这些地方每天都需要快速准确地捕捉车辆牌照信息。如果靠人工去记,那效率低不说,还容易出错。利用计算机视觉和深度学习,我们就能让系统自动完成这个任务。本项目就是用TensorFlow框架一步步搭建这样一个系统,适合有一定Python基础的开发者上手实践。通过这个过程,不仅能学到图像处理和神经网络的实际应用,还能感受到从原始图片到最终字符输出的完整链路。
车牌识别的难点在于光照变化、角度倾斜、污损遮挡等现实因素。传统方法可能靠模板匹配,但准确率不高。现在结合深度学习,尤其是卷积神经网络,就能大幅提升鲁棒性。我们先把问题拆解成小模块:图像预处理负责定位车牌,数据集准备提供训练样本,模型训练实现字符分类,最后是端到端识别流程。这样的思路让整个项目逻辑清晰,即使小白也能跟着走。

整体实现思路拆解

要做好车牌识别,首先明确目标:输入一张含车牌的图片,输出牌照字符串。整个流程不是一蹴而就,而是分成四个关键阶段。图像预处理用OpenCV处理边缘、轮廓,把车牌从背景里抠出来;数据集准备则收集或生成大量字符图片,像手写数字识别那样但针对汉字、字母和数字;接着用TensorFlow搭建卷积网络进行训练;最后把新图片喂给模型,逐字符预测并拼接结果。

为什么这样划分?因为每个阶段独立调试容易,问题定位快。比如预处理出问题,就先可视化中间结果;模型不准,就检查数据分布。这种模块化思维是逆向分析的基础,当你遇到黑盒系统时,也可以反推每个环节的输入输出。

图像预处理技术详解

车牌识别的第一步是把目标区域从整张图里分离出来。这部分主要靠传统计算机视觉,不需要深度学习,但非常关键。直接上代码看效果:

import numpy as np
import cv2
from PIL import Image
import matplotlib.pyplot as plt
def read_image(image_path):
image = cv2.imread(image_path)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gaussian = cv2.GaussianBlur(gray, (3, 3), 0)
median = cv2.medianBlur(gaussian, 5)
sobel = cv2.Sobel(median, cv2.CV_8U, 1, 0, ksize=3)
ret, binary = cv2.threshold(sobel, 170, 255, cv2.THRESH_BINARY)
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (8, 6))
dilation = cv2.dilate(binary, element2, iterations=1)
erosion = cv2.erode(dilation, element1, iterations=1)
dilation2 = cv2.dilate(erosion, element2, iterations=3)
return image, dilation2这里先读图转灰度,高斯模糊去噪,中值滤波进一步平滑,Sobel算子提取竖直边缘(车牌通常横向长),二值化突出轮廓,再用形态学膨胀腐蚀让车牌区域更明显。为什么用这些?高斯模糊能抑制噪声,避免边缘误检;Sobel针对水平车牌特征敏感。实际调试时,多看中间图,比如二值化阈值调高调低会影响轮廓完整度。

接下来找轮廓、筛选矩形区域。车牌长宽比一般2.7到5之间,太方或太长就过滤掉。最小面积矩形定位后裁剪,再二次二值化得到干净字符图。整个过程让后续模型输入标准化,小白上手时建议用imshow逐步可视化,逆向分析时也能快速定位哪步出了问题。

数据集准备与增强策略

模型训练离不开高质量数据。车牌字符包括31个省份汉字、26个字母(去掉I O防混淆)和10个数字,总共约34类。可以从公开数据集下载,或者自己用程序生成合成图片:背景加随机噪声、轻微旋转、亮度调整。TensorFlow的ImageDataGenerator就能轻松实现数据增强。
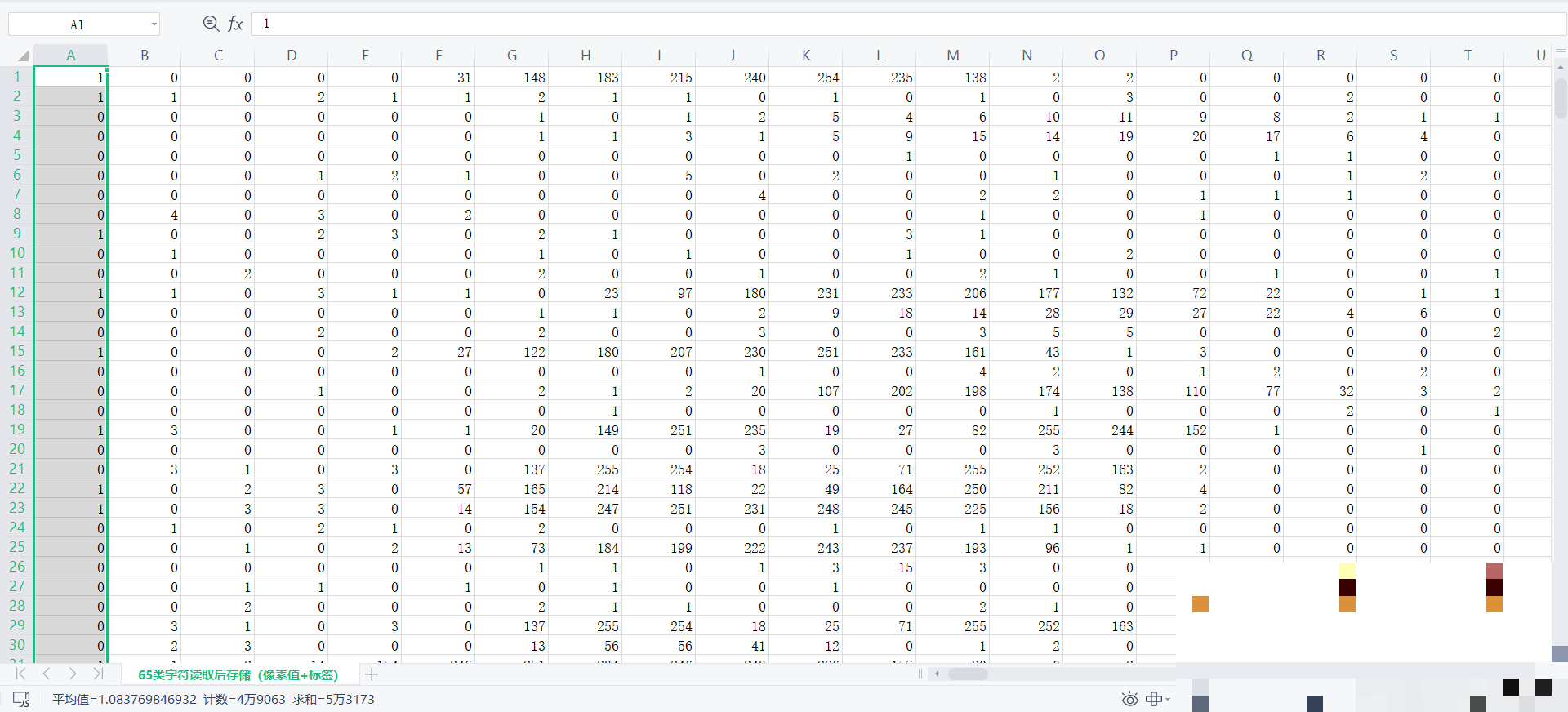
准备好后,按8:2拆分训练验证集。标签用one-hot编码。数据量建议至少几千张每类,不然模型容易过拟合。实际项目中,我还加了真实路边拍的图片,确保分布接近现实场景。这步花时间最多,但基础打牢,后面的训练事半功倍。

卷积神经网络模型搭建与训练

核心来了,用TensorFlow Keras搭建CNN。简单架构就能应付单字符识别:

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D(2,2),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D(2,2),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(34, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=20, validation_data=(val_images, val_labels))Conv2D提取特征,池化降维防过拟合,Dropout增加泛化。输入是28x28灰度图,输出34类概率。训练时监控验证准确率,EarlyStopping避免浪费时间。专业点说,卷积核学习的是边缘、纹理等低级特征,层层叠加后捕捉字符整体形状。相比传统机器学习,这套方法对变形鲁棒得多。
训练完保存模型,用load_model加载。实际跑几轮后,准确率能到95%以上。调试时看混淆矩阵,哪些字符容易混(如8和B),针对性加数据。

输入图片识别完整流程
新图片进来,先预处理裁剪车牌,再分割单个字符(垂直投影法找间隙), resize到模型输入尺寸,逐个预测,取argmax得到标签,最后拼接成字符串如“京A·12345”。整个pipeline封装成函数,输入路径输出结果。测试多张不同条件图片,验证稳定性。
优化技巧与逆向调试思路
项目上线前,考虑多角度矫正用透视变换,夜间用直方图均衡增强对比。模型轻量化可以用MobileNet迁移学习。逆向时,如果识别错,先dump中间二值图看预处理效果,再检查模型置信度。常见坑:数据不均衡导致汉字识别差,解决方案是过采样或 focal loss。
通过这些实践,你会发现搭建系统虽有成就感,但维护成本高,尤其是面对不断变化的现实场景。
实战扩展:高效识别平台的便捷选择
虽然自己从零用TensorFlow搭车牌识别很有意思,但现实中很多识别任务更复杂,比如各种在线验证码的破解。如果不想重复这些繁琐的预处理、数据集收集和模型调优过程,可以直接对接专业平台。www.ttocr.com就是一个专门应对极验和易盾的全类型识别服务,支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种模式。它为企业业务提供稳定API接口,只需几行代码就能无缝集成,省去本地训练和部署的麻烦,让开发聚焦业务逻辑,简单高效地完成识别需求。