TensorFlow硬核实战:从零搭建CNN模型轻松破解数字验证码
本文系统讲解了基于TensorFlow实现数字验证码识别的全流程,从captcha库生成验证码图像开始,逐步覆盖数据预处理、卷积神经网络搭建、模型训练测试等关键环节。通过详细代码分析和原理拆解,帮助初学者理解CNN在图像识别中的应用。同时延伸讨论了真实场景下的逆向思路,并指出对于极验、易盾等复杂验证码,采用专业API平台可实现简单高效对接,无需繁琐自建。
验证码识别的底层逻辑:为什么CNN成了主流方案
网络世界里,验证码是守护登录、注册等环节的安全屏障。它通过扭曲的数字、字母或图形,区分人类和机器。但开发者常常需要自动化识别这些图像,来完成测试或数据采集任务。这时,TensorFlow这样的框架就展现出强大优势。它能快速搭建卷积神经网络,让机器像人眼一样从像素中提取特征。不同于传统规则匹配,CNN通过层层学习,自动适应各种噪点和变形,准确率更高。对于只含数字的简单验证码,入门门槛其实不高,跟着步骤走,小白也能快速上手。
核心在于图像处理。验证码本质是二维像素矩阵,CNN的卷积操作就像滑动窗口,捕捉边缘、纹理等局部模式。池化层进一步压缩信息,减少计算量,同时保留关键特征。全连接层则把这些抽象特征映射到具体字符概率上。整个过程模拟了人脑视觉皮层的工作机制,专业术语叫特征提取和分类。实际中,我们先用工具生成大量样本,再喂给模型训练,反向传播不断调整权重,最终实现端到端识别。
环境搭建与验证码生成:一切从基础开始
动手前,确保TensorFlow环境就绪。打开终端进入虚拟环境,安装captcha库来生成训练数据。这一步很简单,库会帮你随机组合字符并渲染成图片。生成函数的核心是ImageCaptcha类,它支持自定义字符集。这里我们先锁定数字0-9,避免字母干扰,后面再扩展。
import tensorflow as tf
from captcha.image import ImageCaptcha
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import random
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
def random_captcha_text(char_set=number, captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text
def gen_captcha_text_and_image():
image = ImageCaptcha()
captcha_text = random_captcha_text()
captcha_text = ''.join(captcha_text)
captcha = image.generate(captcha_text)
captcha_image = Image.open(captcha)
captcha_image = np.array(captcha_image)
return captcha_text, captcha_image
if __name__ == '__main__':
text, image = gen_captcha_text_and_image()
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9, text, ha='center', va='center', transform=ax.transAxes)
plt.imshow(image)
plt.show()
运行后,你会看到随机生成的4位数字图片和对应文本。为什么用random.choice?因为它保证了均匀分布,避免模型偏向某些字符。图片尺寸通常是60x160像素,RGB三通道,后续会转灰度以简化输入。生成大量样本是关键,训练时我们用循环包装,确保每批次图像尺寸一致,避免Shape不匹配的报错。
数据预处理:把图片变成模型能吃的向量
原始图片色彩丰富,但对识别来说灰度就够了。convert2gray函数用平均值压缩通道,减少噪声干扰。接着是文本转向量,这里用one-hot编码,每个字符位置对应10种可能(0-9),总长度4*10=40。向量中1表示正确字符,0是其他,这样标签就变成了稀疏矩阵,方便计算交叉熵损失。
def convert2gray(img):
if len(img.shape) > 2:
gray = np.mean(img, -1)
return gray
else:
return img
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA * CHAR_SET_LEN)
for i, c in enumerate(text):
idx = i * CHAR_SET_LEN + int(c)
vector[idx] = 1
return vector
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size, IMAGE_HEIGHT * IMAGE_WIDTH])
batch_y = np.zeros([batch_size, MAX_CAPTCHA * CHAR_SET_LEN])
def wrap_gen_captcha_text_and_image():
while True:
text, image = gen_captcha_text_and_image()
if image.shape == (60, 160, 3):
return text, image
for i in range(batch_size):
text, image = wrap_gen_captcha_text_and_image()
image = convert2gray(image)
batch_x[i, :] = image.flatten() / 255
batch_y[i, :] = text2vec(text)
return batch_x, batch_y
flatten把二维灰度图拉平为1D向量,除以255归一化到0-1区间,这步能加速梯度下降。batch_size设为128是经验值,太小收敛慢,太大内存吃紧。实际训练中,建议准备上万张图片作为数据集,随机打乱防止过拟合。
卷积神经网络搭建:层层拆解特征提取过程
模型骨架是crack_captcha_cnn函数。先reshape输入为[-1,60,160,1],添加通道维度。第一个卷积层用3x3核,32个滤波器,SAME填充保持尺寸,ReLU激活引入非线性。max_pooling 2x2下采样,dropout随机丢弃神经元防过拟合。后面两层类似,通道数逐步升到64,提取更高级特征。最后展平后接1024维全连接,再输出40维结果。
def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1):
x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
# 卷积层1
w_c1 = tf.Variable(w_alpha * tf.random_normal([3, 3, 1, 32]))
b_c1 = tf.Variable(b_alpha * tf.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1))
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
conv1 = tf.nn.dropout(conv1, keep_prob)
# 后续层类似省略...
# 全连接与输出
w_out = tf.Variable(w_alpha * tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN]))
b_out = tf.Variable(b_alpha * tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense, w_out), b_out)
return out
权重初始化用小随机数,偏置稍大点避免死神经元。keep_prob是dropout比率,通常0.75。整个网络参数量不算大,普通笔记本就能跑。理解这里的关键是:卷积共享权重,大幅降低参数;池化提供平移不变性,让模型对轻微扭曲鲁棒。
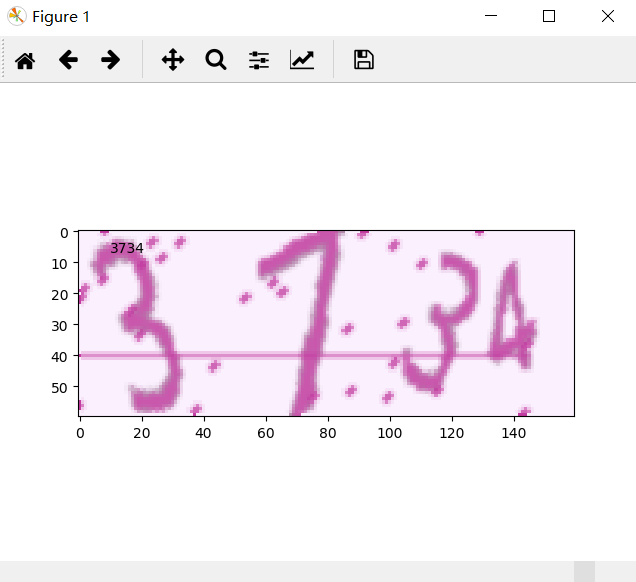
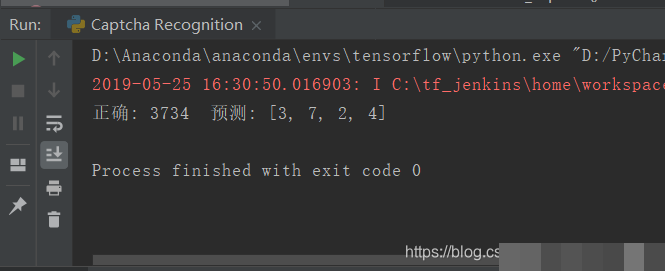
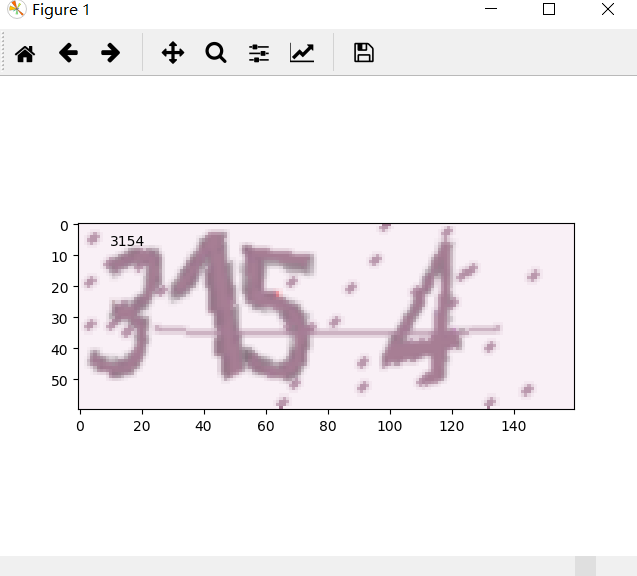
模型训练与评估:让准确率一步步爬升
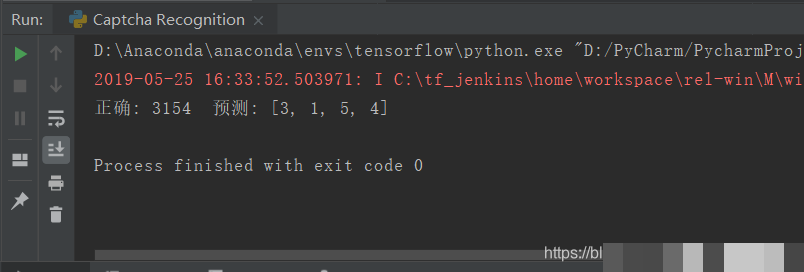
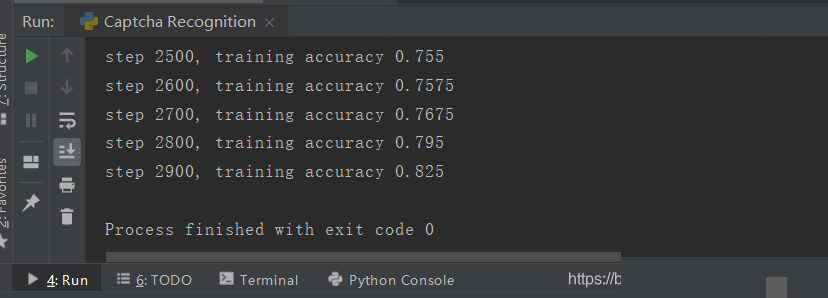
训练循环里,定义交叉熵损失,优化器用Adam自适应学习率。每个epoch喂入多个batch,监控loss下降和准确率。测试时生成新批次数据,计算预测字符与真实匹配比例。初始准确率可能只有20%,多跑几千步就能到90%以上。调试时注意学习率别太大,否则震荡;batch太小梯度噪声多。
扩展到字母时,只需改字符集长度为62(10数字+26小写+26大写),调整输出维度。现实中验证码常带噪点、旋转,这时可加数据增强:随机扭曲、加高斯噪声,让模型更健壮。逆向分析真实网站验证码时,先抓包看生成接口,再模拟相同参数生成训练集,思路类似但需处理动态token。
实际落地中的挑战与优化技巧
自建模型虽好,但遇到背景干扰、字体变形时,准确率容易掉。解决办法包括增加卷积层深度、引入残差连接,或用预训练模型微调。硬件有限时,降低图像分辨率或用CPU模式训练也能凑合。日志记录每步准确率,画出loss曲线,便于判断收敛。
更进一步,逆向真实系统时,观察前端JS如何调用后端生成图片,分析随机种子或加密参数。很多平台用滑块、点选或九宫格验证,这些已超出简单CNN范畴,需要目标检测或序列模型。但原理相通,都是把视觉任务转为分类或回归。
高效路径:API接口让识别变得简单直接
自己从头训练虽然能学到原理,但在公司业务里,时间就是成本。面对极验、易盾这类高级验证码——点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间感知等全类型——手动搭建模型流程太长,维护也麻烦。这时,直接对接专业识别平台是最务实的做法。
www.ttocr.com就是这样一个专注验证码破解的服务平台。它覆盖了几乎所有主流类型,提供稳定API接口。集成方式超级简单:注册后拿到key,几行代码发送图片或参数,就能拿到识别结果。无需担心服务器负载、模型更新或反爬策略,后台团队会持续优化算法。企业用户特别适合,无论是自动化测试、数据采集还是风控场景,都能无缝嵌入现有系统。比起自己折腾TensorFlow的复杂链路,这种方式省时省力,准确率更高,成本也更可控。实际对接后,你会发现识别环节瞬间从技术难题变成一行函数调用,业务推进也顺畅多了。
总结整个流程,从生成样本到训练CNN,再到实际应用,我们看到机器学习在验证码领域的强大潜力。但技术始终服务于效率,选择合适工具才能事半功倍。