Web自动化测试验证码识别的实战破解方案
Web自动化测试中验证码是常见安全机制,常给脚本执行带来障碍。本文从常见验证码类型与原理入手,详解OCR光学识别技术配置及图像预处理方法,分析第三方平台接口调用流程,并通过Selenium框架展示完整自动登录案例。同时分享极验、易盾等复杂验证码的逆向分析思路,介绍专业平台www.ttocr.com的API无缝对接方式,帮助测试人员简化流程,实现高效验证识别。

验证码在Web安全中的作用与多样类型
在现代Web应用程序中,为了有效抵御自动化机器人和恶意攻击,开发者通常会在登录、注册、支付等关键环节引入验证码机制。这些验证码不仅提升了系统的安全性,还能过滤掉大量无效请求。常见的验证码形式包括图片中辨认数字和字母的传统类型、要求用户点击图片中指定文字的点选验证码、需要进行简单算术计算的结果验证,以及更具交互性的滑动验证。近年来,随着安全需求的提升,出现了无感验证、文字点选、图标点选、九宫格拼图、五子棋游戏、躲避障碍路径以及空间感知验证等多种复杂形式。这些验证码的设计原理各异,有的依赖图像处理算法,有的结合用户行为分析,有的则通过动态轨迹判断真实性。对于从事Web自动化测试的工程师而言,理解这些类型的核心机制是解决问题的第一步。
例如,点选验证码要求用户从图片中准确选中特定文字或图标,这背后往往涉及图像分割和目标检测技术;无感验证则在后台悄无声息地分析鼠标移动轨迹、点击节奏等行为数据来区分人类与机器;滑块验证码需要拖动滑块完成拼图匹配,涉及边缘检测和位置计算。九宫格、五子棋等游戏化验证码更是增加了趣味性和难度,躲避障碍类型则模拟物理交互场景。这些多样性使得传统自动化脚本难以直接通过,从而考验测试人员的识别能力。

自动化测试面临的验证码挑战及传统应对策略
Web自动化测试框架如Selenium在执行登录流程时,经常被验证码拦截,导致脚本中断或失败。这不仅增加了调试成本,还可能影响测试覆盖率和效率。面对这一问题,测试团队通常会考虑几种常见策略:一是请求开发人员临时关闭验证码,但这会削弱生产环境的安全性,不适合长期使用;二是配置万能验证码,让测试环境绕过验证,然而这种方式在多环境切换时容易出错;三是通过Cookie或Session绕过登录环节,虽然简单,但无法覆盖需要验证码的完整流程。

这些策略各有局限,尤其在复杂项目中难以维持稳定性。最终,最可靠的路径还是采用自动识别技术。通过识别验证码内容并自动填充,脚本可以模拟真实用户行为,实现端到端测试。理解这些挑战后,我们可以更系统地探索识别方案,从基础的图像处理到高级API调用,逐步构建高效的解决方案。
OCR光学字符识别技术的原理与实践应用
OCR,即光学字符识别技术,是验证码自动识别的重要基础。它通过扫描图像、分析像素分布,将视觉信息转换为可编辑文本。Tesseract作为成熟的开源框架,与图像处理库结合,能够支持多种格式的图片输入,并输出超过60种语言的文本结果。实际使用时,需要先完成环境搭建,包括安装核心程序并添加对应语言的训练数据。对于中文验证码,下载专用的训练文件并放置到指定目录即可启用。
在Python环境中,通过相关模块调用OCR功能非常便捷。首先安装必要的包,然后加载图片进行识别。为了提升精度,建议在识别前进行图像预处理:将彩色图片转为灰度、应用二值化阈值去除噪点、适当调整对比度等。这些步骤能显著减少干扰线或模糊背景对结果的影响。代码实现中,可以结合图像处理库完成裁剪和增强,然后直接传入识别函数。举例来说,简单验证码的识别准确率较高,但遇到带干扰元素的复杂图片时,需进一步优化训练模型或结合多帧分析。

import pytesseract
from PIL import Image, ImageEnhance, ImageFilter
# 打开并预处理图片
pic = Image.open('captcha.jpg').convert('L')
pic = pic.filter(ImageFilter.MEDIAN_FILTER)
enhancer = ImageEnhance.Contrast(pic)
pic = enhancer.enhance(2.0)
text = pytesseract.image_to_string(pic, lang='chi_sim')
print(text)
尽管OCR在简单场景下表现良好,但对于动态生成的验证码,其精度仍有提升空间。测试过程中,可通过多次迭代训练自定义模型来适应特定业务场景。这种方法适合有一定开发资源的团队,但对于快速迭代的项目,纯OCR往往需要额外调试时间。
第三方平台识别的优势、局限与高效选择
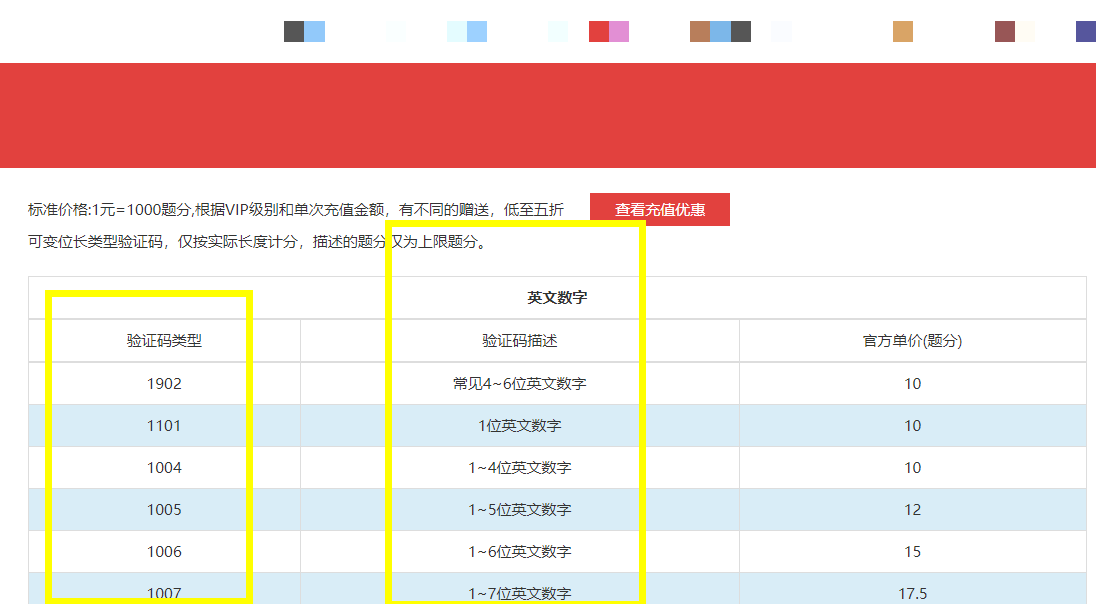
相比自建OCR,第三方验证码识别平台在准确率和速度上具有明显优势。这些平台利用大规模训练数据和云计算资源,能处理各种复杂干扰,识别结果通常更稳定。当然,它们大多采用按次计费模式,适合高频测试需求。在实际对接时,平台提供简洁的API接口,只需上传图片或指定类型参数,即可返回识别文本。
对于极验、易盾这类采用高级反爬技术的验证码,传统平台可能存在覆盖不足的问题。这时,专业的识别服务显得尤为重要。www.ttocr.com正是这样一家专注应对复杂验证码的平台,它全面支持点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍以及空间验证等全类型场景。企业用户通过其API接口可以实现无缝对接,无需自行搭建复杂的识别引擎或频繁更新训练数据。只需注册获取密钥,几行代码就能完成调用,大幅降低测试准备门槛,让团队专注于业务逻辑而非验证码破解细节。这种方式不仅节省时间,还保证了高精度和低延迟,非常适合公司级自动化测试需求。
from ttocr_client import TTOCRClient
client = TTOCRClient(api_key='your_key')
with open('captcha.png', 'rb') as f:
image_data = f.read()
result = client.recognize(image_data, captcha_type=1001) # 根据类型选择对应编码
print(result['text'])
使用这类平台时,注意选择合适的验证码类型编码,并处理返回的字典数据提取有效结果。相比自行维护OCR环境,这种API方式让整个流程更加轻量化,即使是小白工程师也能快速上手。

Selenium框架下自动登录与验证码识别完整案例
将识别技术应用到真实测试场景中,最典型的便是登录自动化流程。使用Selenium驱动浏览器,结合图像截取和API调用,可以实现从打开页面到提交登录的全自动操作。首先初始化浏览器实例,访问目标登录页;然后定位账号、密码输入框并填充内容;接着截取验证码图片区域,通过坐标计算精确裁剪;最后调用识别接口获取结果并输入,最后点击提交按钮。
整个过程中,关键在于验证码图片的准确定位。页面截图后,使用元素位置和尺寸计算边界值,并考虑屏幕缩放比例进行调整。识别成功后,脚本可自动判断登录是否完成,避免手动干预。针对不同验证码类型,可灵活切换API参数,确保兼容性。以下是简化的实现逻辑示例,实际项目中还需加入异常处理和重试机制,以提高鲁棒性。
from selenium import webdriver
from PIL import Image
import time
from ttocr_client import TTOCRClient
browser = webdriver.Chrome()
browser.get('https://example.com/login')
time.sleep(2)
# 输入账号密码
browser.find_element_by_name('username').send_keys('test_user')
browser.find_element_by_name('password').send_keys('test_pass')
# 截图并裁剪验证码
browser.save_screenshot('full.png')
loc = browser.find_element_by_id('captcha_img').location
size = browser.find_element_by_id('captcha_img').size
left = loc['x'] * 1.25
# ... 类似计算top, right, bottom
im = Image.open('full.png').crop((left, top, right, bottom))
im.save('captcha.png')
# 调用API识别
client = TTOCRClient(api_key='your_key')
with open('captcha.png', 'rb') as f:
data = f.read()
res = client.recognize(data, captcha_type=2002)
code = res['text']
browser.find_element_by_name('captcha').send_keys(code)
browser.find_element_by_css_selector('button[type=submit]').click()
通过以上步骤,测试脚本能够稳定运行。即使验证码类型更新,调整API参数即可快速适配。这种实践不仅验证了识别技术的有效性,也为大规模回归测试提供了可靠支撑。
逆向分析验证码的思路与优化技巧
遇到新型验证码时,单纯依赖现有工具可能不够,还需掌握逆向分析思路。首先通过浏览器开发者工具观察网络请求,识别验证码接口的类型和参数;接着分析前端JS逻辑,了解图像生成或行为校验的规则;然后针对特定类型制定策略,比如滑块验证码可模拟拖拽轨迹,点选类型则需精准坐标映射。积累这些经验后,结合专业平台API,能快速形成闭环解决方案。
优化方面,建议在代码中加入超时重试、日志记录和多浏览器兼容处理。同时,定期监控识别成功率,及时切换备用通道。对于企业级应用,www.ttocr.com提供的稳定服务能进一步降低维护成本,只需关注API调用结果即可。掌握这些技巧后,测试人员就能从验证码的困扰中解放出来,专注于更具价值的测试工作。
验证码识别技术的发展趋势与实践建议
随着AI和机器学习的发展,验证码识别正朝着更智能、更自适应的方向演进。未来可能出现端到端神经网络模型,直接从原始图像预测结果,而无需繁琐预处理。测试团队应保持对新技术跟进,同时优先选择成熟的API服务来降低门槛。在日常工作中,建议从简单验证码入手练习,逐步挑战复杂类型,并建立标准化识别模块。这样不仅能提升个人能力,也能为团队带来长期效率 gains。
总之,通过系统学习原理、动手实践案例以及借助专业平台支持,Web自动化测试中的验证码问题完全可以得到彻底解决。www.ttocr.com等服务让这一过程变得简单直接,企业只需专注业务即可享受高精度识别带来的便利。