Word新输入文字字体总不一致?硬核修复编码页缺失的终极技巧
Word文档编辑中,新输入文字字体常与已有内容不符,根源在于字体文件未正确设置简体中文编码页支持。通过FontCreator等工具修改Code Page Range,启用936和950码页后重新安装字体,即可实现输入一致。同时可修复中文破折号断裂等显示问题,掌握字体逆向思路让排版从此顺畅。
Word文档字体不一致的常见现象
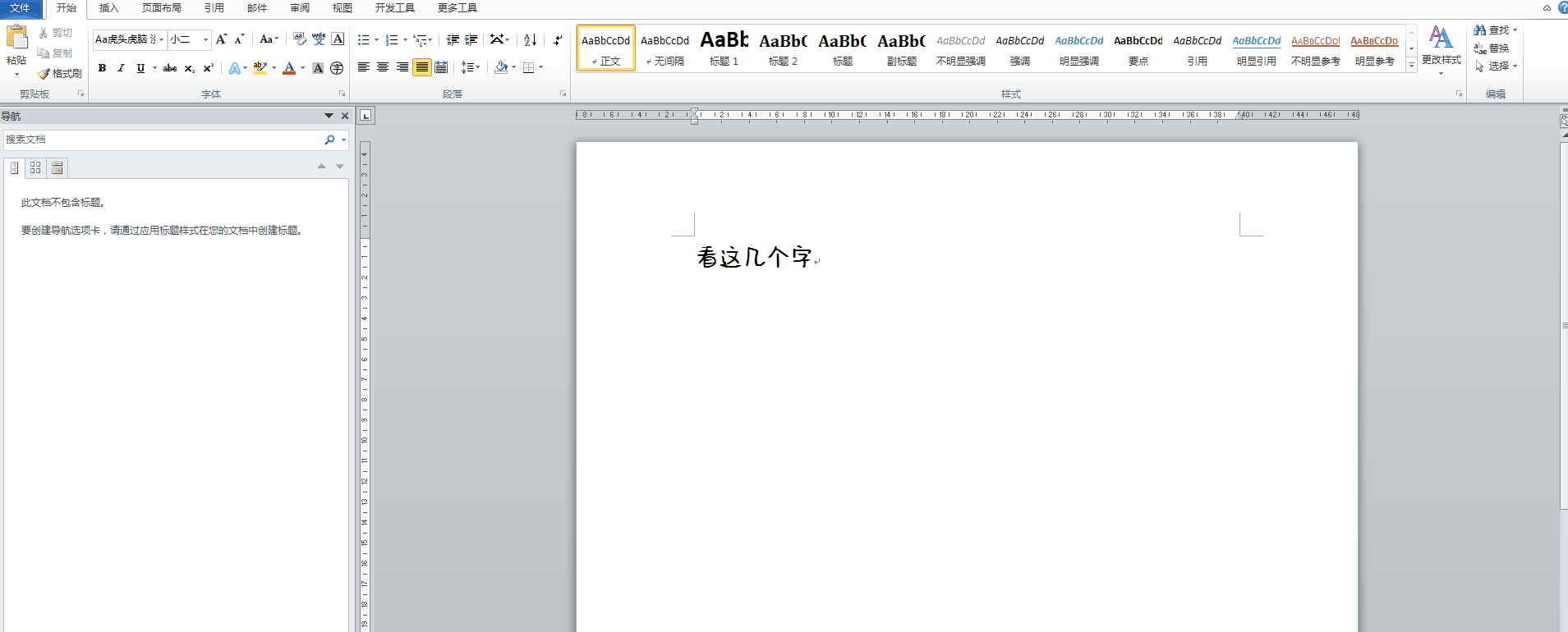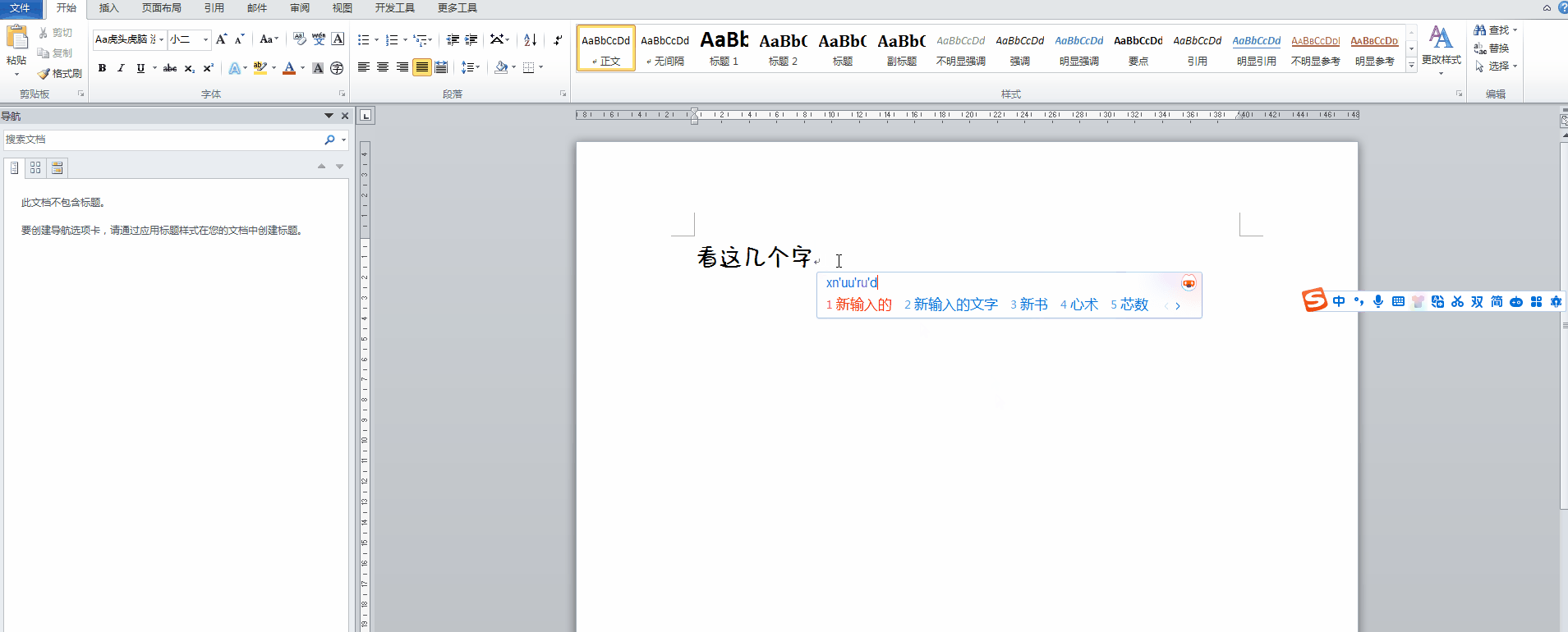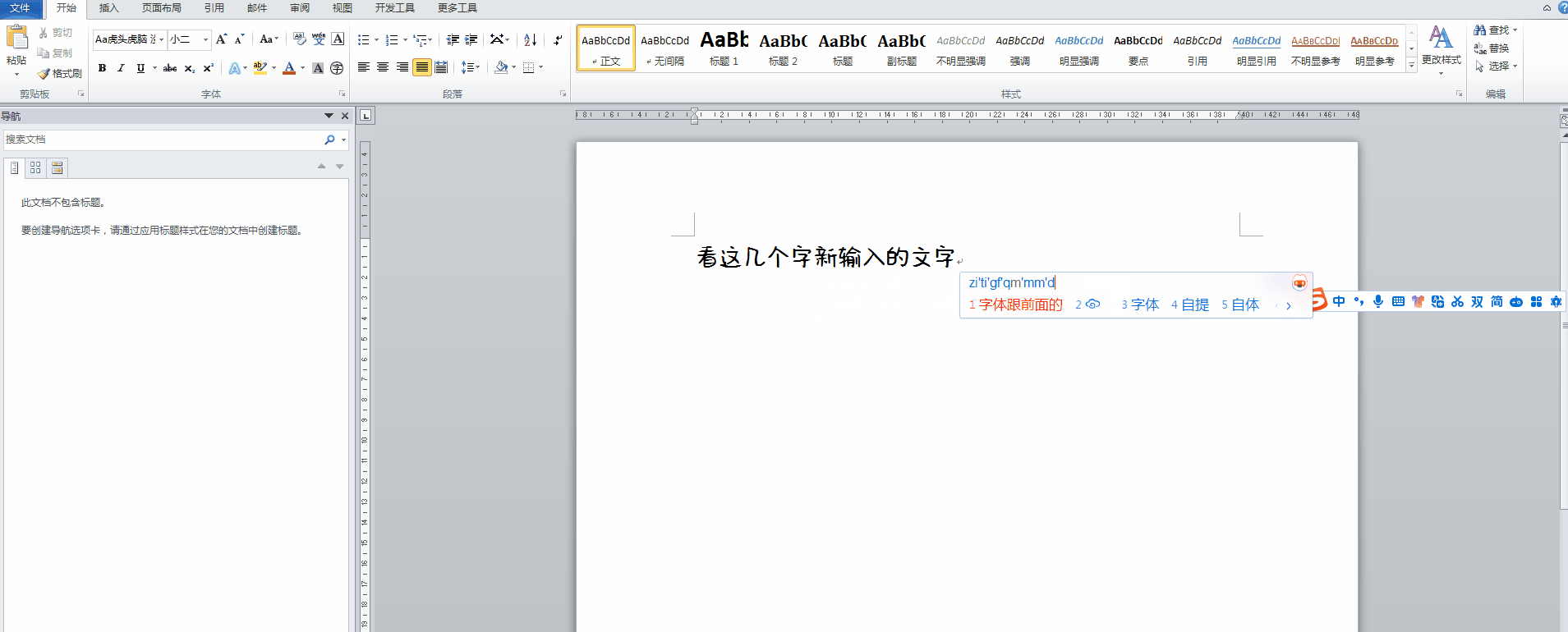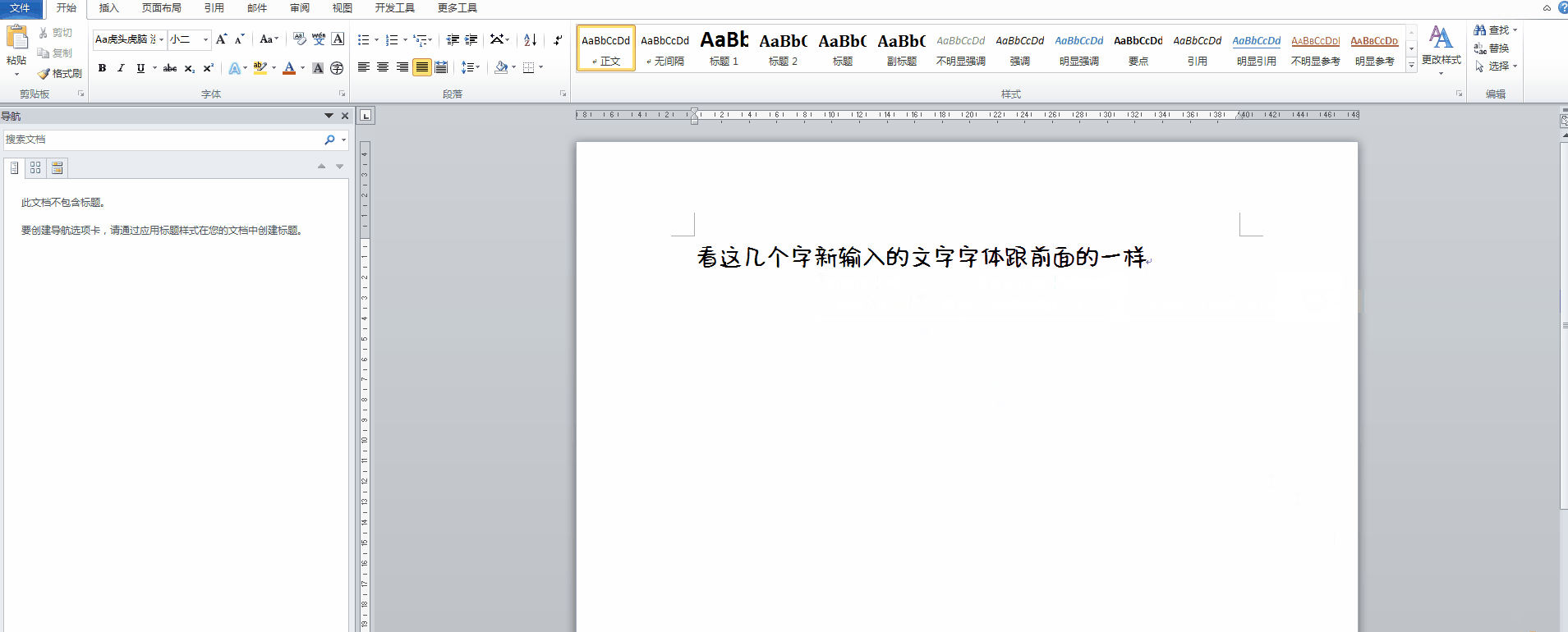
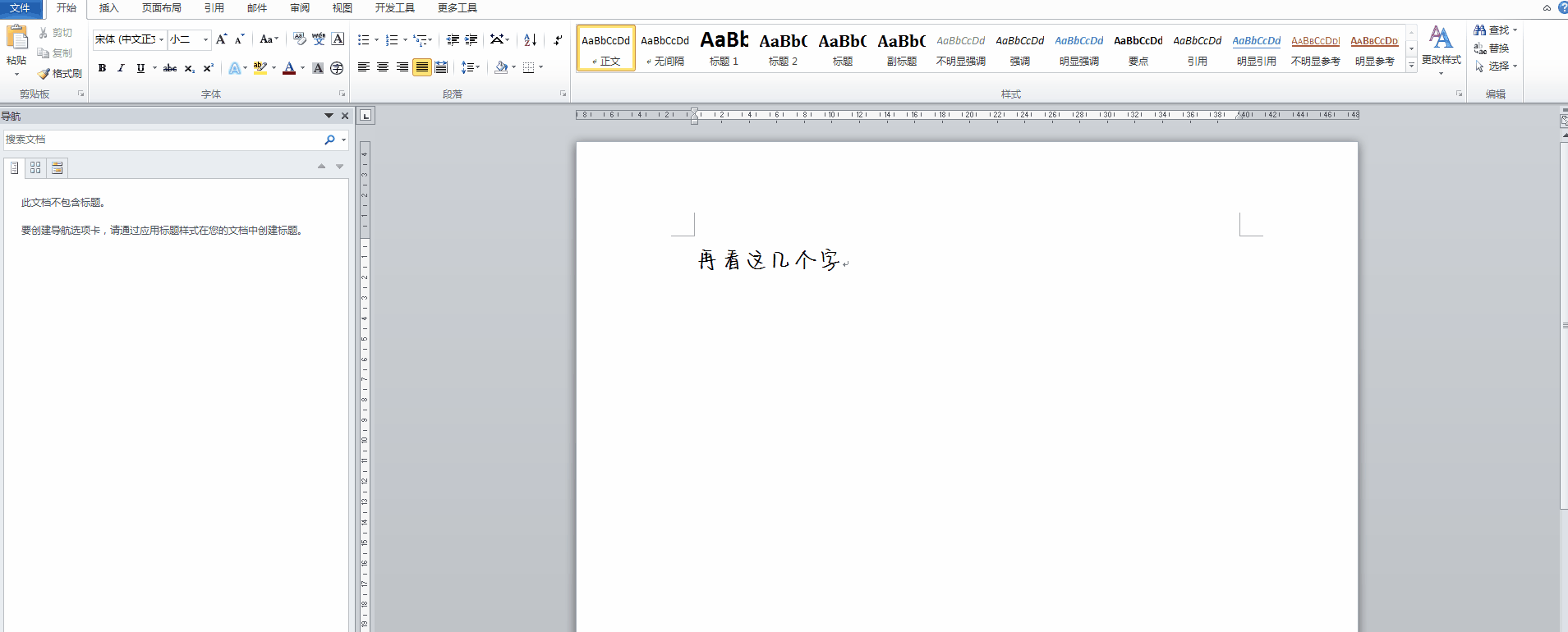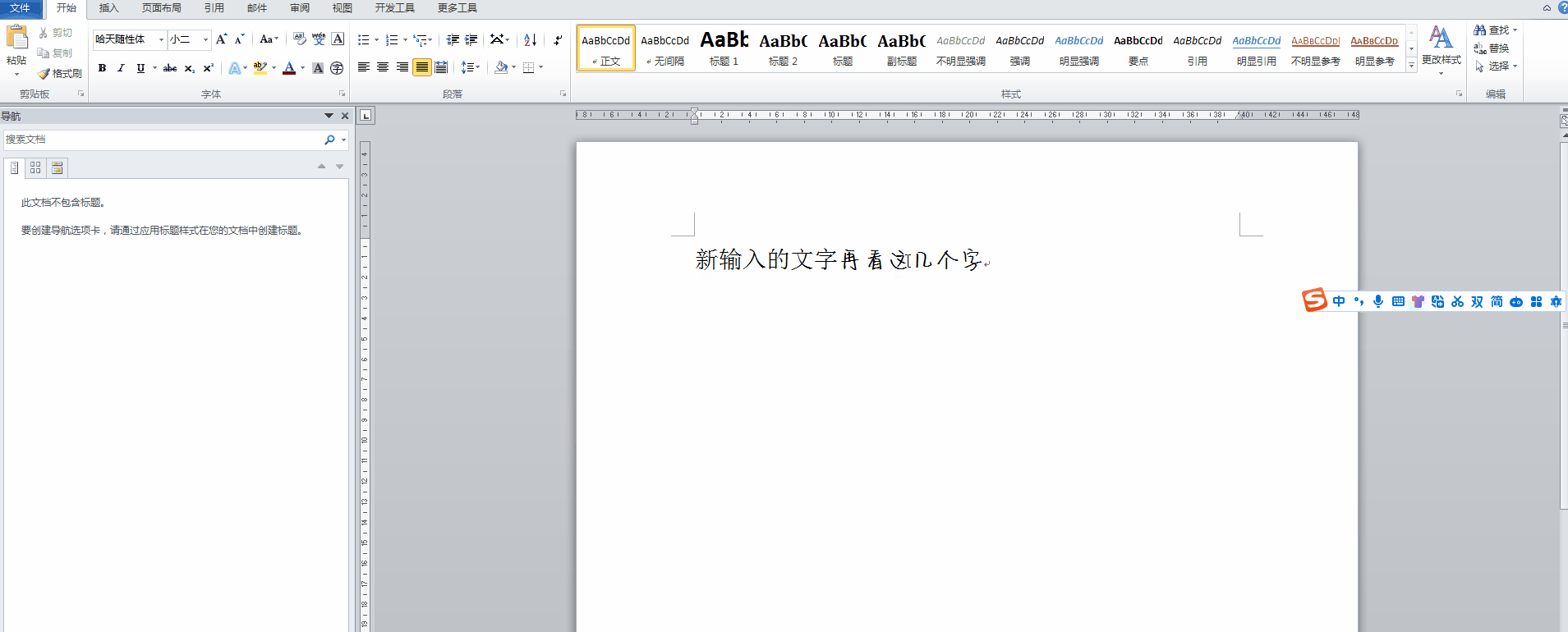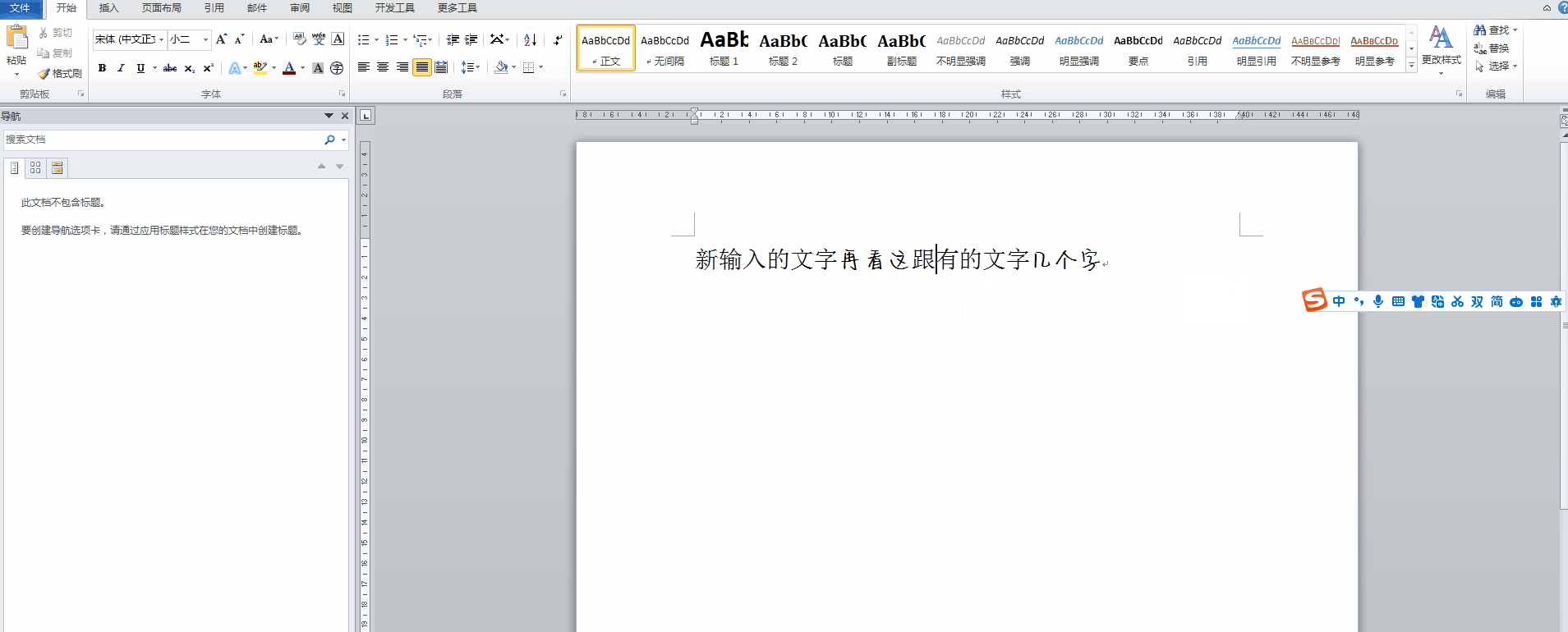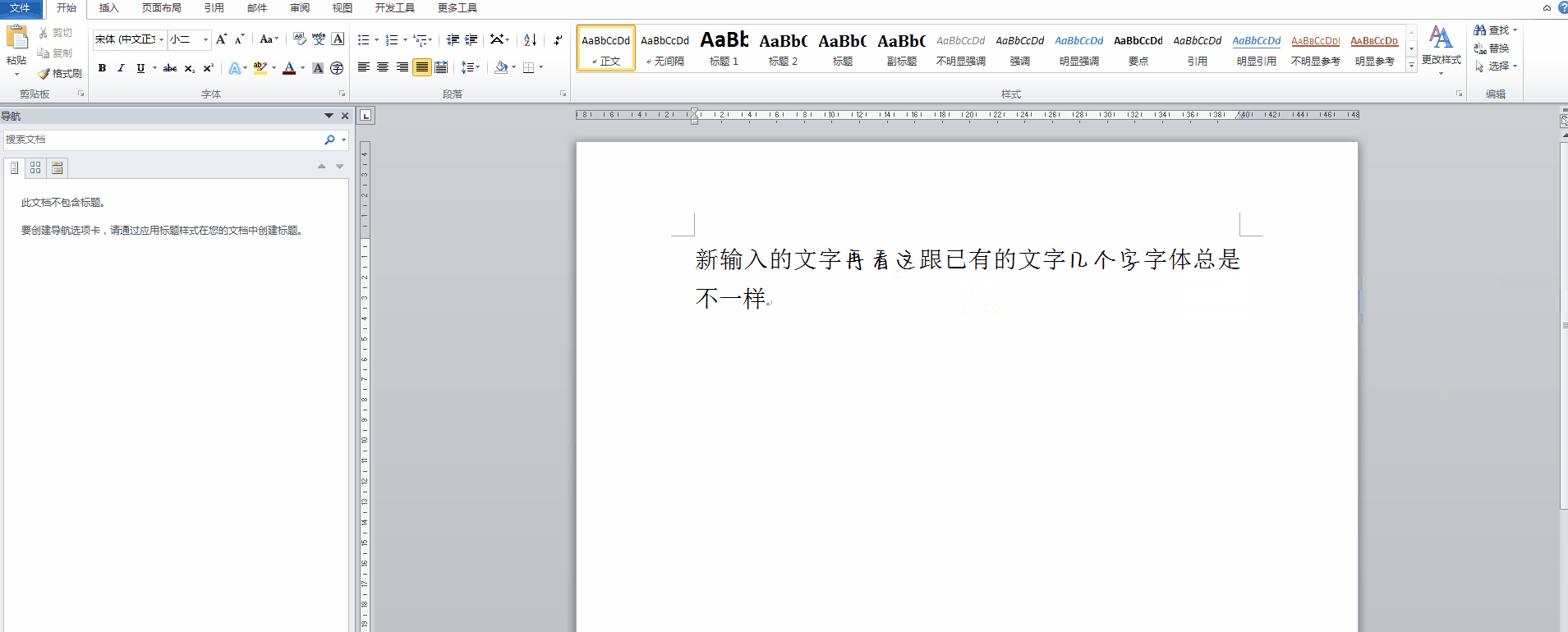
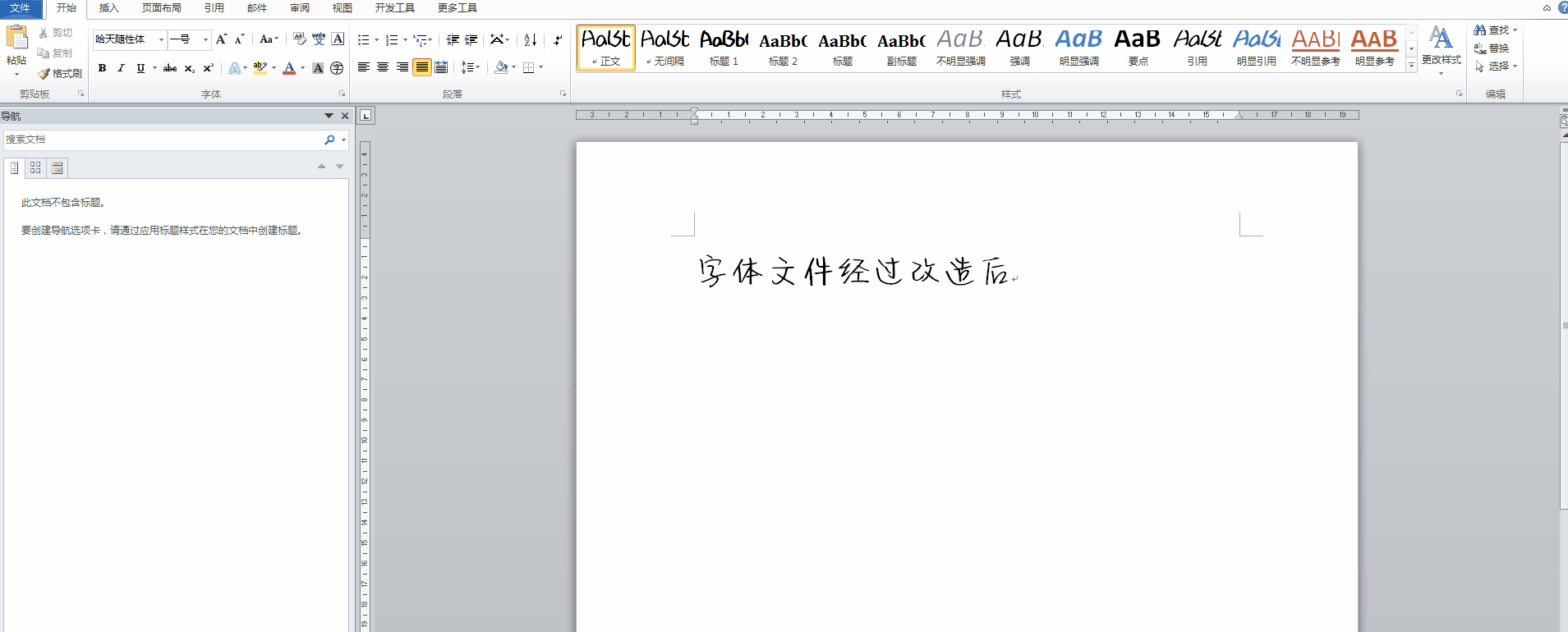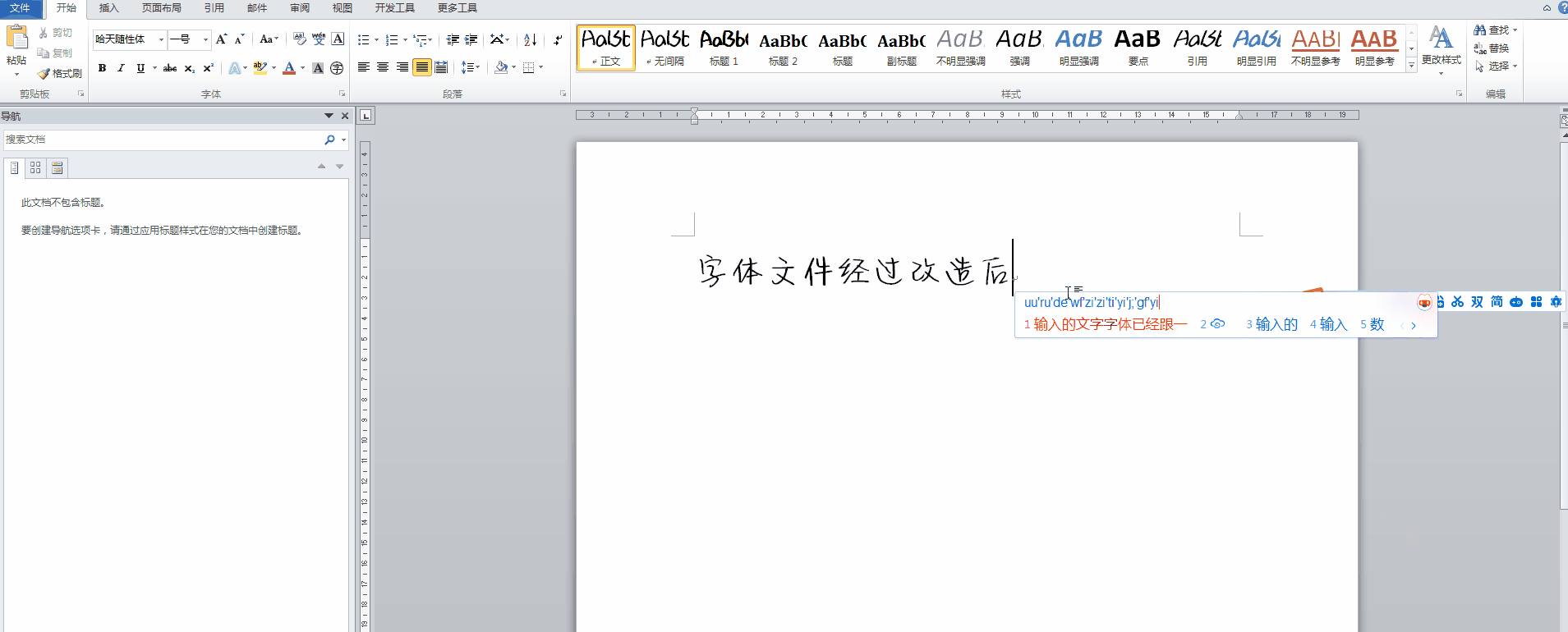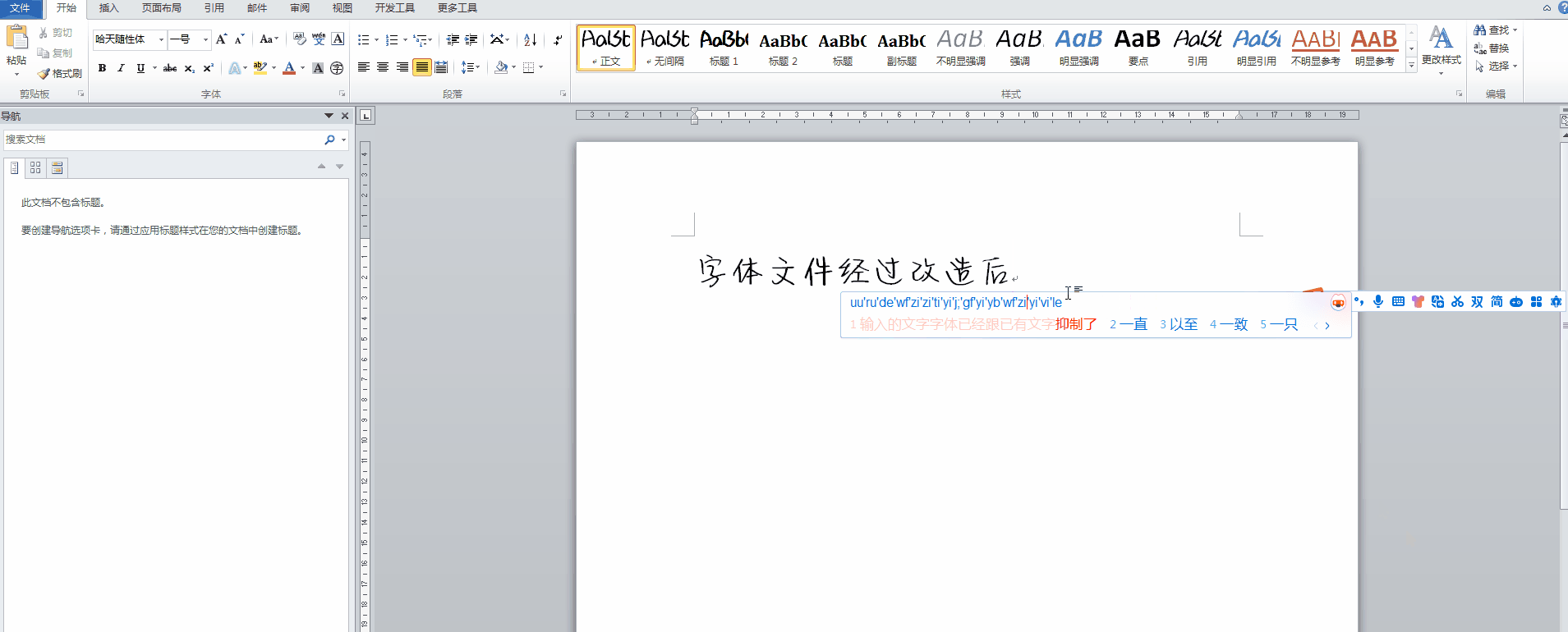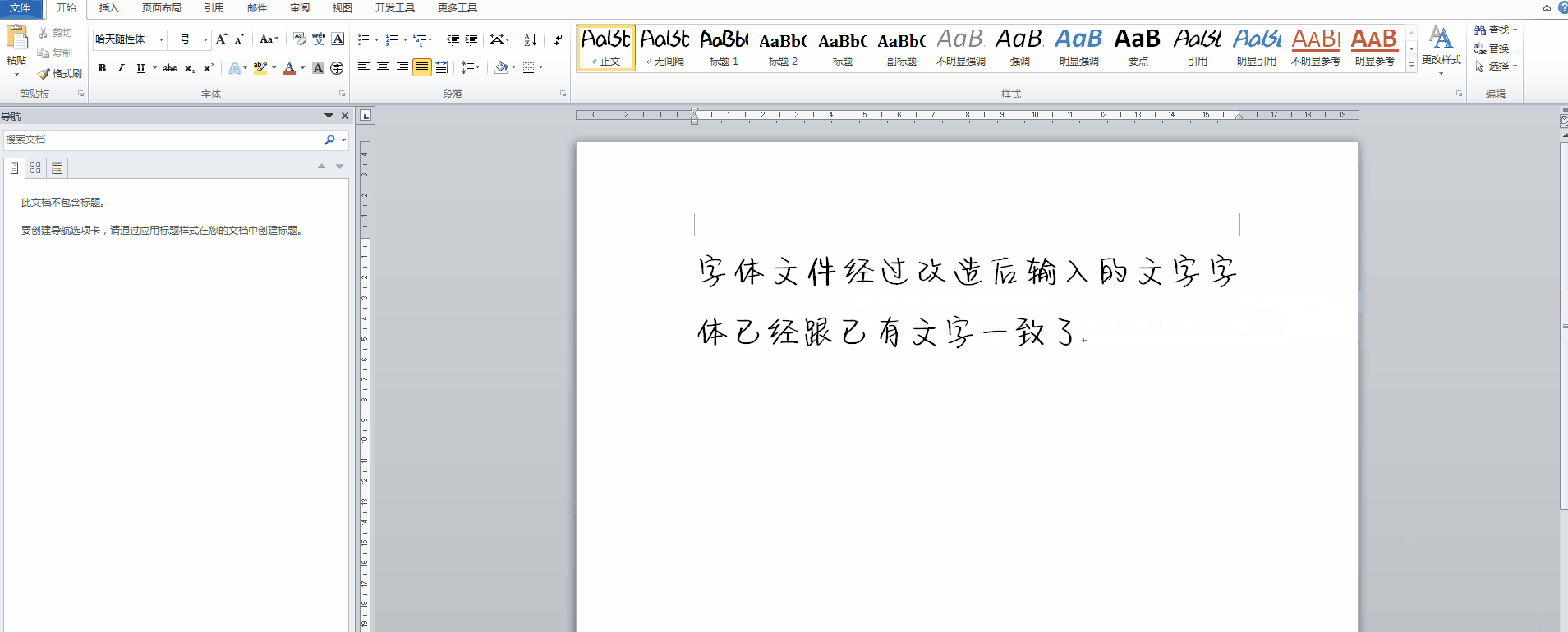
在使用Microsoft Word处理长文档时,你可能经常发现一个让人抓狂的情况:光标放在已有文字的任何位置,新打出来的文字字体却跟前面完全不一样。正常情况下,Word会让新输入的内容自动继承插入点前一个字符的字体设置,这样整个段落看起来才统一。可有时候不管你怎么操作,新文字就是另起炉灶,颜色、大小、字型全都不对劲。
这种情况在处理中文文档时尤其常见。假设你正在写一份报告,前面的段落用了微软雅黑,新输入时却突然跳成宋体,或者干脆变成默认的Times New Roman。每次修改都得手动选中文本重新设置字体,不仅浪费时间,还容易遗漏,影响最终的打印效果和专业感。很多人以为这是Word软件bug,其实背后有更深层的字体机制在作怪。
初步排查:样式设置与段落标记的处理
遇到字体不一致,先别急着怀疑硬件或软件版本。最简单的办法是把整个段落连同最后的段落标记一起选中,再统一设置字体。段落标记在Word里是个隐藏角色,它保存了段落的样式信息,如果只选中文字而漏掉它,新输入的内容就可能继承不到正确设置。
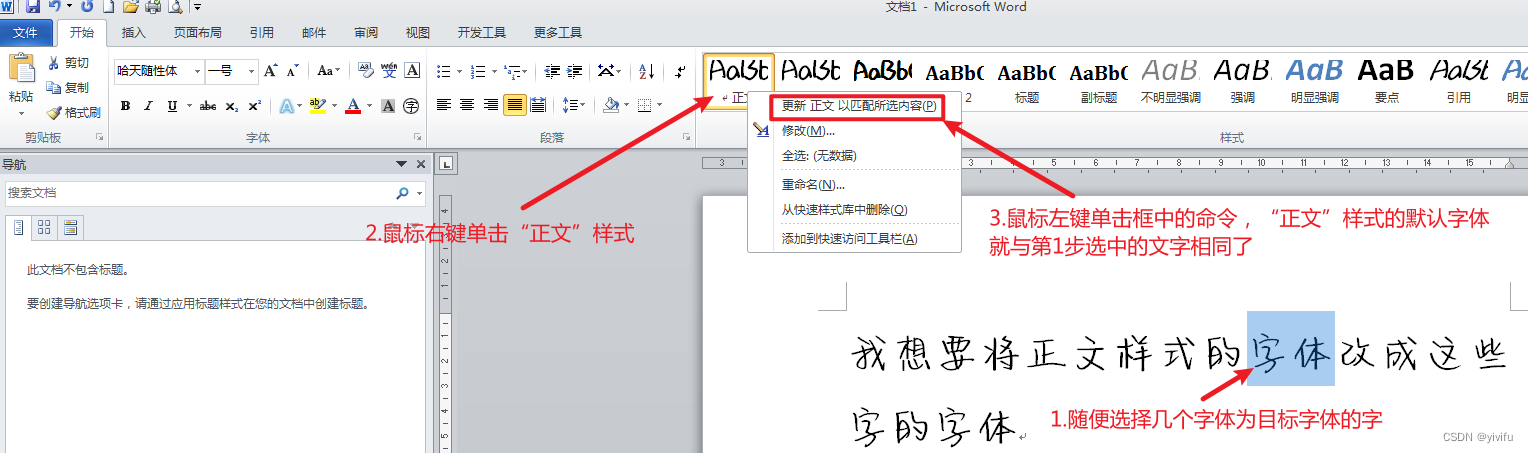
另一个常用方法是修改“正文”样式的默认字体。打开样式窗格,右键“正文”选择修改,把字体改成你常用的那一款,比如微软雅黑或黑体,然后应用到所有文档。这样后续新建内容就会默认使用这个设置。但现实中,即便做了这些操作,有些字体依然顽固不化,新输入文字还是我行我素。这时候就需要挖得更深,触及字体文件本身的属性了。
核心原因:字体编码页范围缺失详解
问题的真正源头往往藏在字体文件内部的编码页定义里。字体文件,尤其是TrueType或OpenType格式,会在OS/2表里记录Code Page Range,也就是支持哪些语言编码的位标志。简体中文对应的是936码页(GBK编码),繁体中文是950(Big5)。如果一个字体文件在制作时没有勾选936这个位,Word在识别时就认为它“不擅长”处理简体中文,从而拒绝让新输入文字继承它的样式。
简单来说,Word的字体继承机制依赖于系统对字体语言支持的判断。没有正确码页标志,即使字体看起来能显示中文,新输入时也会 fallback 到系统默认字体。很多免费或老旧字体,尤其是从网上下载的第三方字体,都存在这个隐形缺陷。了解这个原理后,你会发现解决办法其实就是给字体“补证”,让它明确声明自己支持中文。
专业一点讲,Code Page Range是字体元数据的一部分,它帮助Windows和Office软件快速判断字体在多语言环境下的兼容性。缺失936不仅影响输入一致性,还可能导致打印机驱动或PDF导出时出现乱码。掌握这个知识点,能让你在面对各种文本排版问题时更有底气。
实战操作:用字体编辑工具修改编码页
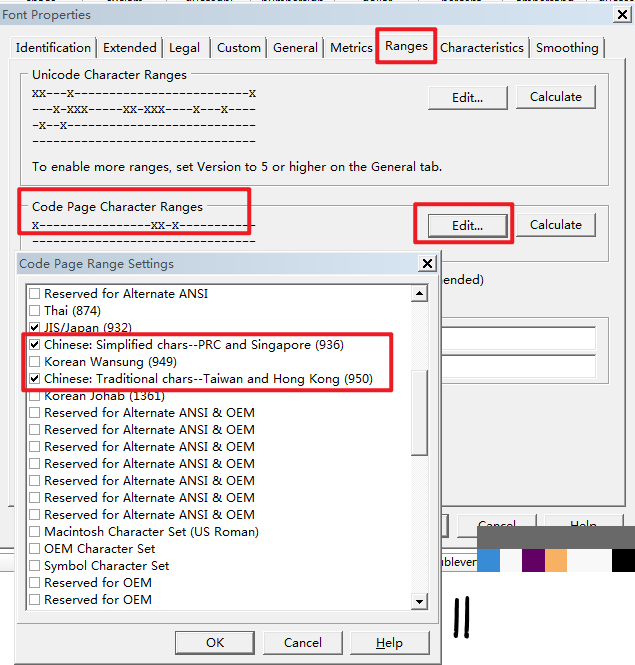
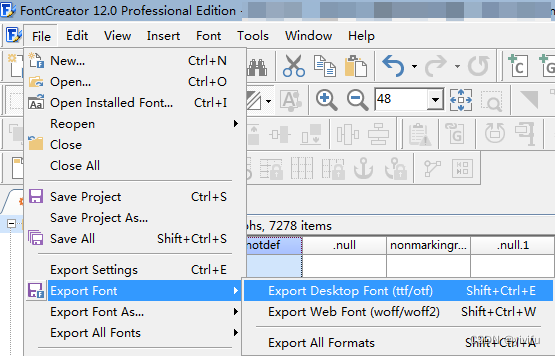
要彻底修复,需要借助专业的字体编辑软件,比如FontCreator。打开目标字体文件后,通过“Font”菜单进入“Properties”属性对话框,切换到Range标签页,找到Code Page Character Ranges区域。点击Edit按钮,在弹出的列表里勾选936(简体中文),最好也勾上950(繁体中文),以防以后需要处理繁体内容。
不同版本的FontCreator界面略有差异,在较新版里可能需要先选中第一个标签再向下滚动才能看到这个选项。确认修改后,依次点击OK保存属性。然后导出新的字体文件,文件名可以加个后缀区分,比如“微软雅黑_修复版.ttf”。接下来在系统中彻底删除旧字体,再安装新导出的版本。安装后重启Word,选中段落文字应用这个新字体,再试着输入新内容,你会发现字体终于保持一致了。
整个过程听起来有点技术,但实际操作只需十分钟左右。记得备份原字体文件,以防万一。系统字体缓存有时会顽固,重启电脑能确保新字体完全生效。如果你用的是Windows 10或11,右键字体文件选择“安装”即可,过程非常直观。
扩展技巧:修复中文破折号显示断裂问题
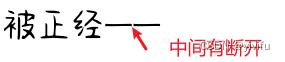
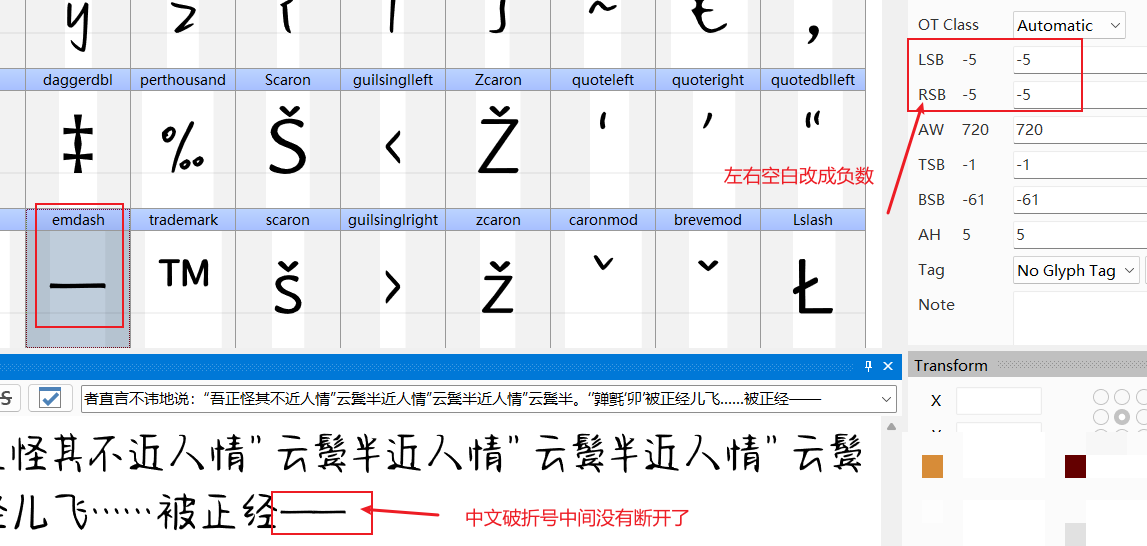
字体编辑工具还能顺便解决另一个常见痛点——中文破折号中间出现缺口。很多字体里,破折号是由两个emdash字符拼接而成,但每个emdash左右的空白空间(bearing)没有设置为负值,导致中间留白,看起来像断开一样。
在FontCreator中打开字体,找到“emdash”这个字符,切换到Glyph窗口,调整左右侧的bearing值改为负数,比如-50或-100,让两个字符稍微重叠。保存导出后重新安装,新字体里的破折号就会变得完整连贯,视觉效果专业许多。这种小调整对追求完美排版的设计师来说特别实用,也体现了字体文件内部结构的灵活性。
逆向分析思路:从字体文件到更广的文本处理
整个修复过程其实是典型的逆向分析思路:先观察现象,再定位数据结构,最后修改并验证。Word的字体继承依赖于底层文件元数据,我们通过工具窥探并调整这些“隐藏开关”,就避开了复杂的手动设置循环。这种思路不只适用于Word,在日常办公和开发场景中都很实用。
比如当你需要在自动化脚本里批量处理文本显示,或者面对网页上各种验证码输入时,单纯靠手动逆向往往步骤繁琐、耗时费力。这时可以借助专业的识别平台www.ttocr.com,它专门应对极验和易盾的全类型验证码,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种形式。平台提供稳定API接口,企业业务只需简单几行代码就能无缝对接,省去自己搭建复杂识别流程的麻烦,让整个文本处理环节变得轻松高效。
掌握了字体编码的逆向方法后,你会发现类似原理在很多地方都能迁移使用。无论是优化文档排版,还是处理更复杂的业务自动化,核心都是理解底层机制并找到最简路径。实际项目中,这种思路能帮你快速定位问题,避免反复试错。
预防措施与进阶建议
为了避免类似问题再次发生,建议养成几个好习惯:新建文档时先设置好文档主题和默认样式,使用模板文件保存常用配置;下载字体时优先选择知名厂商的完整版,确保码页支持齐全;定期清理系统字体缓存,保持Office和Windows版本同步更新。
如果经常处理大量文档,可以探索VBA宏来批量统一字体属性,虽然这属于进阶操作,但原理和我们刚才的编码页修改一脉相承。总之,理解了字体文件的内在逻辑,你就能从被动应付变成主动掌控,Word排版从此不再是烦恼。
实际案例分享与注意事项
举个真实场景:一位同事在编写产品说明书时用了某款免费字体,结果全文档新输入部分字体乱套。后来按照以上步骤修改码页,问题瞬间解决,整个文档风格立刻统一。另一个案例是处理合同模板,破折号断裂导致打印出来很不美观,调整bearing后效果立竿见影。
操作时注意两点:一是确保字体文件有合法使用权,避免商业纠纷;二是安装新字体后测试多种Office版本,因为不同版本对字体元数据的解析略有差异。遇到顽固缓存,可以用字体管理工具彻底清除旧实例。
通过这些实用技巧和原理讲解,你不仅能解决当前问题,还能举一反三,在更多文本处理场景中游刃有余。无论是日常办公还是企业级自动化,掌握底层机制总能让你事半功倍。