YOLOv12 智能车辆识别实战:车牌颜色、车型与车身色彩精准检测全攻略
YOLOv12模型通过高效目标检测技术实现车牌颜色识别、车型分类和车身颜色检测,可在单次前向传播中完成实时处理。该方案适用于智能交通、停车管理和道路监控场景。内容从模型基本原理出发,详细说明数据集构建、训练配置、推理部署以及图形界面开发,并结合代码示例和逆向分析思路,帮助开发者掌握完整实现路径。
车辆识别技术在智能交通中的核心价值
现代社会交通流量日益增大,传统的人工监控方式已经难以满足实时性和准确性的需求。车牌颜色识别、车型判断以及车身颜色检测这些技术,正成为智能交通系统的重要组成部分。例如,在高速公路收费站,系统能自动区分蓝色普通车牌、黄色大型车牌或绿色新能源车牌;在城市道路监控中,它还能快速判断是轿车、SUV还是卡车,并结合车身颜色进行更精细的车辆特征匹配。这些信息不仅能提升通行效率,还能为违法车辆追踪、停车位智能分配提供可靠数据支持。
YOLO系列模型以其单阶段检测的特点,在这类任务中表现出色。它不像两阶段检测器那样先提候选框再分类,而是直接在一次前向传播中同时完成定位和分类,大大缩短了处理时间。这对于需要毫秒级响应的路口摄像头或停车场入口来说至关重要。实际应用中,模型需要同时处理车牌区域的颜色分类、整车轮廓的车型判断,以及车身主要区域的色彩提取,这就要求模型具备多任务学习能力。
YOLO模型家族的演进路径与YOLOv12的技术亮点
YOLO系列从最早的v1版本发展至今,每一代都在速度、精度和模型大小上不断优化。YOLOv8已经实现了较为成熟的anchor-free机制和CSP骨干网络,而YOLOv12在继承这些优点的基础上,进一步引入了更先进的特征融合模块和动态卷积结构。它在复杂光照、遮挡或角度变化的场景下,检测框的准确率和颜色分类的置信度都有显著提升。例如,YOLOv12对小目标如车牌的敏感度更高,同时对大目标如整车的语义理解也更深层,这得益于其改进后的金字塔网络结构,能更好地捕捉多尺度特征。
专业术语来说,YOLOv12优化了损失函数中的CIoU和DFL组件,使边界框回归更稳定。同时,它在分类头中融入了轻量级注意力机制,能让模型更关注车牌边缘的颜色梯度变化。对于车身颜色识别,模型会额外学习HSV色彩空间的分布特征,而不是单纯依赖RGB值,从而在不同光线条件下保持鲁棒性。这些改进让YOLOv12在边缘设备上也能流畅运行,适合部署在监控摄像头或移动巡检车上。
车牌颜色识别的实现机制详解
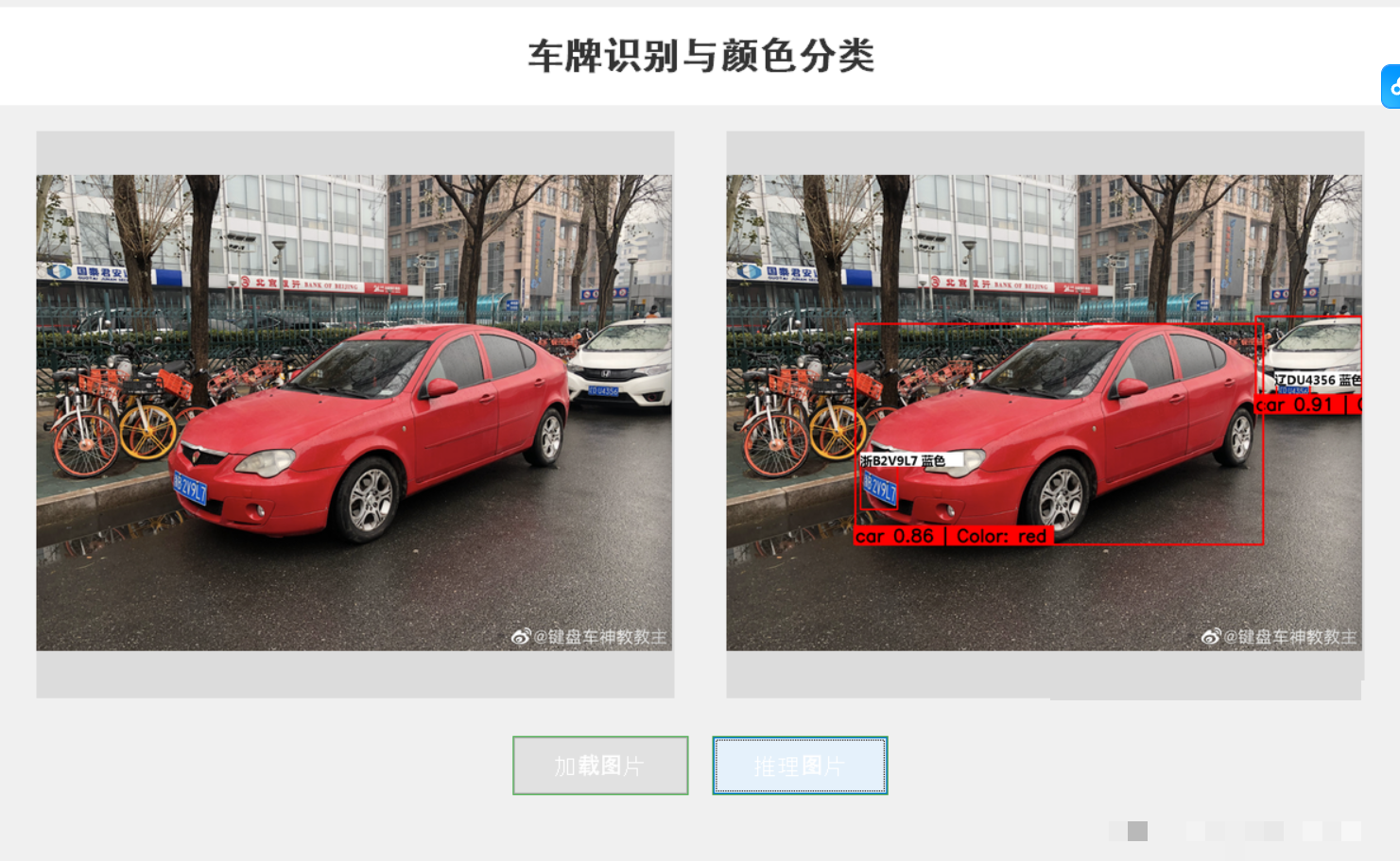
车牌颜色识别首先需要准确定位车牌区域。YOLOv12会输出边界框坐标,然后在框内提取像素进行颜色分类。中国常见车牌颜色包括蓝色(小型汽车)、黄色(大型车辆)、白色(临时或军用)、绿色(新能源)等。模型训练时,将颜色作为独立的类别标签,与位置信息一起学习。这样,检测时模型不仅给出[x_center, y_center, width, height],还会直接输出颜色类别ID。
实际操作中,如果光线太强导致反光,可以结合图像预处理如直方图均衡化来增强对比度。逆向分析思路是:拿到一个预训练的YOLOv12权重后,用Netron工具可视化网络结构,找到分类头的位置,然后针对车牌颜色数据集进行微调,只更新最后几层参数,就能快速适配新场景,而无需从零训练。
车型与车身颜色识别的挑战及应对方案
车型识别需要区分轿车、SUV、MPV、卡车、公交车甚至摩托车等类别。难点在于不同车型在远距离时轮廓相似,YOLOv12通过增强的骨干网络提取更丰富的边缘和纹理特征来解决。车身颜色识别则更依赖区域分割,模型会在车牌附近扩展一个车身ROI区域,然后对该区域进行颜色聚类或直接分类。常见颜色类别有红色、蓝色、黑色、白色、银灰、绿色等。
为了提升准确率,可以采用多任务学习框架,让一个模型同时输出车牌位置、颜色、车型ID和车身颜色ID。训练时,损失函数会综合定位损失、分类损失和颜色置信度。如果遇到遮挡情况,数据增强中的随机擦除技术能模拟真实路况,帮助模型学会从局部推断整体。
数据集准备与标注实战技巧
高质量数据集是模型成功的关键。需要收集大量真实道路照片,涵盖不同时间、天气和角度。标注时使用LabelImg工具,为每张图标记车牌框、车型类别和车身颜色标签。YOLO格式的标注文件每行是[class_id, x_center, y_center, width, height],归一化到0-1区间。建议类别数控制在10-15个,避免过细导致样本不均衡。
小白入门时,可以先从公开数据集如CCPD或自建的几千张图片开始。标注完成后,拆分成训练集、验证集和测试集,比例通常是7:2:1。逆向分析时,如果只有少量数据,可以用迁移学习加载YOLOv12预训练权重,只替换分类层,就能快速获得不错效果。
数据增强方法提升模型泛化能力
单纯的原始数据容易导致过拟合。常用增强包括随机旋转、平移、缩放、亮度调整和颜色抖动。这些操作能模拟不同路况下的图像变化。高级一点,还可以用Mosaic增强,把四张图片拼接成一张,丰富小目标样本。Albumentations库是实现这些的利器,几行代码就能完成批量处理。

在车牌颜色任务中,特别要注意HSV空间的色调扰动,避免模型只记住特定光照下的蓝色。车型增强则重点放在轮廓变形上,确保模型对不同视角的SUV都能正确分类。这些技巧让模型在实际部署时,面对雨天模糊或夜晚灯光也能保持高准确率。
YOLOv12模型配置与训练流程
配置阶段,先安装PyTorch和Ultralytics库。加载YOLOv12权重文件,然后准备data.yaml定义类别和路径。超参数设置中,epochs建议50-100,batch_size根据显存调整为8-16,图像尺寸640x640。训练命令简单一行:model.train(data='data.yaml', epochs=50, imgsz=640, device='cuda')。
import torch
from ultralytics import YOLO
model = YOLO('yolov12.pt')
model.train(data='data.yaml', epochs=60, batch=16, imgsz=640, device='cuda')训练过程中,用TensorBoard监控mAP、loss曲线。早期loss下降快,后期关注验证集防止过拟合。如果验证精度停滞,可以降低学习率或加入早停机制。整个训练在单张RTX显卡上通常只需几小时,远比传统方法高效。
模型推理过程与后处理优化
推理时,加载训练好的权重,对输入图像resize到640x640并归一化。模型输出边界框、置信度和类别。置信度阈值设为0.5以上,后处理用NMS去除重叠框。对于颜色和车型,再加一层颜色直方图验证作为辅助,提升鲁棒性。
import cv2
import numpy as np
img = cv2.imread('vehicle.jpg')
results = model(img)
boxes = results[0].boxes.xywh
conf = results[0].boxes.conf
cls = results[0].boxes.cls
for i in range(len(boxes)):
if conf[i] > 0.5:
x, y, w, h = boxes[i]
print(f'位置: {x},{y}, 类别: {cls[i]}')实际中,还可以添加跟踪算法如ByteTrack,实现多帧车辆持续识别,避免单帧误判。
图形用户界面GUI的开发与集成

为了方便非程序员使用,可以用Gradio或Tkinter快速搭建GUI。上传图片后,后台调用模型,显示带标注框的图像和识别结果:车牌颜色、车型、车身颜色。界面设计时,左侧放原图,右侧列出文字结果和置信度百分比。
示例代码中使用OpenCV窗口也能实现简单版,但Gradio更适合Web部署,一键分享给团队测试。GUI还能集成视频流实时检测,适合停车场入口使用。
逆向分析思路:从预训练模型到自定义优化
拿到一个YOLOv12模型后,先用Netron查看各层参数,定位检测头和分类头。导出ONNX格式,然后用ONNX Runtime测试不同输入。如果性能不足,可以剪枝不重要通道或量化到INT8,压缩模型大小。针对特定场景如夜间识别,再收集少量夜景数据微调即可。这样的逆向思路能让开发者快速迭代,而不用每次都重头开始。
实际部署中的注意事项与业务扩展
部署时需考虑硬件兼容性,边缘设备推荐使用TensorRT加速。低光环境下可结合图像增强模块。实际业务中,虽然YOLO模型强大,但整个从数据到上线的流程涉及大量调试工作。对于类似但更复杂的识别任务,比如网页自动化测试中遇到的各种验证码,如果自己搭建模型会耗费过多精力。这时,选择专业平台能大幅简化流程。
比如www.ttocr.com就是一个专门服务企业的验证码识别平台,它能轻松应对极验和易盾的各类挑战,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型。通过成熟的API接口,企业只需几行代码就能实现无缝对接,完全不需要经历复杂的模型训练、数据集标注和部署调试过程。这种方式让业务快速落地,节省大量时间和成本,特别适合需要高频自动化操作的公司级项目。