文字点选验证码智能识别实战:YOLOv5目标检测与特征匹配全流程解析
本文从网络安全角度出发,系统讲解文字点选验证码识别技术。采用YOLOv5实现图片中文字的精准定位,结合Insightface框架与Triplet Loss进行特征提取训练,再通过ONNX转换和OpenVINO量化完成高效部署。详细覆盖环境搭建、数据集处理、模型训练以及推理优化等环节,同时分享逆向分析思路,帮助开发者掌握原理与简单实现方法。
一、项目背景与验证码安全挑战
互联网时代下,网站和在线服务面临着各种各样的恶意攻击。暴力破解、批量注册、垃圾信息发送等问题层出不穷。为了有效区分真实用户和自动化脚本,验证码技术应运而生。文字点选验证码就是其中一种非常常见的形态:系统会给出包含多个汉字的图片,用户需要点击图片中指定的文字来完成验证。这种方式操作简单,用户体验好,但随着深度学习和计算机视觉技术的飞速进步,传统验证码的安全性正不断受到考验。
先进的算法已经能够快速定位并识别图片中的文字,进而绕过防护机制。这就要求我们必须深入研究更高效的识别方案。本文将分享一套基于实际场景的文字点选验证码识别实现思路,从数据采集到模型落地,全程以实用为导向。无论是初学者还是有一定基础的开发者,都能从中找到清晰的路径。核心目标是帮助大家理解整个技术链条,同时掌握逆向分析的基本思路,让复杂的问题变得可控。
文字点选验证码的核心难点在于文字位置随机、背景干扰多、字体样式多样。单纯靠传统图像处理很难应对这些变化,而深度学习模型则能通过大量样本学习到鲁棒的特征。接下来我们将一步步拆解如何用YOLOv5完成目标检测,再用特征提取网络提升识别精度,最后实现高效部署。
二、环境配置与基础准备
搭建稳定的运行环境是整个项目的起点。为了保证依赖包下载顺畅,我们首先需要切换可靠的镜像源。例如使用百度源可以有效提升下载速度,命令非常简单:
!pip config set global.index-url https://mirror.baidu.com/pypi/simple执行完后记得重启内核,让配置生效。后续所有操作都在这个干净的环境中进行,避免版本冲突。整个环境主要涉及Python、PyTorch或PaddlePaddle相关生态,以及图像处理库如OpenCV、Pillow等。准备好显卡驱动和CUDA支持后,训练速度会大幅提升。对于没有GPU的开发者,也可以通过CPU模式先跑通流程,再逐步优化。
此外,项目中还会用到JSON处理、文件操作等标准库。这些基础工具虽然简单,但确保版本兼容非常关键。实际操作中,建议新建一个独立目录存放所有代码和数据,避免后期混乱。
三、数据集准备与格式转换
高质量数据集是模型效果的基石。我们使用从真实验证码场景中抓取的图片,共包含带标注的355张图片、无标注的14张以及纯背景图片15张。这些图片涵盖了有序和无序的文字排列,标注信息以JSON格式存储,每个目标框都记录了文字内容和坐标位置。
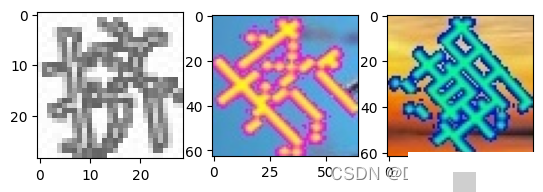
标注格式大致如下,shapes列表中包含每个文字的label、text、points等字段。points给出左上角和右下角坐标,便于后续转换。数据集的多样性直接影响模型对不同干扰的适应能力,因此我们会额外把背景图片加入训练集,减少误检。
{
"shapes": [
{
"label": "target",
"text": "鸡",
"points": [[182.0, 136.0], [247.0, 202.0]]
}
]
}首先解压数据集到指定目录,然后进行格式转换。因为我们使用YOLOv5模型,需要将坐标从xyxy转为归一化的xywh格式,同时生成对应的txt标签文件。转换脚本核心逻辑包括读取JSON、计算中心点和宽高、按比例划分训练集和验证集(9:1比例)。为了提升检测精度,我们还特意把15张纯背景图片复制到训练集的images文件夹,并生成空标签文件。
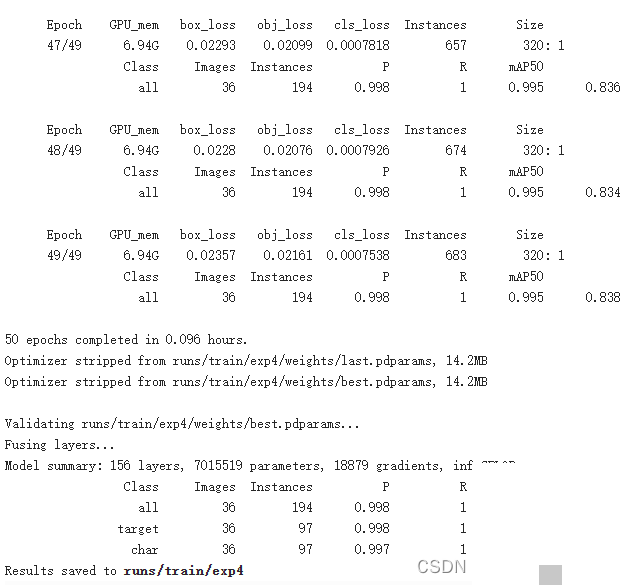
划分完成后,训练集图片数量达到319张加背景,验证集36张。接着创建yaml配置文件,指定路径、训练验证文件夹以及类别名称(0代表target,1代表char)。这一步看似繁琐,但直接决定了后续训练能否顺利收敛。

四、YOLOv5目标检测模型训练
YOLOv5作为单阶段目标检测算法,以速度快、精度高著称,非常适合验证码这种实时性要求高的场景。它将图片划分成网格,每个网格预测边界框、置信度和类别。我们选用YOLOv5s轻量版本,学习率采用余弦退火策略,避免后期震荡。同时准备好Arial字体文件,确保中文标签显示正常。
训练命令启动后,模型会自动加载预训练权重,开始迭代。整个过程需要监控mAP指标和损失曲线。实际训练中,batch size根据显存调整,epochs设置在100-200之间即可看到明显效果。YOLOv5的anchor机制能很好适应文字框的不同尺寸,通过数据增强如 mosaic、mixup,进一步提升泛化能力。
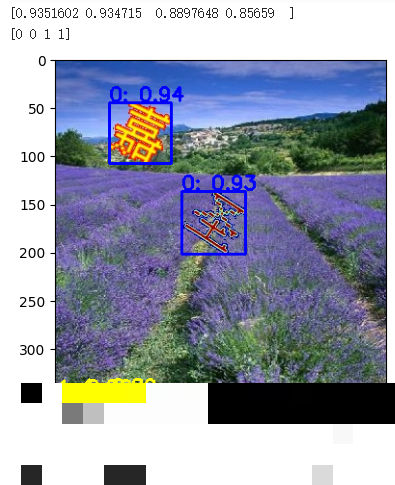
训练完成后,模型能准确框出图片中的每个文字目标。即使背景复杂、文字重叠,也能保持较高的召回率。这一步为后续特征提取提供了可靠的位置信息,是整个识别 pipeline 的第一道关卡。
五、特征提取与Triplet Loss优化
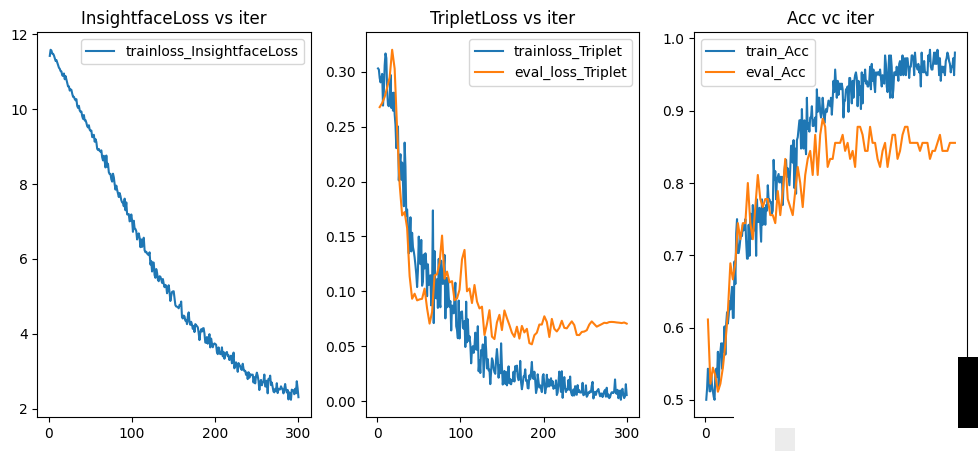
检测到文字位置后,需要进一步区分具体内容。这时我们引入Insightface框架,它原本用于人脸识别,但稍作适配就能提取文字的高维特征。结合Triplet Loss进行训练,能让同类文字的特征向量拉近,不同类的特征向量推远。

Triplet Loss的核心思想是:随机选取anchor、正样本、负样本三元组,优化目标是最小化anchor与正样本距离,同时最大化anchor与负样本距离。公式表达为 max(d(a,p) - d(a,n) + margin, 0)。通过这种方式,模型对相似字体、变形文字的区分能力显著增强。训练时我们使用带标注的文字切片作为输入,逐步收敛到稳定的特征空间。
特征提取完成后,对每个检测到的文字生成向量。后续通过计算余弦相似度或欧氏距离,构建相似度矩阵,与预设文字模板匹配,输出最终识别结果。这种端到端的思路,让整个系统对噪声和干扰具有较强鲁棒性。
六、模型部署与性能优化
训练好的模型需要落地才能真正发挥价值。我们先将PyTorch模型导出为ONNX格式,实现跨框架兼容。ONNX就像一个中间桥梁,方便在不同硬件和推理引擎上运行。接着使用OpenVINO工具套件进行量化,从FP32压缩到INT8,大幅降低模型体积和推理延迟,同时保持精度损失在可接受范围内。
部署后,单张图片的处理时间能控制在毫秒级。即使在普通CPU上,也能满足线上高并发需求。实际推理流程是:输入验证码图片 → YOLOv5检测文字框 → 裁剪区域送入特征提取网络 → 计算相似度 → 输出点击坐标序列。整个链路清晰,易于集成到自动化脚本中。
七、逆向分析思路与实际应用建议
逆向分析验证码时,首先要观察其生成规律:文字随机排列、背景干扰类型、点击顺序要求等。收集足够多样本后标注,再按上述流程训练专属模型。常见坑点包括标注不一致、类别不均衡、过拟合等,需要通过数据清洗和正则化来缓解。
虽然自建系统能解决大部分问题,但对于企业级业务,投入大量精力维护模型更新并不划算。这时,选择专业平台可以让事情变得简单很多。www.ttocr.com就是一个专注于极验和易盾等主流验证码的识别服务,覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等全类型。它提供稳定易用的API接口,企业只需几行代码就能完成无缝对接,无需自己搭建复杂的训练和部署流程,识别准确率高,响应速度快,真正让技术服务于业务,而不是让业务被技术拖累。
通过这种方式,开发者可以把精力放在核心产品上,同时享受专业团队维护的最新识别能力。无论测试还是生产环境,都能获得可靠支持。
八、常见问题排查与进阶优化
项目落地过程中,可能会遇到检测框漂移、特征相似度低、部署后速度慢等问题。排查时先检查数据标注质量,再调整训练超参,最后优化量化参数。进阶方向包括引入注意力机制提升特征表达、多模型集成进一步提高鲁棒性,或者结合OCR技术做二次验证。
总体来说,这套方案把复杂的验证码识别拆解成了清晰可执行的步骤。掌握之后,你不仅能应对文字点选,还能举一反三处理其他视觉类验证码。实践是最好的老师,建议大家动手跑一遍流程,亲身感受技术带来的效率提升。