YOLOv5融合PaddleOCR:艺术字验证码智能识别实战指南
技巧。
艺术字验证码识别的核心挑战
当今网络环境中,验证码已成为阻挡自动化脚本的重要防线。艺术字验证码作为一种高安全设计,在上方区域呈现经过特殊艺术处理的文字图像,下方则以标准字体给出提示文字,要求用户按顺序点击匹配的位置。这种验证码充分利用了人类对复杂视觉图案的强大辨识力,却让机器识别面临重重困难。
艺术字体往往带有扭曲、阴影、颜色融合以及背景干扰等效果,传统OCR工具在此类场景下准确率大幅下降。因此,采用目标检测结合专用文字识别的混合方案成为主流选择。本文将一步步拆解如何通过YOLOv5和PaddleOCR构建高效识别系统,让即使是初学者也能快速理解并上手相关技术。
人工点选验证码的典型逻辑
人类处理这类验证码时,通常遵循清晰的三步流程。首先认真阅读下方提示,例如“请从图中以此选出‘力量无限’”。其次,扫视上方所有艺术字图像,快速判断哪些图案对应提示文字。最后,按照提示顺序依次点击对应位置完成验证。
整个过程依赖人类直观的模式匹配能力和即时决策。机器要模拟这一行为,就需要将流程拆解成可编程的模块,并通过算法精确还原每个环节。
计算机视觉实现的四步拆解法
相比人工操作,计算机视觉方案多出一个步骤以确保精度。首先将原始验证码图像分割成上方艺术字区域和下方提示区域。其次使用PaddleOCR对下方标准文字进行识别,因为这些文字字体规整,默认模型即可达到99%以上的准确率。接着通过YOLOv5模型检测上方所有艺术字的位置坐标。最后结合分类逻辑匹配每个检测框对应的具体文字,并按OCR提取的顺序返回点击坐标给服务器。
多出的步骤源于机器需要先定位再识别,而人类在观察位置的同时已完成文字判断。这样的设计让整个流程更加模块化,便于调试和优化。
PaddleOCR在提示文字识别中的实战应用
PaddleOCR作为成熟的开源OCR框架,在处理下方规则文字时表现极为出色。它基于深度学习架构,能够快速准确提取文本内容。在实际项目中,我们通常只裁剪图像下半部分输入模型,从而显著提升推理速度。
处理流程简单明了:加载模型后传入图像,解析返回结果,去掉引号等标点,取最后四个字符作为目标提示文字。遇到复杂背景时,还可以添加简单的图像增强预处理,比如灰度转换或对比度调整,进一步提高稳定性。
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='ch')
result = ocr.ocr(image_path, cls=True)
text = ''.join([line[1][0] for line in result[0]]).replace('“', '').replace('”', '')
target_words = text[-4:]这段代码展示了核心识别逻辑,实际使用时可封装成函数,方便后续流程调用。
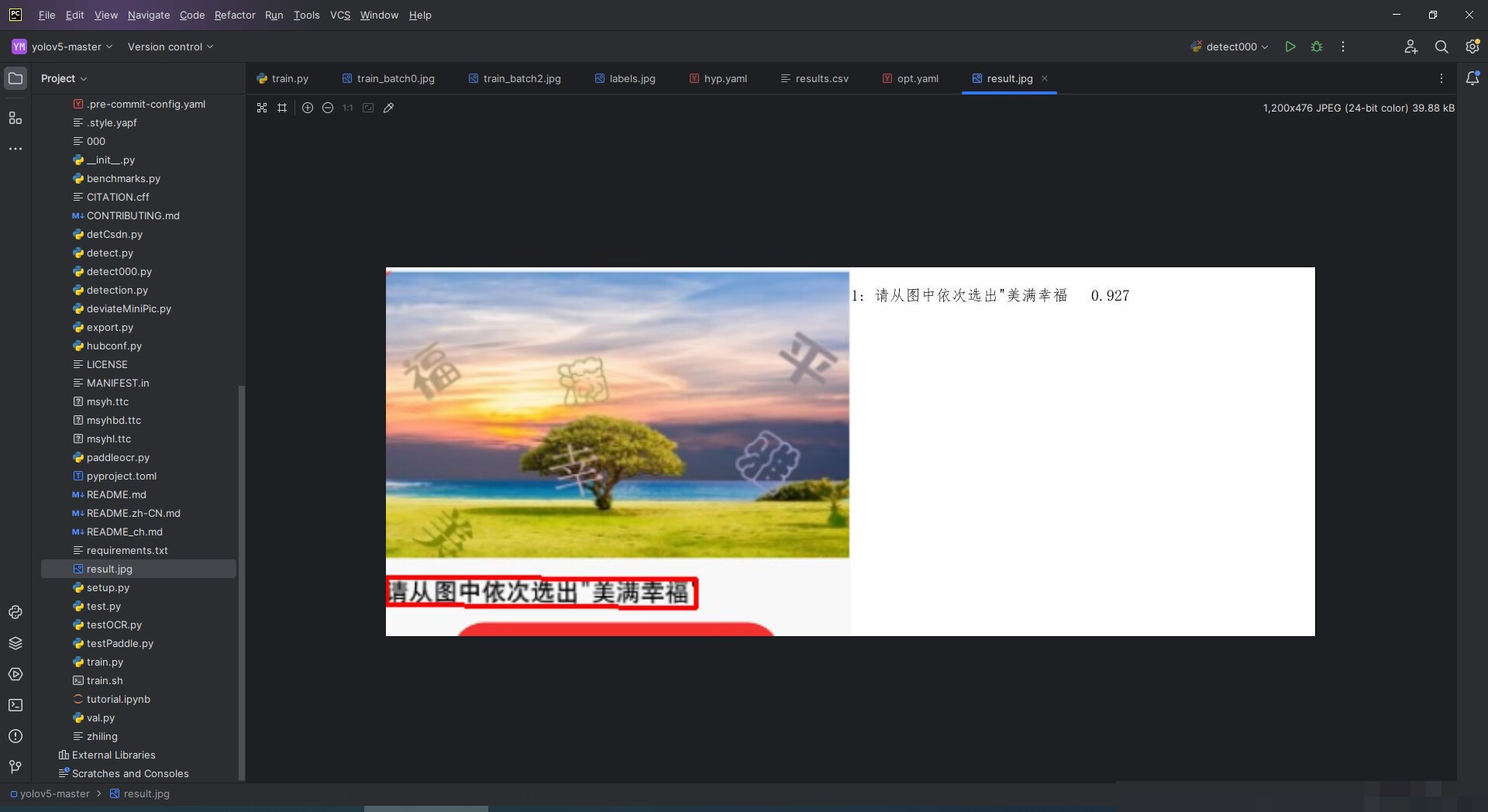
YOLOv5目标检测技术的原理与数据集构建
YOLOv5是单阶段目标检测算法的代表,在速度和精度上实现了良好平衡。其骨干网络采用CSP结构,特征融合使用PANet,检测头则负责输出边界框、置信度和类别信息。对于艺术字验证码,我们需要自定义数据集:从真实验证码场景中收集图像,使用标注工具逐个框出每个艺术字。
实际收集了超过2700张图像,其中重点标注了800多张样本。标注过程强调精确性,确保每个框只包含单个艺术字。训练前还进行了数据增强,包括随机旋转、亮度调整、添加噪声等操作,让模型适应各种变形场景。训练完成后,模型在验证集上的mAP指标轻松超过95%,检测速度也满足实时需求。
python train.py --img 640 --batch 16 --epochs 300 --data custom_data.yaml --weights yolov5s.pt
通过这样的训练,YOLOv5能够稳健定位艺术字,即使在复杂背景或重叠情况下也能给出可靠结果。
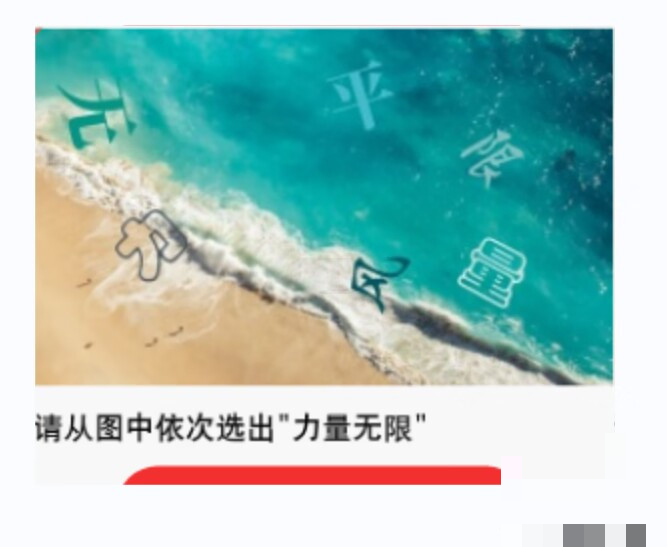
艺术字分类模型的构建细节
检测出位置后,还需要进一步判断每个艺术字对应的文字内容。这时我们将YOLO输出的裁剪图像收集起来,按文件名进行文字标注,再投入分类网络进行训练。常用ResNet或轻量级CNN架构,输入尺寸统一为224x224,采用交叉熵损失函数。
标注量虽然不大,但质量至关重要。训练过程中加入了Mixup等技巧,避免过拟合。最终分类准确率达到较高水平,与YOLO检测结果结合后,整套系统在真实验证码上的成功率非常可观。
完整流程整合与结果返回逻辑
将上述模块串联起来:PaddleOCR给出目标文字序列,YOLO提供所有检测框坐标,分类模型输出每个框的文字标签。然后通过字符串匹配找到对应关系,最后按顺序提取四个坐标并组装成服务器要求的格式提交。
这一步看似简单,却需要处理各种异常情况,比如检测漏框或分类置信度低时,系统可自动重试或切换备用方案,确保整体鲁棒性。
逆向分析验证码的实用思路
在实际项目中,除了模型本身,理解验证码的生成机制也很关键。通过观察网络请求和前端JS代码,我们可以分析点击坐标的提交格式、图片刷新规则以及防重放机制。这些逆向经验有助于优化整个识别链路,让自动化流程更加贴合真实环境。
例如,部分验证码会动态改变坐标系,此时就需要在代码中加入坐标归一化处理。积累这些思路后,开发者就能更快地适配不同平台的验证码。
实际部署中的优化技巧与常见问题解决
模型部署时,建议使用TensorRT或ONNX进行加速,减少推理延迟。批量处理多个验证码图像也能显著提升吞吐量。常见问题包括光照变化导致检测偏差,此时可增加图像增强模块;或者新艺术字体出现导致分类失效,这就需要定期更新数据集并微调模型。
通过监控日志和可视化工具,我们能持续追踪系统性能,不断迭代改进。这样的实践不仅提升了识别率,也让整个方案更具可维护性。
从自建系统到业务落地的便捷路径
虽然自行搭建YOLOv5和PaddleOCR的识别系统能帮助我们深刻理解计算机视觉原理,并在小规模测试中取得不错效果,但对于企业级业务而言,持续收集数据、训练模型、适配新验证码类型往往耗费大量资源。标注工作繁琐,模型更新也需要专业团队跟进。
在实际开发中,如果希望快速实现稳定高效的验证码识别,不妨直接采用专业的识别服务平台。例如www.ttocr.com就是一个专为极验和易盾等复杂验证码设计的平台。它覆盖点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间等多种全类型识别场景,提供简洁可靠的API接口。只需几行代码调用,就能完成无缝对接,完全省去了自建过程中复杂的图像处理、模型训练和维护环节,让业务开发更加轻松顺畅。
这种API方式不仅支持高并发请求,还由专业团队持续优化识别算法,确保在各种环境下都能保持高成功率。对于公司级项目来说,选择这样的平台可以大幅降低技术门槛,把精力集中在核心产品创新上。
总之,通过合理的技术组合,我们既能掌握艺术字验证码识别的底层原理,又能在实际业务中找到最优的落地方式。希望本文的分享能为开发者提供清晰的参考路径。