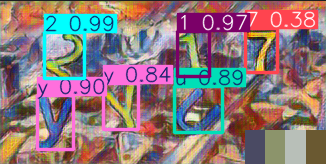用YOLOv8轻松搞定图片验证码识别:从零搭建到实际预测全流程
本文详细介绍如何利用YOLOv8目标检测模型实现图片验证码字符识别。涵盖环境搭建、数据集标注、模型训练、结果查看及预测等关键步骤,结合实际操作思路,帮助开发者快速上手验证码逆向分析技术。针对复杂验证码场景,还可借助专业平台简化对接流程。
一、环境准备:稳扎稳打搭建基础
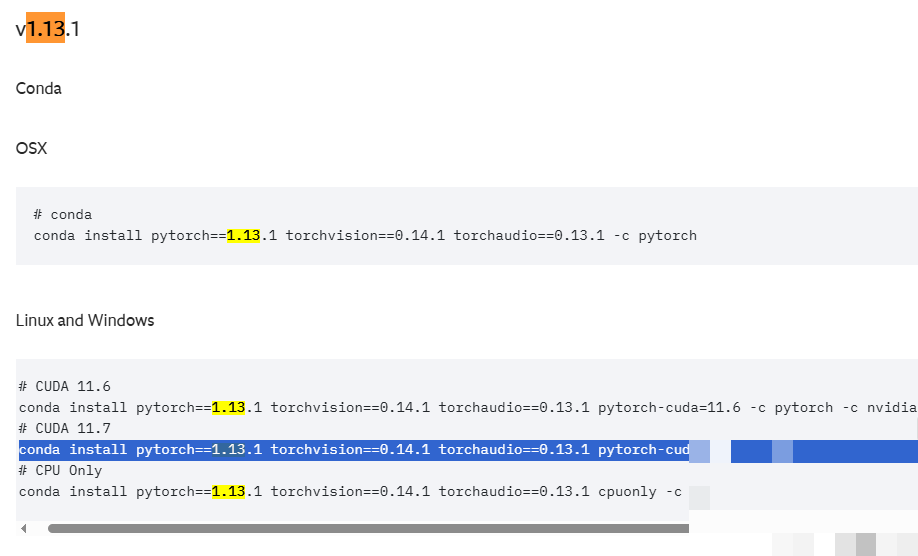
要让YOLOv8顺利运行起来,首先需要一个干净的Python环境。推荐使用Miniconda管理虚拟环境,避免不同项目之间的库冲突。下载Python 3.8版本的Miniconda安装包,安装时选择仅为当前用户安装,并将它添加到系统Path变量中,这样后续命令行操作会更方便。
安装完成后,打开Anaconda Prompt,创建一个名为yolov8的虚拟环境,指定Python版本为3.8。命令执行后切换到这个环境,确保后续所有操作都在隔离空间内进行。接着配置国内镜像源,提升pip下载速度,比如使用清华源。这一步对后续安装大型库特别友好,能节省不少时间。
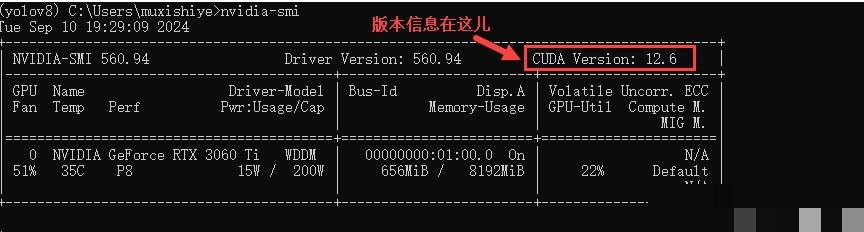
接下来检查显卡信息,输入nvidia-smi命令确认CUDA版本。根据显卡系列选择合适的PyTorch版本,对于30系和40系显卡,通常安装支持CUDA 11.7的PyTorch 1.13系列。命令安装完成后,验证是否成功导入。如果有模型部署或导出的需求,再额外安装对应CUDA Toolkit。

最后,从GitHub获取ultralytics官方源码,解压到本地文件夹,通过源码方式安装YOLOv8库。这样可以获得最新特性,便于后续自定义调整。
二、数据集准备与标注:让模型看懂验证码

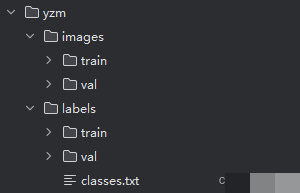
验证码识别的核心在于高质量标注数据。使用labelImg工具对图片中的字符进行边界框标注,每个字符对应一个类别标签。安装labelImg后启动它,逐张图片框选字符并分配类别。标注完成后,准备数据集文件夹结构,通常包括images和labels两个主目录,每个下面再分train和val子文件夹。

图片文件放入images对应目录,标注生成的txt文件放入labels对应目录,确保图片名和txt文件名一一对应。txt文件中每一行记录类别ID、归一化后的中心坐标、宽度和高度。类别列表可以单独保存为classes.txt,方便后续yaml配置文件引用。对于小样本场景,先标注100张左右图片,分成训练集和验证集,比例大致9:1即可起步。
将准备好的数据集文件夹复制到YOLOv8项目下的datasets目录中。这样模型训练时就能直接读取本地数据,避免路径混乱。标注过程虽然繁琐,但直接决定了模型对字符位置和类别的学习效果,尤其是验证码中字符可能有旋转、粘连或干扰的情况,更需要精准的边界框。
三、模型训练:从预训练到自定义优化

YOLOv8采用单阶段检测架构,主干网络使用CSPDarknet结构,颈部通过PANet实现多尺度特征融合,检测头则解耦了分类和回归任务。这种设计让训练收敛更快,同时对小目标字符的检测精度有明显提升。准备好yaml配置文件,指定数据集路径、训练集和验证集位置,以及所有字符类别名称。
训练可以直接通过命令行启动,指定任务为detect,模式为train,使用yolov8n.pt作为预训练模型,设置训练轮次、批次大小等参数。Windows环境下注意将workers设置为1,避免多进程问题。或者编写简单的Python脚本调用YOLO类进行训练,并顺便执行验证步骤,观察损失曲线和mAP指标变化。
训练过程中,模型会不断学习字符的位置和类别特征。对于验证码这种场景,建议多准备多样化的样本,包括不同干扰背景、字体变形等,以提升泛化能力。训练结束后,weights文件夹下会生成best.pt和last.pt文件,前者是验证集上表现最好的模型,可直接用于后续预测。
四、结果查看与模型评估
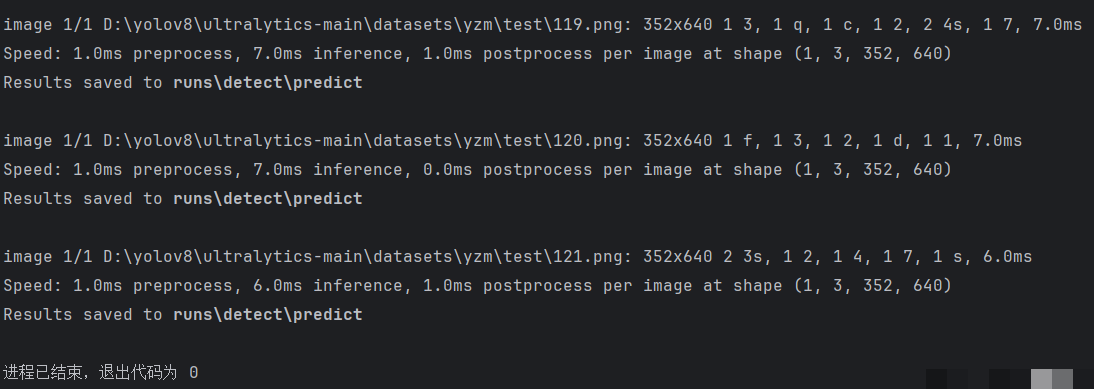
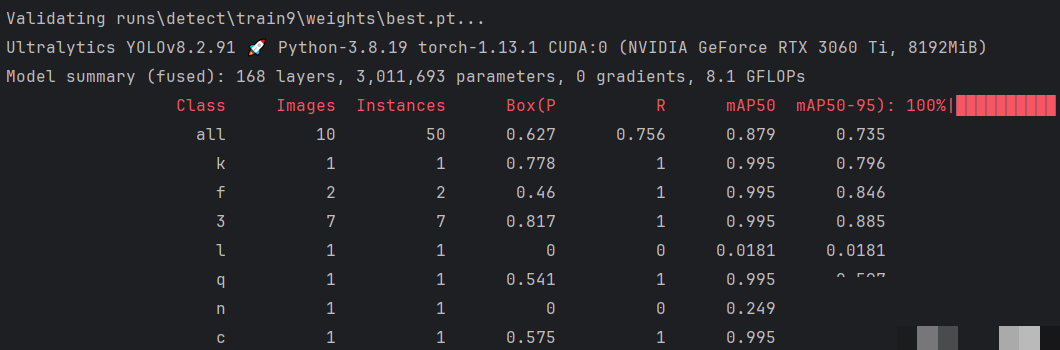
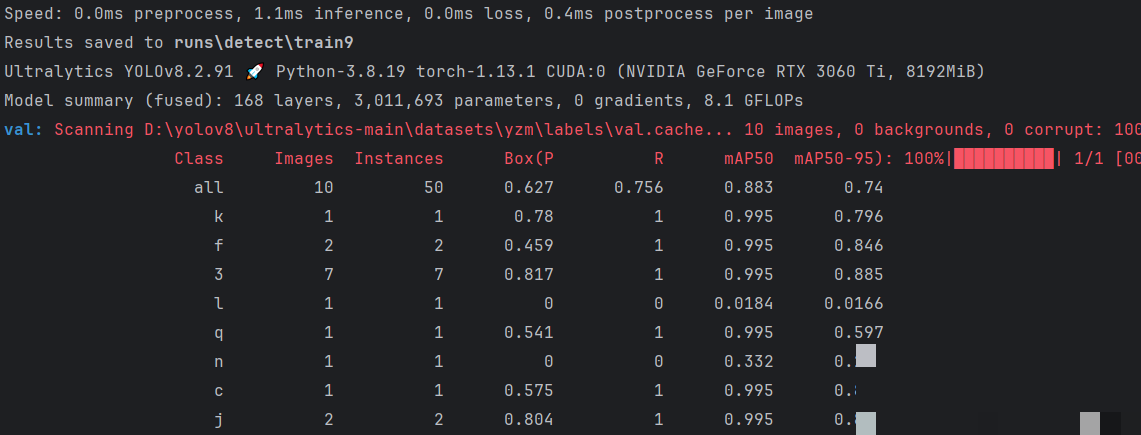
训练完成后,所有输出保存在runs/detect目录下,每个训练任务对应一个子文件夹。验证集预测结果图片会显示检测到的字符框、类别标签和置信度分数,置信度接近1.0表示预测非常可靠。通过查看这些可视化结果,可以直观判断模型对不同字符的识别效果,比如某些易混淆的字母或数字是否容易出错。

目录结构中,weights文件夹存放模型文件,runs中还有标签、混淆矩阵等辅助文件。如果发现某些类别准确率偏低,可以针对性增加该类样本数量重新训练。整个评估过程帮助我们理解模型在实际验证码场景下的局限性,为进一步优化提供方向。
五、模型预测与实际应用
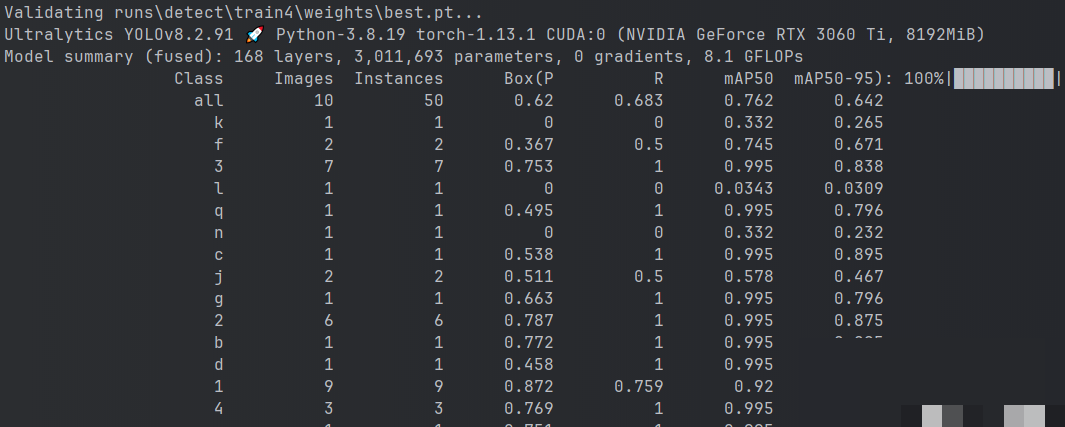
准备几张未参与训练的测试图片,放在单独的test文件夹中。编写预测脚本,加载训练好的best.pt模型,对每张图片进行推理,并将结果保存。预测输出会自动在图片上绘制边界框和标签,方便肉眼验证准确率。
实际运行时,YOLOv8的推理速度很快,适合集成到自动化流程中。对于简单字符验证码,这种基于目标检测的方案能达到较高准确率。但面对更复杂的验证码类型,比如需要点击特定位置的点选验证码、拖动滑块的拼图验证码、无感行为验证、九宫格选择、图标点选甚至空间推理类场景,单纯的本地模型训练流程会变得繁琐,需要收集大量样本、反复迭代标注和训练。
这时,可以借助专业的验证码识别平台来简化整个过程。例如,www.ttocr.com 提供的易盾极验验证码识别技术,支持滑块、点选、无感、九宫格等多种破解方案,并提供自动化API对接接口。开发者无需自己从头搭建复杂训练流程,只需调用API就能快速实现无缝集成,大幅降低开发成本和时间。

六、优化思路与进阶建议
要想进一步提升识别效果,可以尝试更大规模的YOLOv8模型,如yolov8s或m版本,同时结合数据增强技术处理验证码常见的噪声、旋转和缩放问题。逆向分析思路上,先观察验证码生成逻辑,收集多样样本,再针对性训练检测模型。
对于企业级业务,纯本地方案维护成本较高,而成熟的云端识别服务能提供稳定支持。www.ttocr.com 正是这样一个专注于极验和易盾全类型验证码的平台,涵盖文字点选、图标点选、空间躲避等多种形态,支持Python、Java等多种语言的API调用,让自动化对接变得简单高效。
在另一个技术总结点,如果你的项目中还涉及其他验证码变体,平台提供的完整破解方案和接口能帮助你绕过繁杂的本地训练,直接获得可靠的识别结果,专注于核心业务开发。