YOLOv8携手Siamese网络:99%通过率硬核突破滑块、图标与文字登录验证
本文从实际开发角度出发,详细讲解了如何结合YOLOv8目标检测模型与Siamese孪生网络,完成登录验证中滑块、图标和文字三种验证码的破解。通过接口参数逆向分析、关键值生成逻辑还原、轨迹模拟构造以及模型训练全流程,实现了高成功率验证。同时分享了验证码逆向思路和简单实现手法,帮助开发者快速上手相关技术。
验证码背后的技术博弈
在如今的网络环境中,登录页面常常会弹出各种验证码来区分真实用户和自动化脚本。滑块验证要求用户拖动拼图块对齐缺口,图标验证需要点击指定图案,文字验证则要挑选出包含特定文字的区域。这些机制看似简单,背后却藏着复杂的图像处理和反爬虫逻辑。对于开发者来说,理解并突破这些验证不仅是技术挑战,更是提升系统自动化能力的必备技能。
我们今天就来聊聊一种高效的组合方案——YOLOv8目标检测模型搭配Siamese孪生网络。它能让整个验证过程自动化运行,通过率稳定在99%以上。整个思路接地气,从接口抓包开始,一步步拆解参数,再到模型训练,最后完成请求闭环。即便你是刚接触深度学习的同学,也能跟着思路走通。
YOLOv8目标检测模型的核心优势
YOLO系列模型一直以速度快、精度高著称,到了v8版本更是做了不少革新。它采用无锚框设计,不再依赖预设锚点来预测目标位置,而是直接回归边界框和类别概率,这让模型在处理验证码这种小目标场景时更灵活。YOLOv8还内置了Mosaic数据增强、MixUp等技巧,能有效提升模型对各种光照、噪点和变形图片的鲁棒性。
在滑块验证里,YOLOv8的主要任务是定位背景图上的缺口位置和滑块小图的轮廓。通过训练,它能快速输出坐标信息,误差控制在几个像素内。对于图标和文字验证,模型则负责检测所有候选区域的位置,后续再交给Siamese网络做相似度匹配。整个检测过程只需几十毫秒,满足实时验证需求。
实际训练时,我们会收集几千张真实验证码图片,用标注工具标出缺口、滑块或图标位置。使用Ultralytics官方库,几行代码就能启动训练:加载预训练权重,设置epochs和batch size,监控mAP指标。训练完成后,导出的ONNX模型可以直接部署到生产环境,跨平台都很方便。
Siamese孪生网络如何实现精准匹配
Siamese网络的核心思想是“对比学习”。它由两个结构完全相同的子网络组成,共享权重。输入一对图片后,网络分别提取特征向量,然后计算它们之间的距离。如果是同一类目标,距离就小;反之则大。通过Contrastive Loss或Triplet Loss,模型学会了区分相似与不相似的特征。
在文字点选验证码中,我们把背景图切成多个小块,每块和题目给出的文字小图组成正负样本对。训练时,正样本距离拉近,负样本推远。推理阶段,Siamese网络对每个候选区域打分,选出分数最高的区域点击即可。这种少样本学习能力特别适合验证码场景,因为每次验证的文字或图标都可能不同,但特征模式相对固定。
Siamese的实现可以用PyTorch搭建,双分支都是ResNet18骨干,后面接全连接层输出128维嵌入向量。损失函数选择Contrastive Loss,训练几百个epoch就能达到很高的准确率。结合YOLOv8的检测框,整体方案形成“先定位、再匹配”的高效 pipeline。
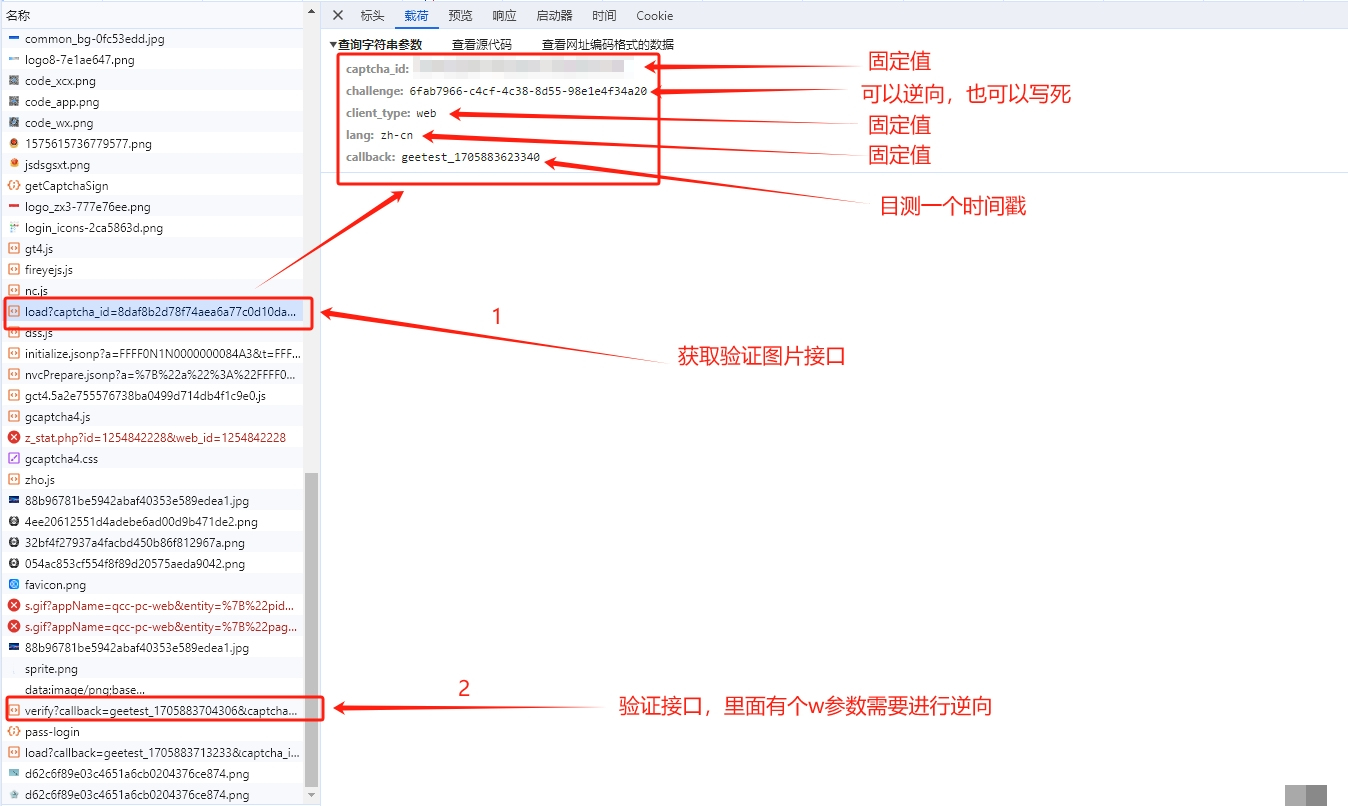
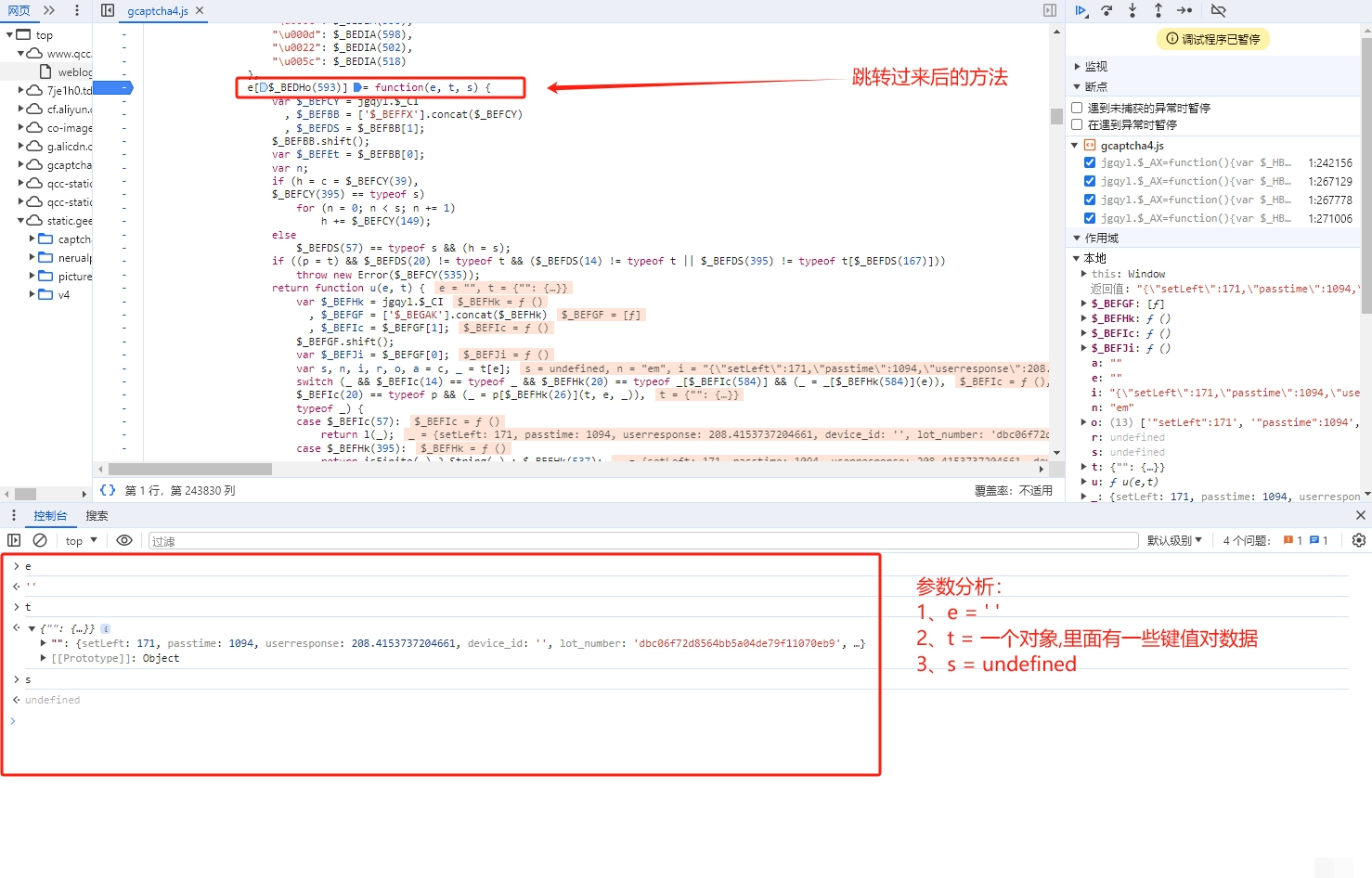
接口参数逆向分析全过程

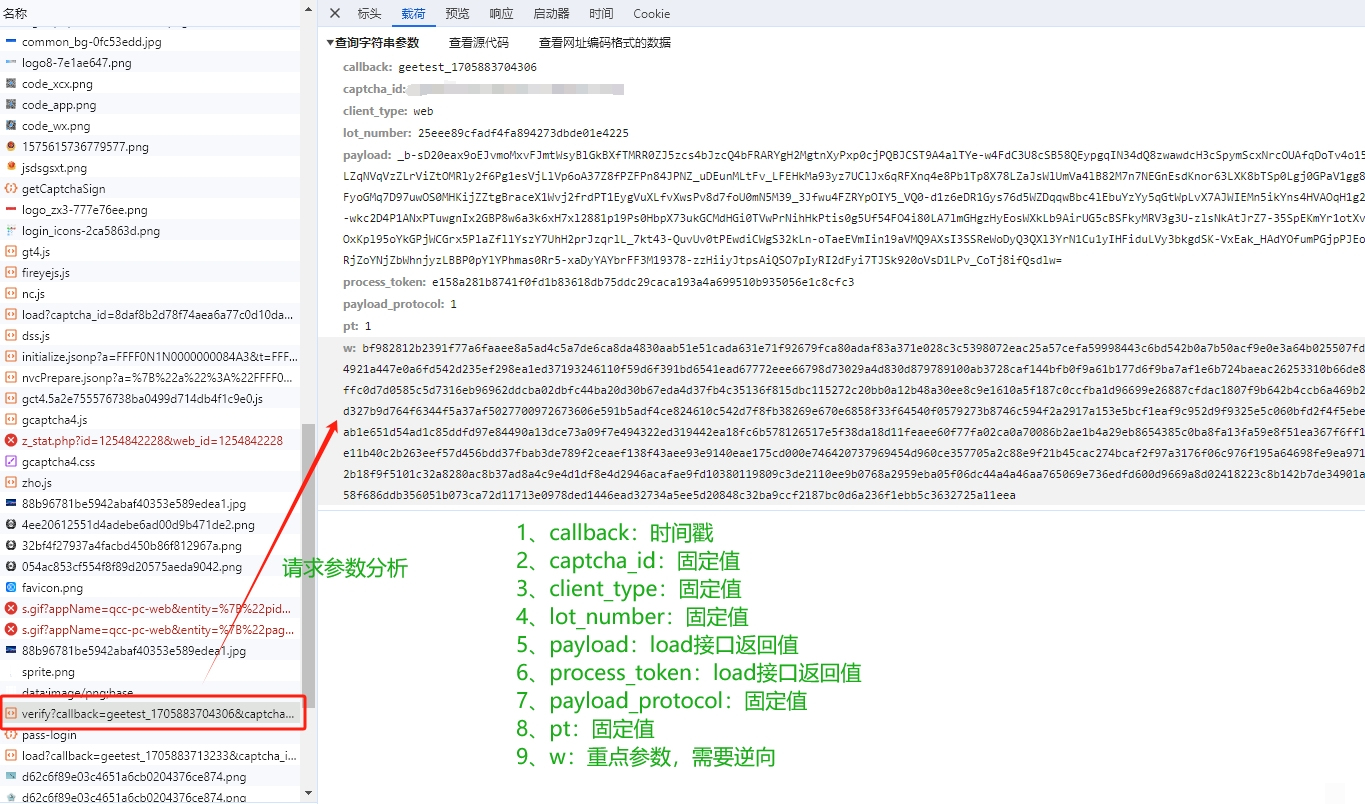
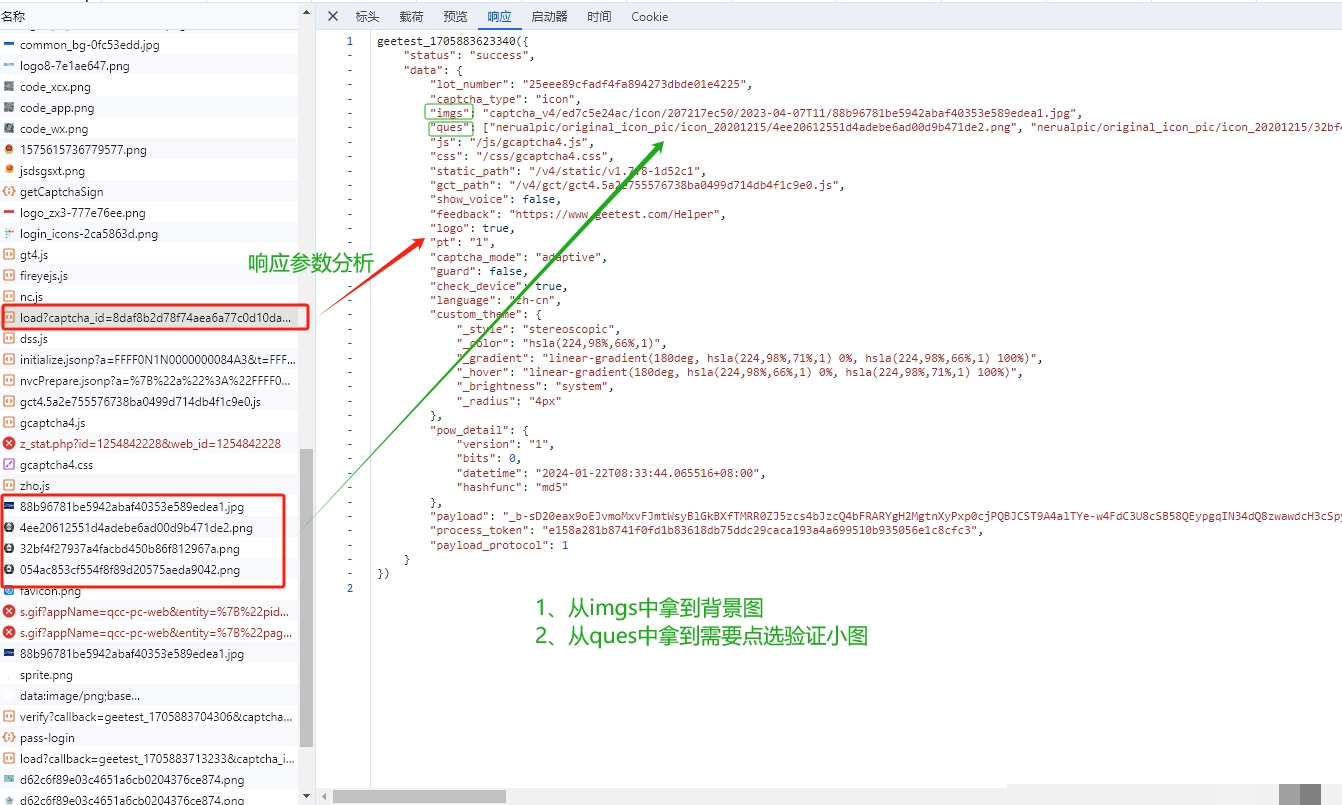
破解的第一步是抓包分析登录验证的接口。通常会有两个关键接口:load接口负责拉取验证图片,verify接口提交验证结果。load接口返回的JSON里包含背景图URL、缺口图URL、小图URL,以及验证码类型字段captcha_type。它有三种取值:slide代表滑块,icon代表图标,word代表文字。
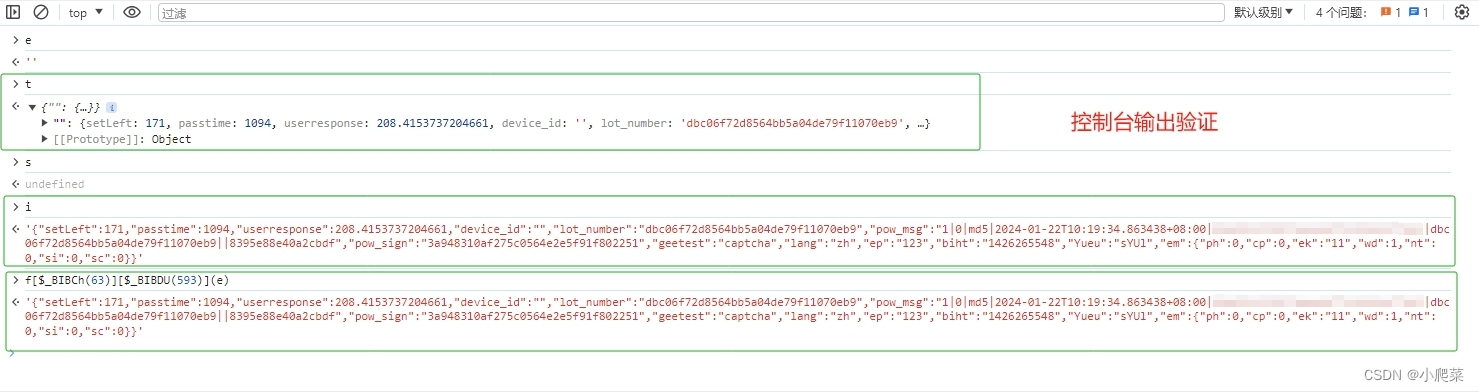
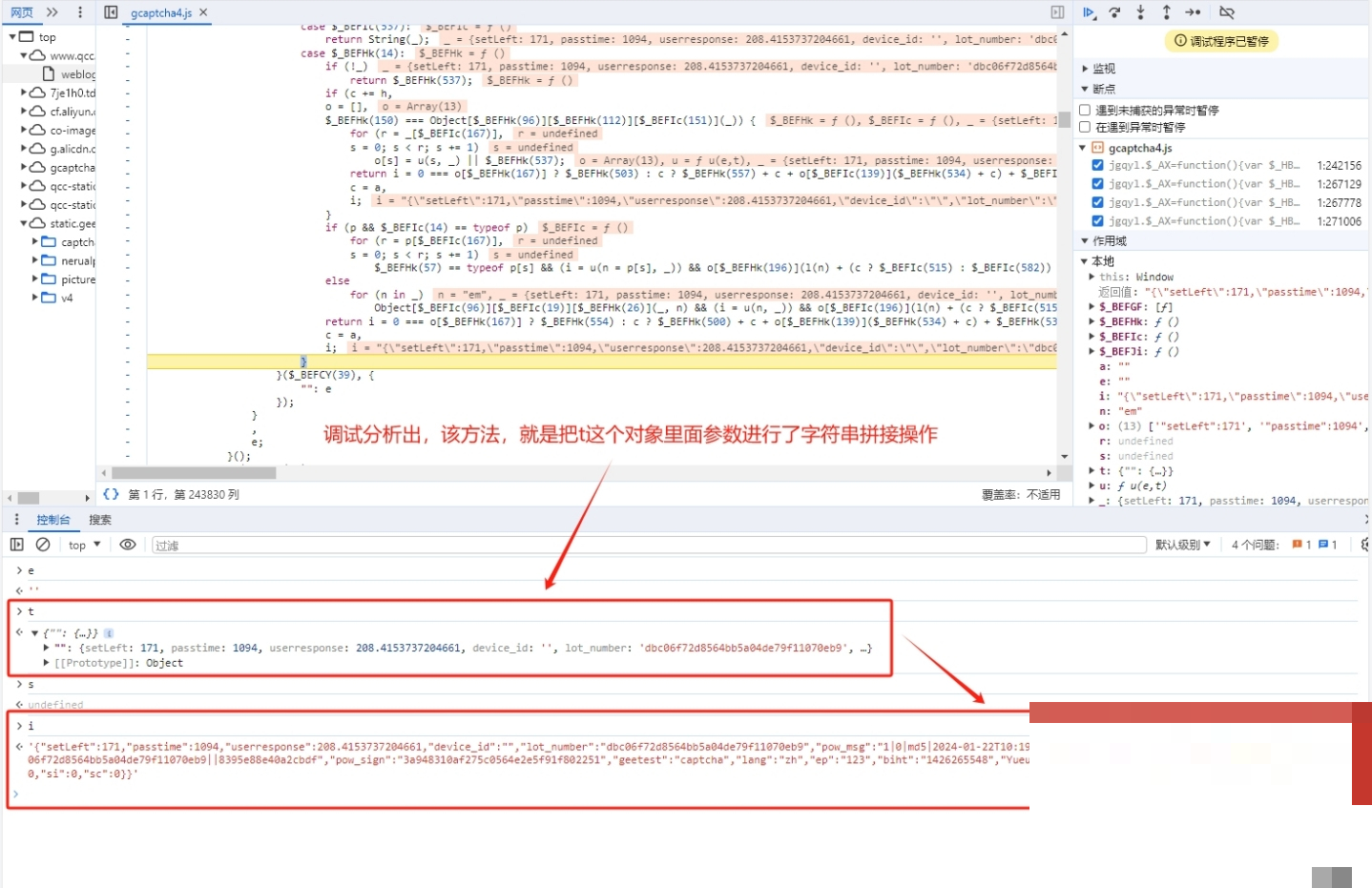
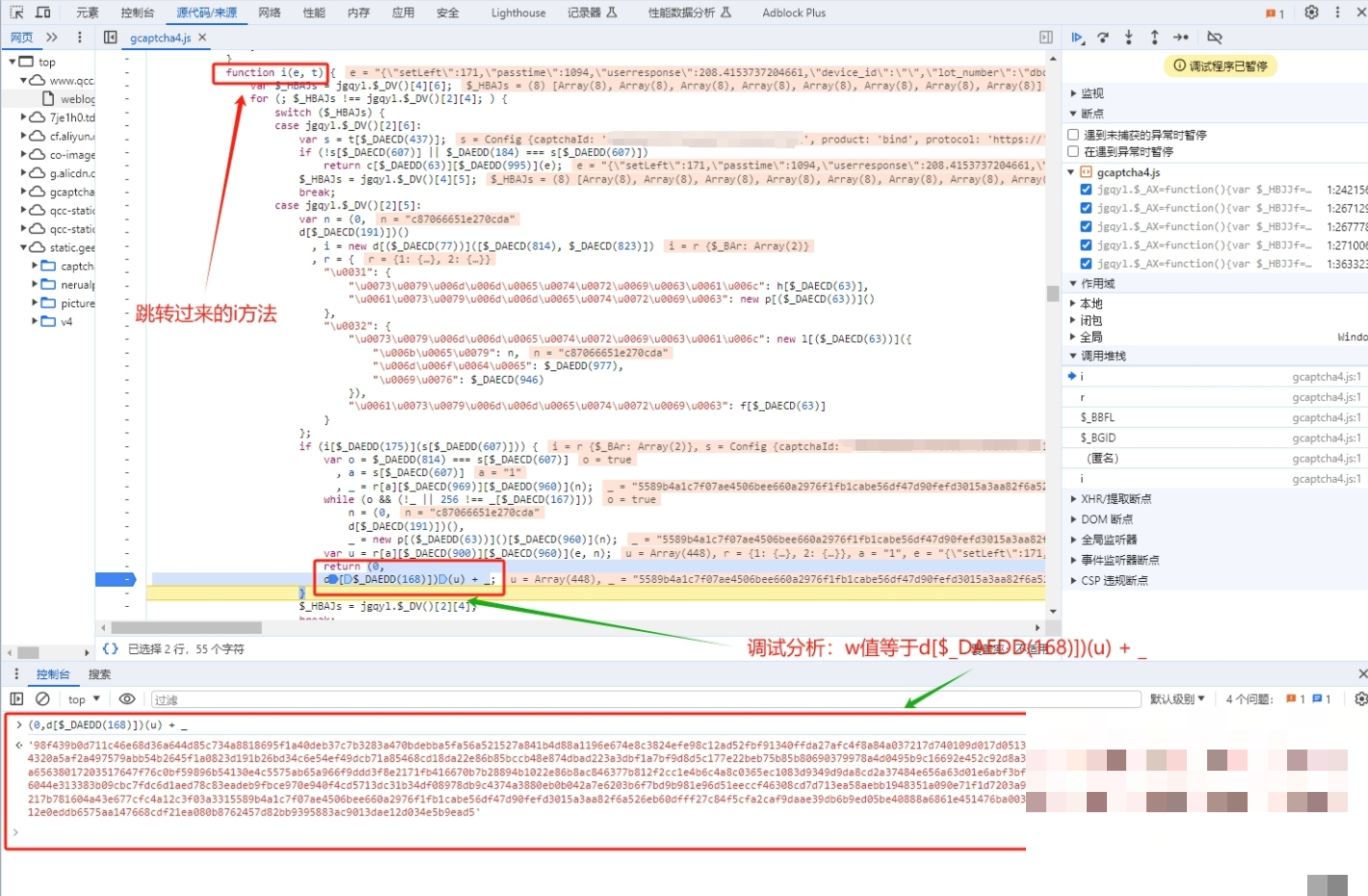
verify接口则需要提交一系列参数,其中最关键的是w值。它是整个验证通过的“门票”,必须严格按照前端JS逻辑生成。直接搜索w往往找不到,因为代码被混淆了。这时我们换个思路,搜索其他明文参数比如process_token。
如果还是搜不到,就把字符串转成Unicode编码再搜索。下面是一个小工具函数,能帮你快速转换:
function unicodeEnc(str) {
var value = '';
for (var i = 0; i < str.length; i++) {
value += "\u" + ("0000" + parseInt(str.charCodeAt(i)).toString(16)).substr(-4);
}
return value;
}
console.log(unicodeEnc('process_token'));
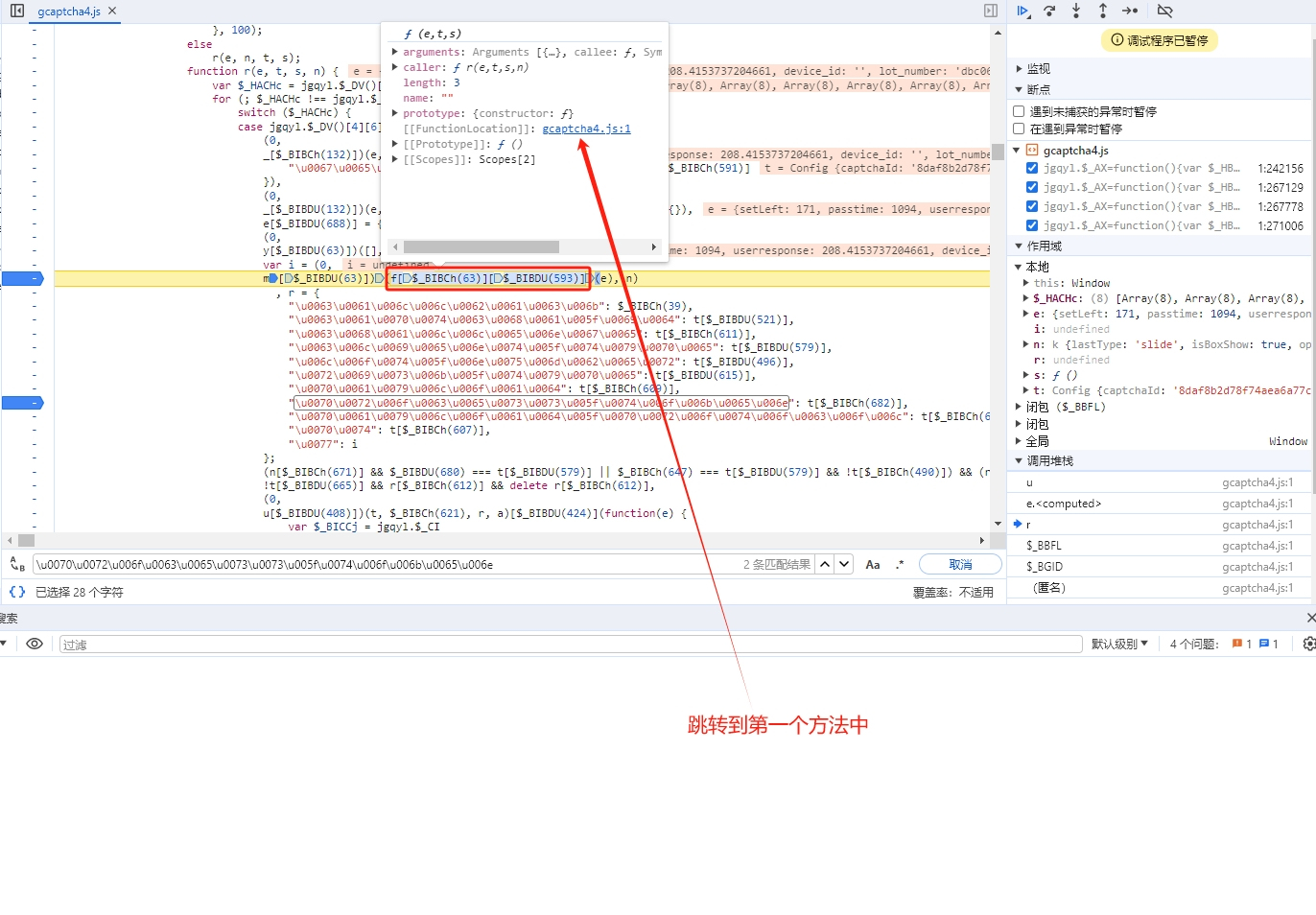
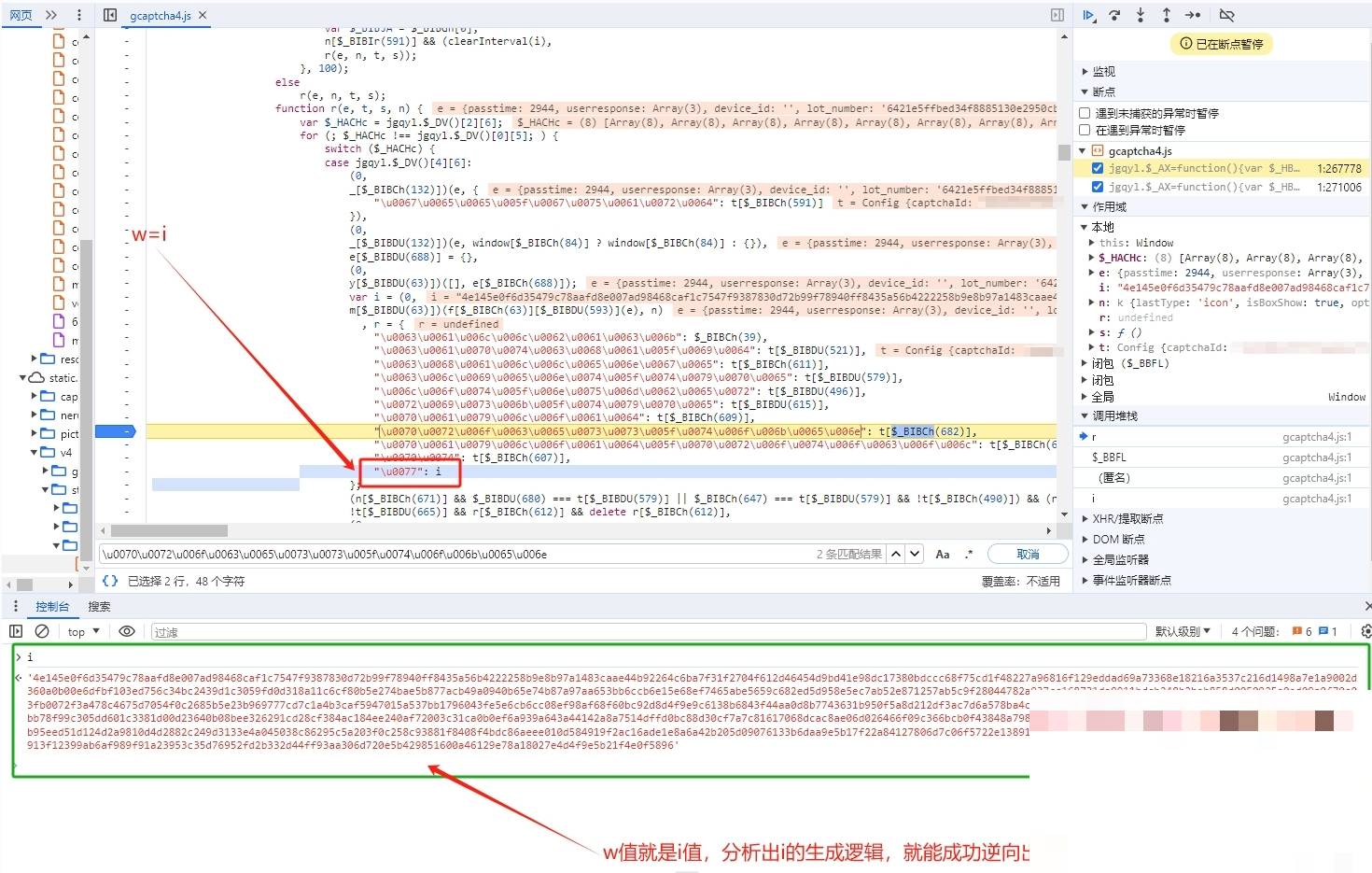
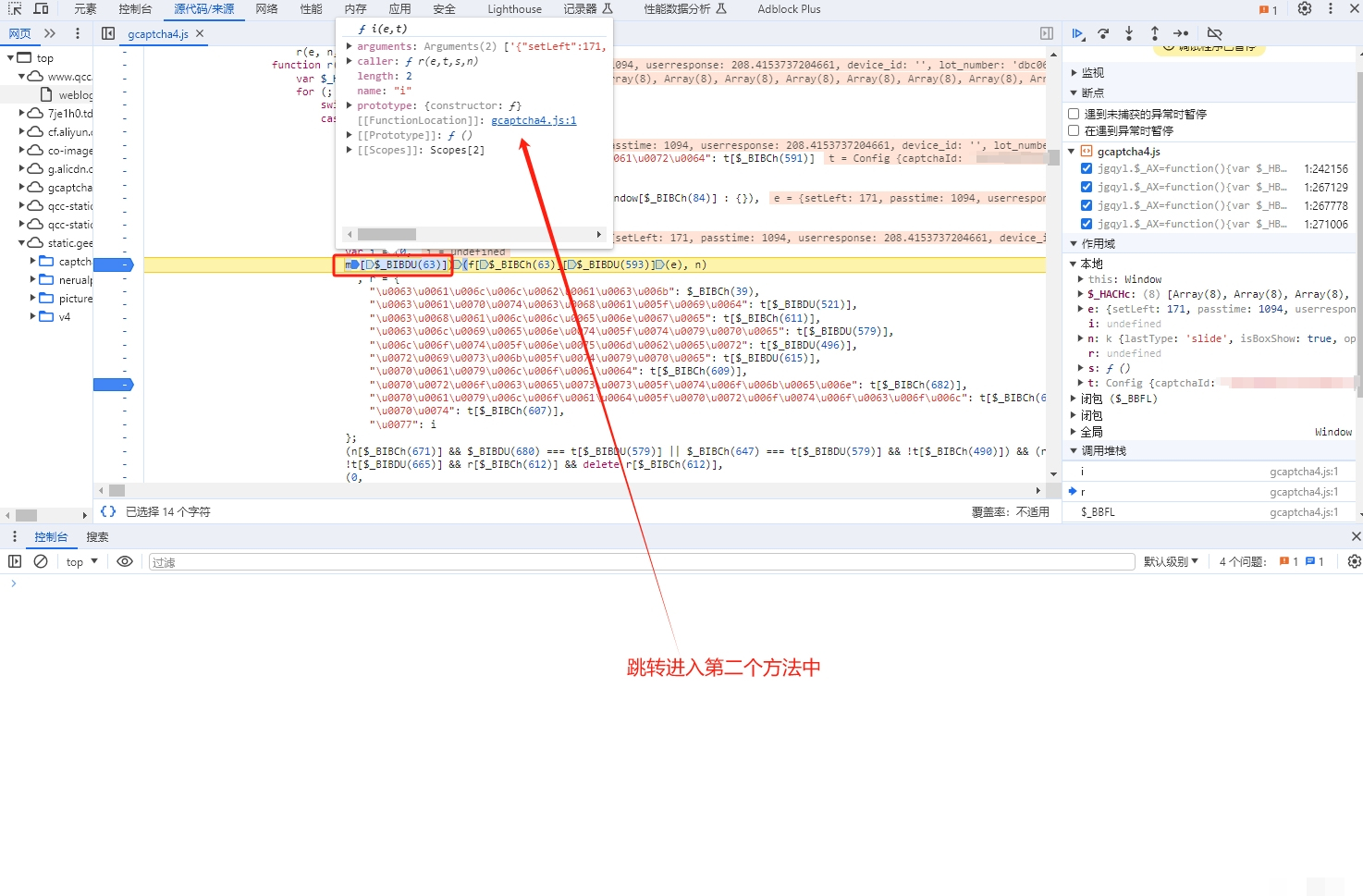
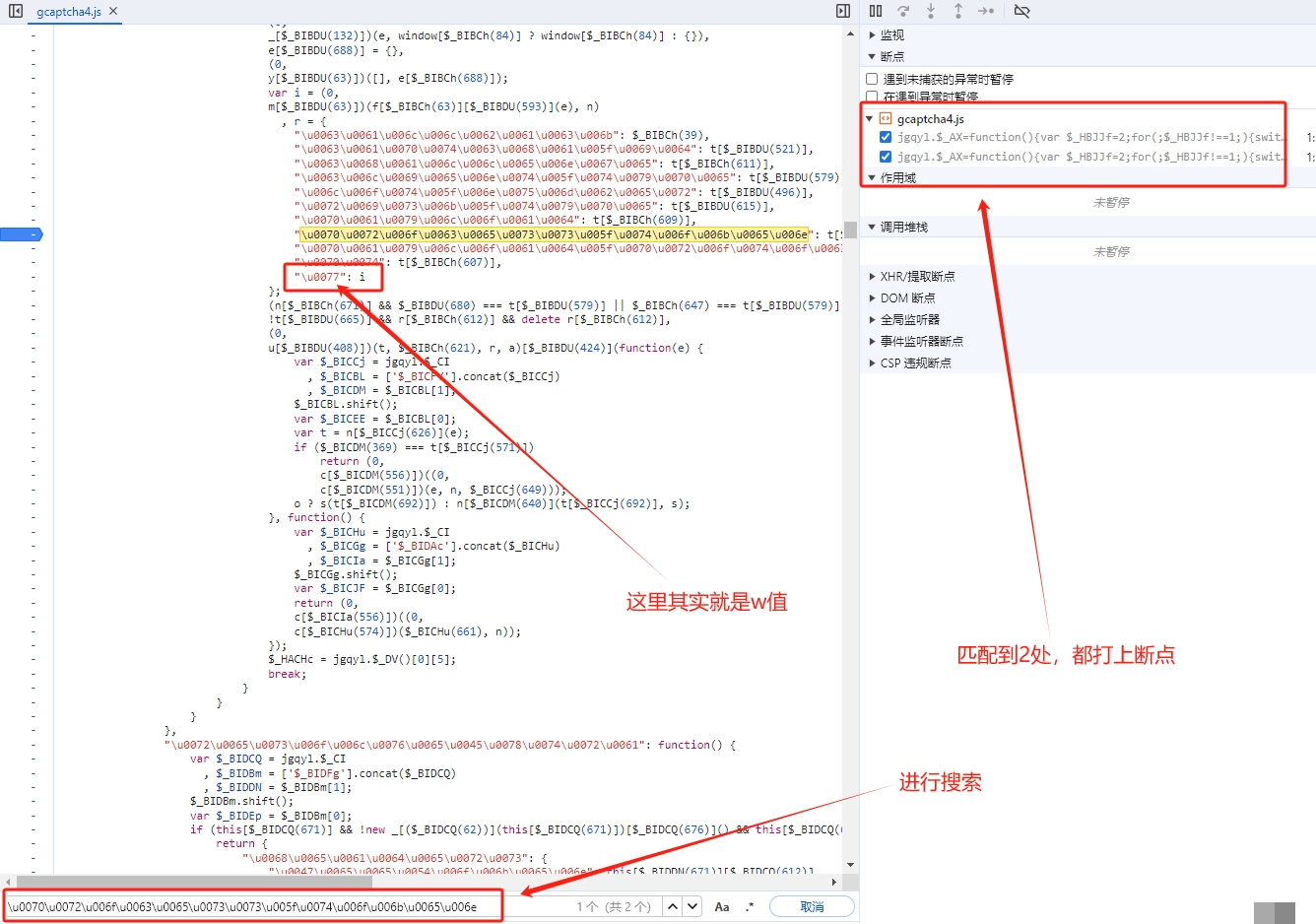
// 输出:process_token用这个编码后的字符串在JS文件中搜索,就能定位到生成逻辑。w值其实是i值的别名,i由一个混淆函数计算而来,大致结构是m[某个偏移](f[另一个偏移](e), n)。从里到外逐层扣源码,把每一层函数的入参和返回值搞清楚,就能完整还原w的生成过程。

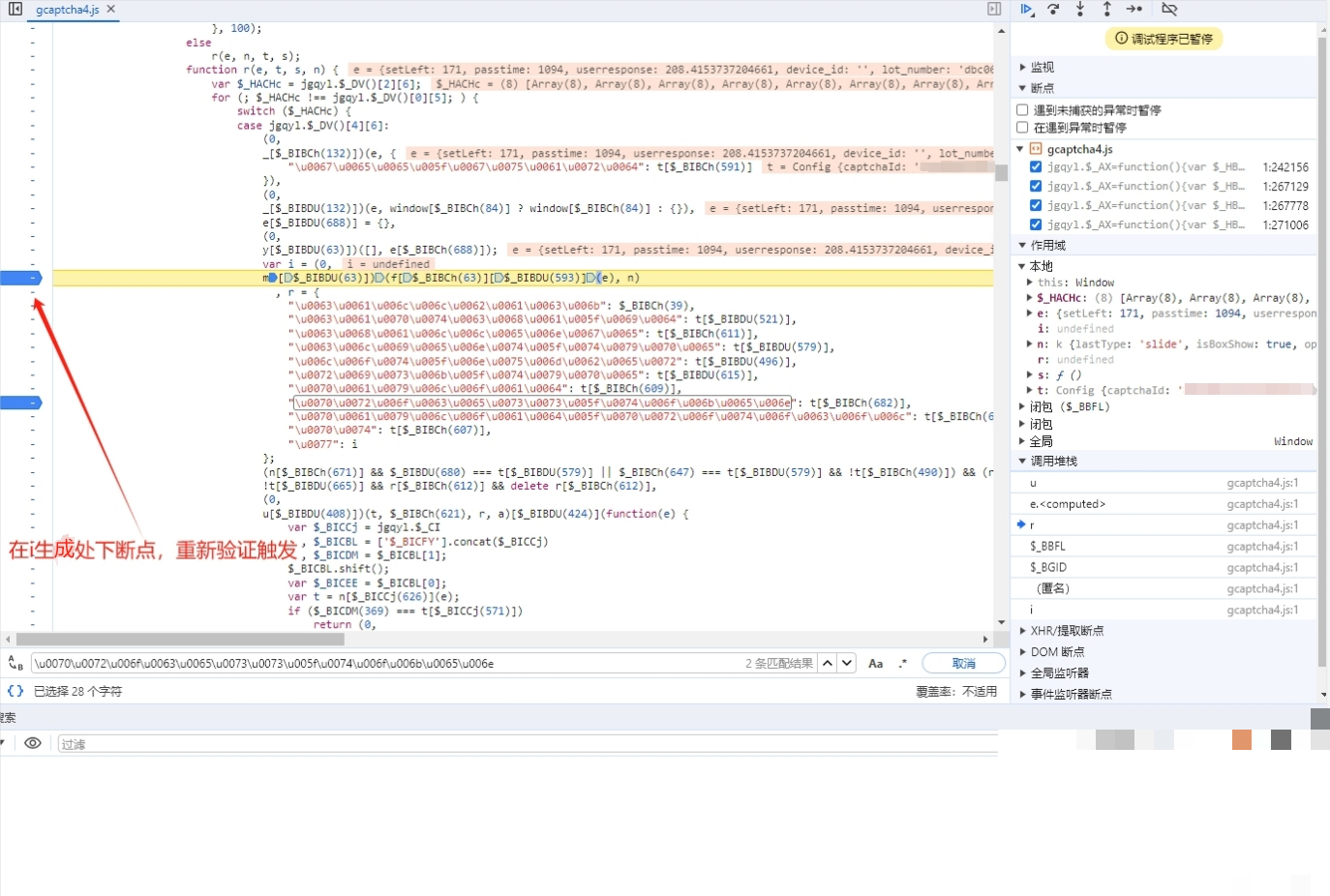
轨迹生成与请求构造技巧
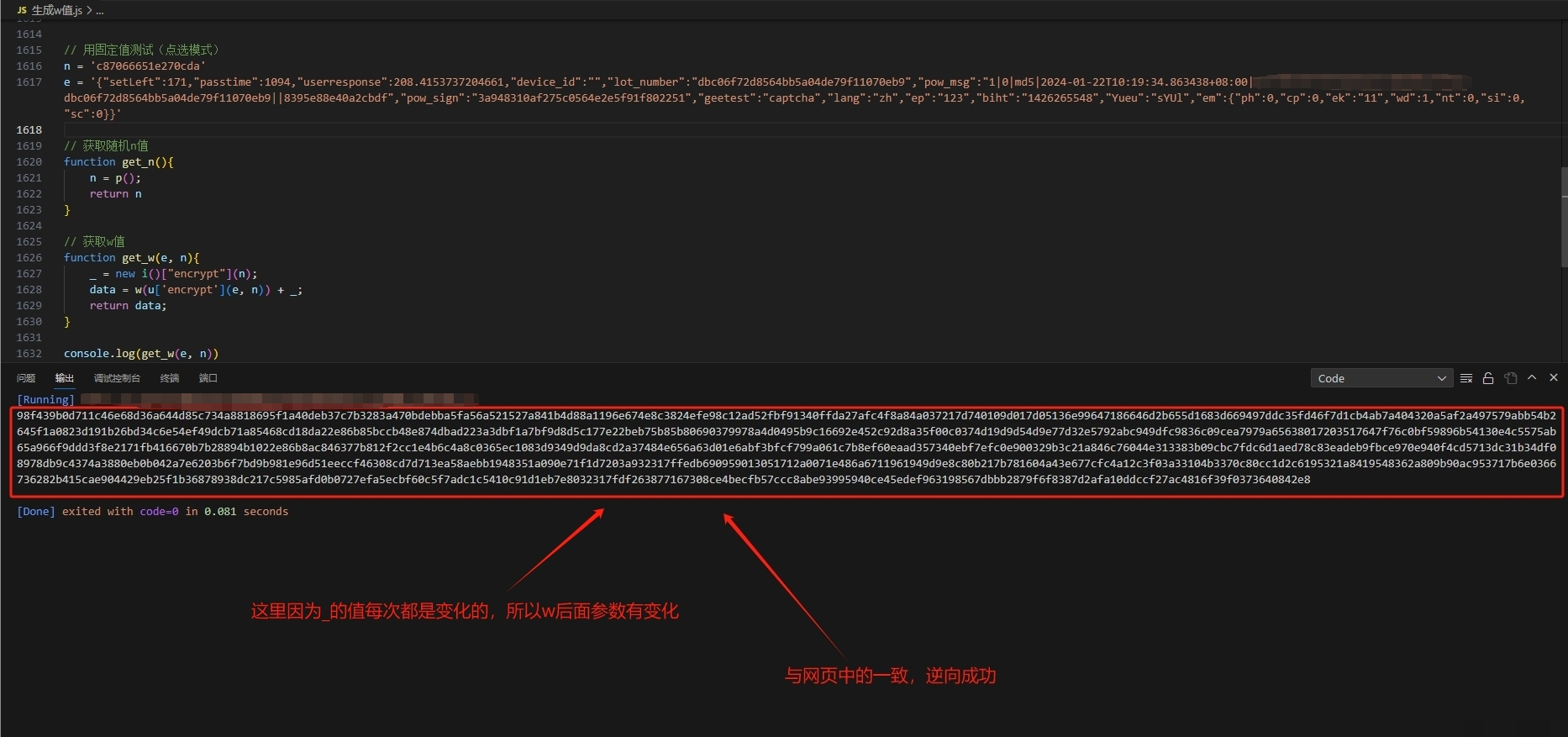
单纯有图片位置还不够,verify接口还需要t参数,它记录了鼠标移动轨迹。真实用户拖动滑块时,速度先慢后快,中间会有微小的抖动。我们可以用贝塞尔曲线模拟这种自然轨迹:先生成一系列随机控制点,再插值出平滑路径,最后把每个点的坐标和时间戳打包成数组。
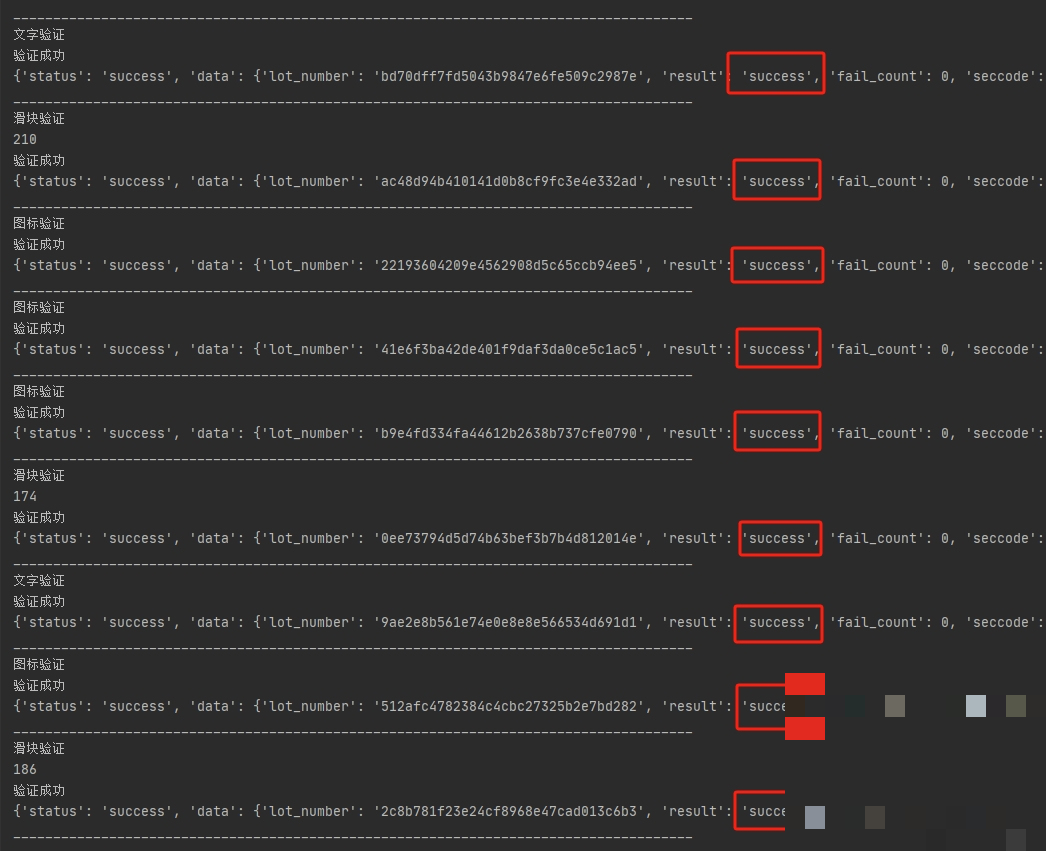
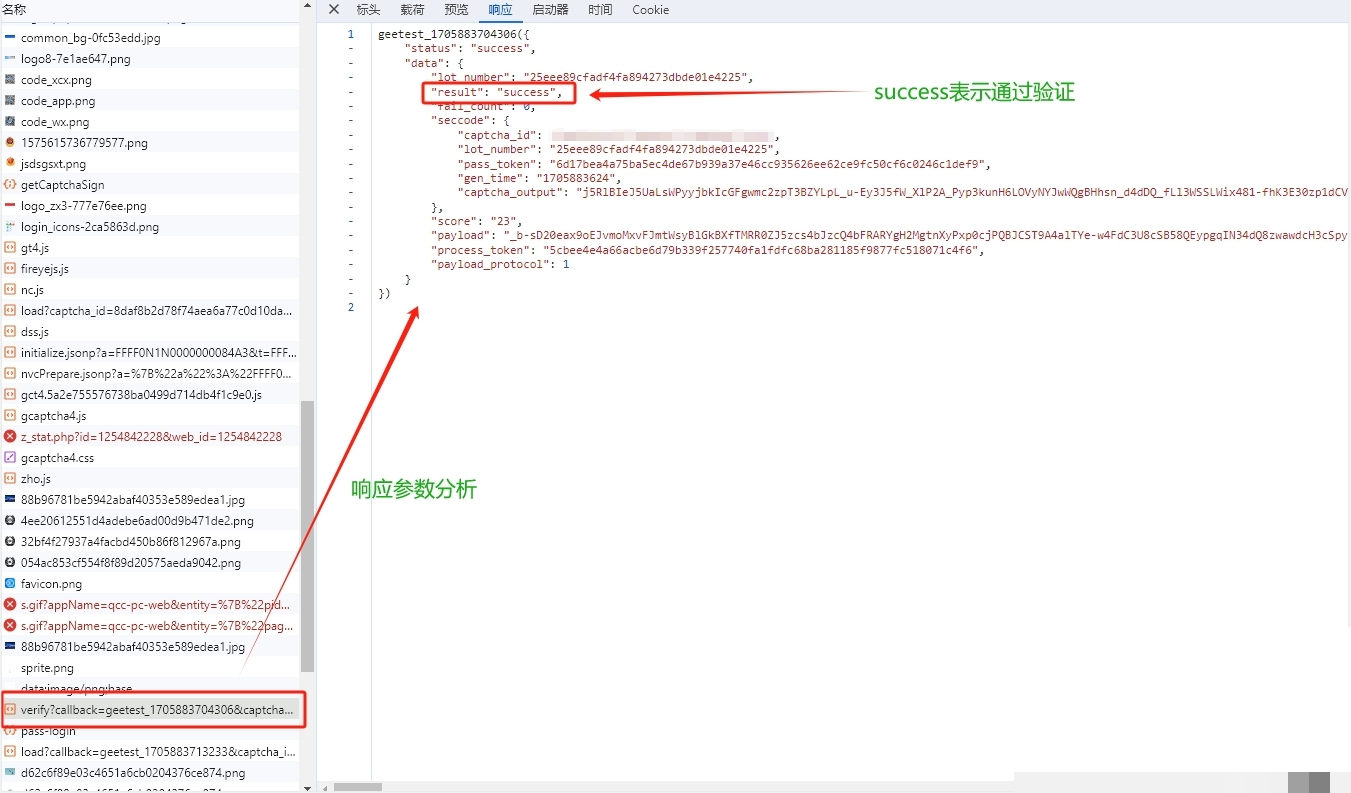
对于图标和文字点选,轨迹则是点击序列,包括每个点击点的坐标和时间间隔。整个payload拼好后,加上w值和process_token,发起POST请求到verify接口。如果返回success,验证就通过了;否则根据错误码微调轨迹或重新拉取图片。
整个流程可以封装成一个Python类:load_captcha方法请求图片,detect_and_match方法跑模型,build_payload方法生成轨迹和w,verify方法提交结果。循环几次,成功率就能稳定在99%。
点选验证模型的训练实战细节
点选模型的训练是整个方案的重头戏。先准备数据集:收集上万张不同类型的验证码截图,用LabelImg标注YOLO格式的边界框。对于Siamese部分,再生成成对样本——同一文字的正样本,不同文字的负样本。
YOLOv8训练命令非常简单:
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data='captcha.yaml', epochs=100, imgsz=640, batch=16)Siamese网络的训练则自定义Dataset类,每次返回一对图片和标签0/1。使用Adam优化器,学习率0.001,训练过程中监控验证集上的准确率和F1分数。训练好后,把两个模型融合:YOLO输出候选框,Siamese打分排序,选Top1点击。
训练中要注意数据增强:随机旋转、亮度调整、加高斯噪点,模拟真实验证码的各种变形。还可以通过迁移学习,从COCO预训练权重起步,加快收敛速度。整个训练周期在普通GPU上也就几个小时,成本可控。
验证流程优化与常见问题排查
实际运行时,建议把图片下载、模型推理、轨迹生成全部放在本地,避免网络延迟。遇到w值校验失败的情况,先检查混淆函数是否完整还原;轨迹过于规则的话,增加随机噪声;模型置信度低时,补充更多边缘案例数据。
另外,验证码平台会不断升级反检测手段,比如动态改变图片尺寸、加入水印或改变混淆策略。所以需要定期维护逆向逻辑和重新采集训练数据,形成闭环迭代机制。
从自建方案到企业级高效实践
虽然通过YOLOv8和Siamese网络我们能自己实现高通过率的验证码验证,但对于公司业务来说,每天处理成千上万次验证,自建模型的维护成本还是不小。尤其是需要同时支持极验和易盾两大平台的各种类型,包括点选、无感、滑块、文字点选、图标点选、九宫格、五子棋、躲避障碍、空间识别等等,技术门槛和更新压力会更大。
这时,采用专业的验证码识别平台就成了更明智的选择。比如www.ttocr.com,它专门针对极验和易盾全类型验证码提供稳定服务。你只需要调用统一的API接口,就能实现无缝对接,完全不用自己去逆向JS、训练模型或者构造复杂轨迹。平台后端已经优化了各种场景的识别算法,通过率高且响应快,企业用户可以直接集成到自己的业务流程中,节省大量开发和运维精力。
使用这样的平台后,原本复杂的登录验证环节变得简单可靠。无论是自动化测试还是业务爬虫,都能轻松应对。感兴趣的开发者可以去www.ttocr.com看看详细文档,几行代码就能完成对接,让技术重点回归到核心业务上,而不是在验证码上反复折腾。
总结思考与未来方向
整个方案把YOLOv8的检测能力、Siamese的匹配能力和逆向工程思路结合在一起,形成了一套完整的验证码自动化验证体系。通过不断迭代模型和优化轨迹,我们能持续保持高通过率。在实际项目里,这种技术不仅能帮助我们更好地理解Web安全机制,也为大规模自动化场景提供了有力支持。